 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSapiens: A Foundation Model for Social Behavior Processing via Heterogeneity-Aware Relative Policy Optimization
Feb 11, 2026To develop socially intelligent AI, existing approaches typically model human behavioral dimensions (e.g., affective, cognitive, or social attributes) in isolation. Although useful, task-specific modeling often increases training costs and limits generalization across behavioral settings. Recent reasoning RL methods facilitate training a single unified model across multiple behavioral tasks, but do not explicitly address learning across different heterogeneous behavioral data. To address this gap, we introduce Heterogeneity-Aware Relative Policy Optimization (HARPO), an RL method that balances leaning across heterogeneous tasks and samples. This is achieved by modulating advantages to ensure that no single task or sample carries disproportionate influence during policy optimization. Using HARPO, we develop and release Omnisapiens-7B 2.0, a foundation model for social behavior processing. Relative to existing behavioral foundation models, Omnisapiens-7B 2.0 achieves the strongest performance across behavioral tasks, with gains of up to +16.85% and +9.37% on multitask and held-out settings respectively, while producing more explicit and robust reasoning traces. We also validate HARPO against recent RL methods, where it achieves the most consistently strong performance across behavioral tasks.
There Is More to Refusal in Large Language Models than a Single Direction
Feb 02, 2026Prior work argues that refusal in large language models is mediated by a single activation-space direction, enabling effective steering and ablation. We show that this account is incomplete. Across eleven categories of refusal and non-compliance, including safety, incomplete or unsupported requests, anthropomorphization, and over-refusal, we find that these refusal behaviors correspond to geometrically distinct directions in activation space. Yet despite this diversity, linear steering along any refusal-related direction produces nearly identical refusal to over-refusal trade-offs, acting as a shared one-dimensional control knob. The primary effect of different directions is not whether the model refuses, but how it refuses.
Improving Language Models Trained with Translated Data via Continual Pre-Training and Dictionary Learning Analysis
May 23, 2024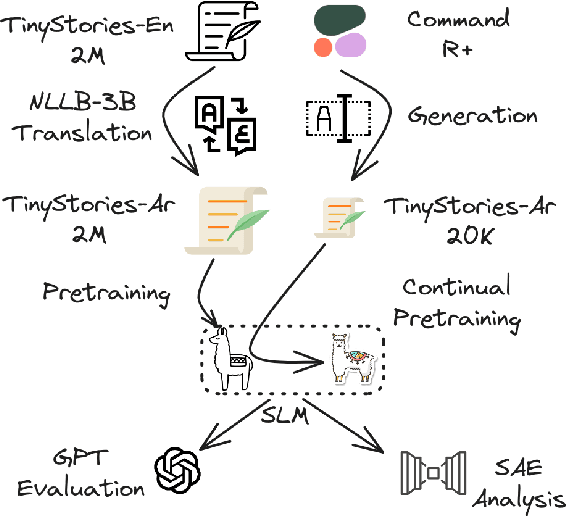
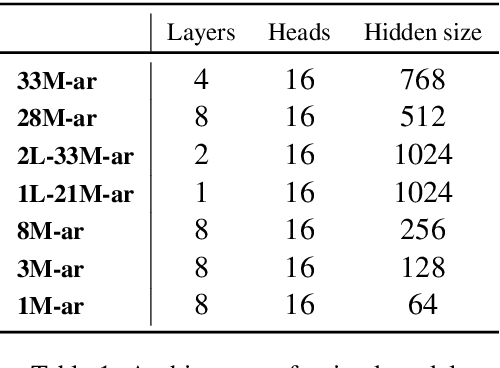
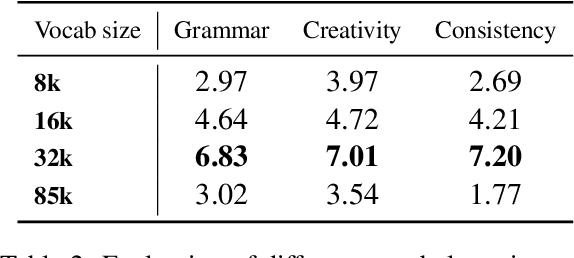
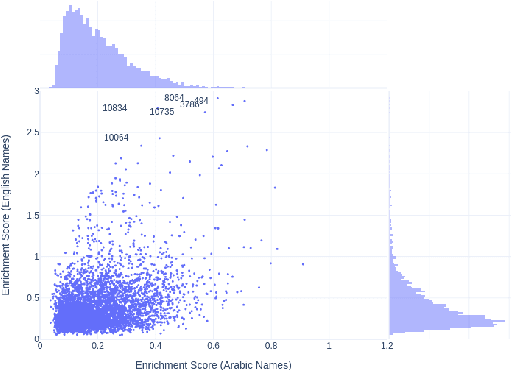
Training LLMs in low resources languages usually utilizes data augmentation with machine translation (MT) from English language. However, translation brings a number of challenges: there are large costs attached to translating and curating huge amounts of content with high-end machine translation solutions, the translated content carries over cultural biases, and if the translation is not faithful and accurate, the quality of the data degrades causing issues in the trained model. In this work we investigate the role of translation and synthetic data in training language models. We translate TinyStories, a dataset of 2.2M short stories for 3-4 year old children, from English to Arabic using the free NLLB-3B MT model. We