 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMyVoice: Arabic Speech Resource Collaboration Platform
Jul 23, 2023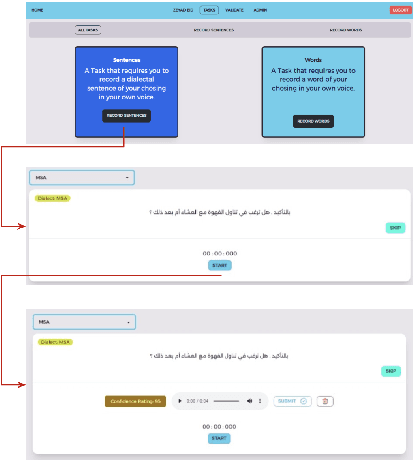
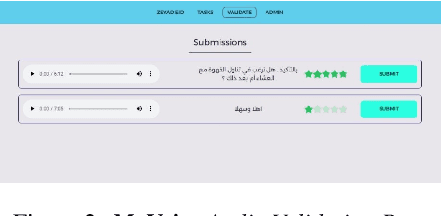
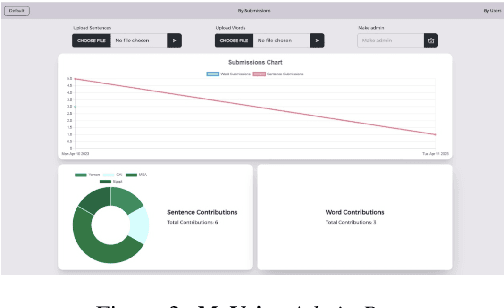
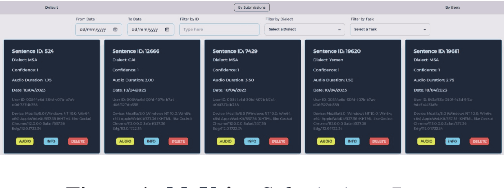
We introduce MyVoice, a crowdsourcing platform designed to collect Arabic speech to enhance dialectal speech technologies. This platform offers an opportunity to design large dialectal speech datasets; and makes them publicly available. MyVoice allows contributors to select city/country-level fine-grained dialect and record the displayed utterances. Users can switch roles between contributors and annotators. The platform incorporates a quality assurance system that filters out low-quality and spurious recordings before sending them for validation. During the validation phase, contributors can assess the quality of recordings, annotate them, and provide feedback which is then reviewed by administrators. Furthermore, the platform offers flexibility to admin roles to add new data or tasks beyond dialectal speech and word collection, which are displayed to contributors. Thus, enabling collaborative efforts in gathering diverse and large Arabic speech data.
Benchmarking Arabic AI with Large Language Models
May 24, 2023With large Foundation Models (FMs), language technologies (AI in general) are entering a new paradigm: eliminating the need for developing large-scale task-specific datasets and supporting a variety of tasks through set-ups ranging from zero-shot to few-shot learning. However, understanding FMs capabilities requires a systematic benchmarking effort by comparing FMs performance with the state-of-the-art (SOTA) task-specific models. With that goal, past work focused on the English language and included a few efforts with multiple languages. Our study contributes to ongoing research by evaluating FMs performance for standard Arabic NLP and Speech processing, including a range of tasks from sequence tagging to content classification across diverse domains. We start with zero-shot learning using GPT-3.5-turbo, Whisper, and USM, addressing 33 unique tasks using 59 publicly available datasets resulting in 96 test setups. For a few tasks, FMs performs on par or exceeds the performance of the SOTA models but for the majority it under-performs. Given the importance of prompt for the FMs performance, we discuss our prompt strategies in detail and elaborate on our findings. Our future work on Arabic AI will explore few-shot prompting, expand the range of tasks, and investigate additional open-source models.