 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Adaptive Training using Model Agnostic Meta-Learning
Paper and Code
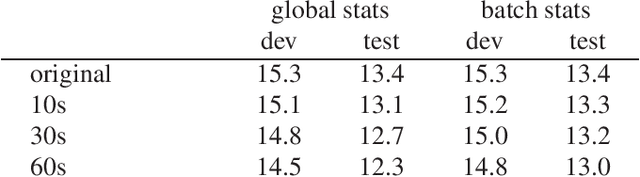


Speaker adaptive training (SAT) of neural network acoustic models learns models in a way that makes them more suitable for adaptation to test conditions. Conventionally, model-based speaker adaptive training is performed by having a set of speaker dependent parameters that are jointly optimised with speaker independent parameters in order to remove speaker variation. However, this does not scale well if all neural network weights are to be adapted to the speaker. In this paper we formulate speaker adaptive training as a meta-learning task, in which an adaptation process using gradient descent is encoded directly into the training of the model. We compare our approach with test-only adaptation of a standard baseline model and a SAT-LHUC model with a learned speaker adaptation schedule and demonstrate that the meta-learning approach achieves comparable results.