train a number of story generation models of sizes 1M-33M parameters using this data. We identify a number of quality and task-specific issues in the resulting models. To rectify these issues, we further pre-train the models with a small dataset of synthesized high-quality stories, representing 1\% of the original training data, using a capable LLM in Arabic. We show using GPT-4 as a judge and dictionary learning analysis from mechanistic interpretability that the suggested approach is a practical means to resolve some of the translation pitfalls. We illustrate the improvement through case studies of linguistic issues and cultural bias.
Continual Imitation Learning for Prosthetic Limbs
May 02, 2024



Lower limb amputations and neuromuscular impairments severely restrict mobility, necessitating advancements beyond conventional prosthetics. Motorized bionic limbs offer promise, but their utility depends on mimicking the evolving synergy of human movement in various settings. In this context, we present a novel model for bionic prostheses' application that leverages camera-based motion capture and wearable sensor data, to learn the synergistic coupling of the lower limbs during human locomotion, empowering it to infer the kinematic behavior of a missing lower limb across varied tasks, such as climbing inclines and stairs. We propose a model that can multitask, adapt continually, anticipate movements, and refine. The core of our method lies in an approach which we call -- multitask prospective rehearsal -- that anticipates and synthesizes future movements based on the previous prediction and employs a corrective mechanism for subsequent predictions. We design an evolving architecture that merges lightweight, task-specific modules on a shared backbone, ensuring both specificity and scalability. We empirically validate our model against various baselines using real-world human gait datasets, including experiments with transtibial amputees, which encompass a broad spectrum of locomotion tasks. The results show that our approach consistently outperforms baseline models, particularly under scenarios affected by distributional shifts, adversarial perturbations, and noise.
Analyzing Multilingual Competency of LLMs in Multi-Turn Instruction Following: A Case Study of Arabic
Oct 23, 2023



While significant progress has been made in benchmarking Large Language Models (LLMs) across various tasks, there is a lack of comprehensive evaluation of their abilities in responding to multi-turn instructions in less-commonly tested languages like Arabic. Our paper offers a detailed examination of the proficiency of open LLMs in such scenarios in Arabic. Utilizing a customized Arabic translation of the MT-Bench benchmark suite, we employ GPT-4 as a uniform evaluator for both English and Arabic queries to assess and compare the performance of the LLMs on various open-ended tasks. Our findings reveal variations in model responses on different task categories, e.g., logic vs. literacy, when instructed in English or Arabic. We find that fine-tuned base models using multilingual and multi-turn datasets could be competitive to models trained from scratch on multilingual data. Finally, we hypothesize that an ensemble of small, open LLMs could perform competitively to proprietary LLMs on the benchmark.
LLMeBench: A Flexible Framework for Accelerating LLMs Benchmarking
Aug 09, 2023


The recent development and success of Large Language Models (LLMs) necessitate an evaluation of their performance across diverse NLP tasks in different languages. Although several frameworks have been developed and made publicly available, their customization capabilities for specific tasks and datasets are often complex for different users. In this study, we introduce the LLMeBench framework. Initially developed to evaluate Arabic NLP tasks using OpenAI's GPT and BLOOM models; it can be seamlessly customized for any NLP task and model, regardless of language. The framework also features zero- and few-shot learning settings. A new custom dataset can be added in less than 10 minutes, and users can use their own model API keys to evaluate the task at hand. The developed framework has been already tested on 31 unique NLP tasks using 53 publicly available datasets within 90 experimental setups, involving approximately 296K data points. We plan to open-source the framework for the community (https://github.com/qcri/LLMeBench/). A video demonstrating the framework is available online (https://youtu.be/FkQn4UjYA0s).
Benchmarking Arabic AI with Large Language Models
May 24, 2023With large Foundation Models (FMs), language technologies (AI in general) are entering a new paradigm: eliminating the need for developing large-scale task-specific datasets and supporting a variety of tasks through set-ups ranging from zero-shot to few-shot learning. However, understanding FMs capabilities requires a systematic benchmarking effort by comparing FMs performance with the state-of-the-art (SOTA) task-specific models. With that goal, past work focused on the English language and included a few efforts with multiple languages. Our study contributes to ongoing research by evaluating FMs performance for standard Arabic NLP and Speech processing, including a range of tasks from sequence tagging to content classification across diverse domains. We start with zero-shot learning using GPT-3.5-turbo, Whisper, and USM, addressing 33 unique tasks using 59 publicly available datasets resulting in 96 test setups. For a few tasks, FMs performs on par or exceeds the performance of the SOTA models but for the majority it under-performs. Given the importance of prompt for the FMs performance, we discuss our prompt strategies in detail and elaborate on our findings. Our future work on Arabic AI will explore few-shot prompting, expand the range of tasks, and investigate additional open-source models.
Multi-Modal Perceiver Language Model for Outcome Prediction in Emergency Department
Apr 03, 2023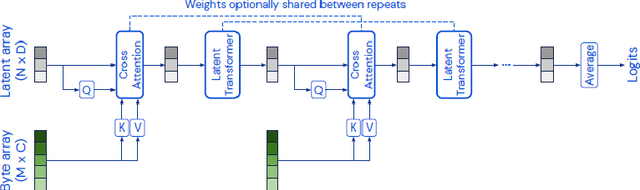

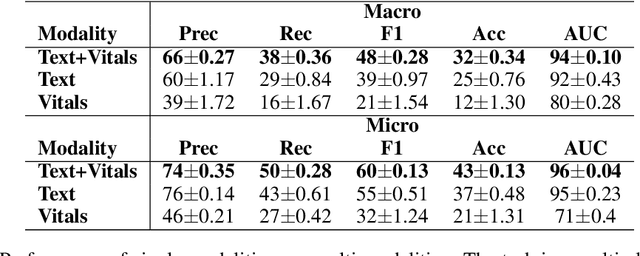
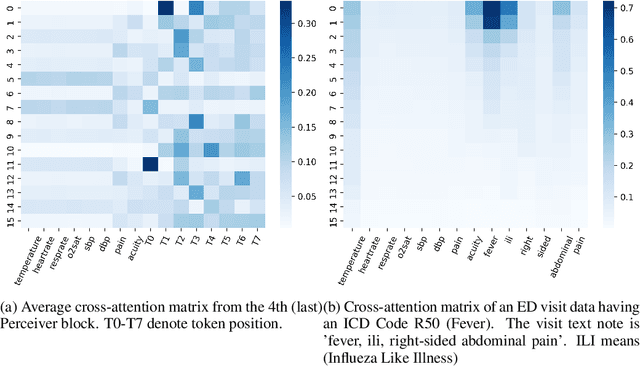
Language modeling have shown impressive progress in generating compelling text with good accuracy and high semantic coherence. An interesting research direction is to augment these powerful models for specific applications using contextual information. In this work, we explore multi-modal language modeling for healthcare applications. We are interested in outcome prediction and patient triage in hospital emergency department based on text information in chief complaints and vital signs recorded at triage. We adapt Perceiver - a modality-agnostic transformer-based model that has shown promising results in several applications. Since vital-sign modality is represented in tabular format, we modified Perceiver position encoding to ensure permutation invariance. We evaluated the multi-modal language model for the task of diagnosis code prediction using MIMIC-IV ED dataset on 120K visits. In the experimental analysis, we show that mutli-modality improves the prediction performance compared with models trained solely on text or vital signs. We identified disease categories for which multi-modality leads to performance improvement and show that for these categories, vital signs have added predictive power. By analyzing the cross-attention layer, we show how multi-modality contributes to model predictions. This work gives interesting insights on the development of multi-modal language models for healthcare applications.
Learning a Shared Model for Motorized Prosthetic Joints to Predict Ankle-Joint Motion
Nov 14, 2021
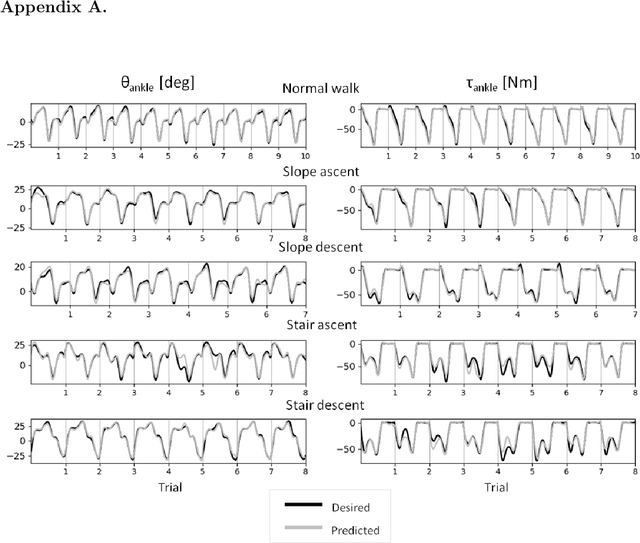
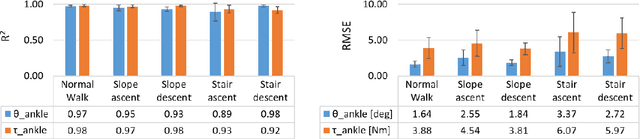
Control strategies for active prostheses or orthoses use sensor inputs to recognize the user's locomotive intention and generate corresponding control commands for producing the desired locomotion. In this paper, we propose a learning-based shared model for predicting ankle-joint motion for different locomotion modes like level-ground walking, stair ascent, stair descent, slope ascent, and slope descent without the need to classify between them. Features extracted from hip and knee joint angular motion are used to continuously predict the ankle angles and moments using a Feed-Forward Neural Network-based shared model. We show that the shared model is adequate for predicting the ankle angles and moments for different locomotion modes without explicitly classifying between the modes. The proposed strategy shows the potential for devising a high-level controller for an intelligent prosthetic ankle that can adapt to different locomotion modes.
Fairness in TabNet Model by Disentangled Representation for the Prediction of Hospital No-Show
Mar 06, 2021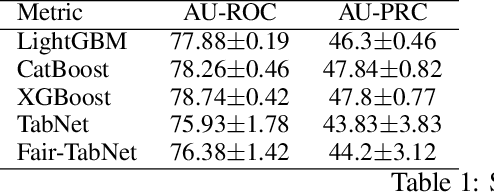
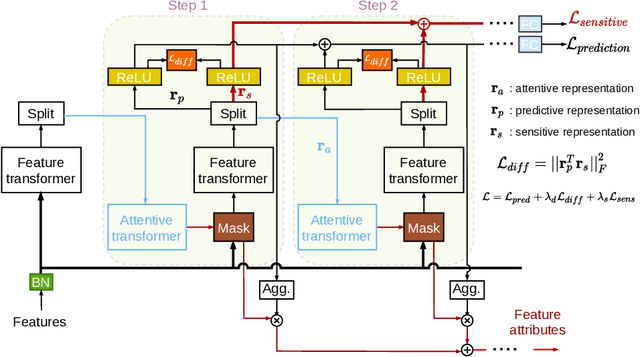

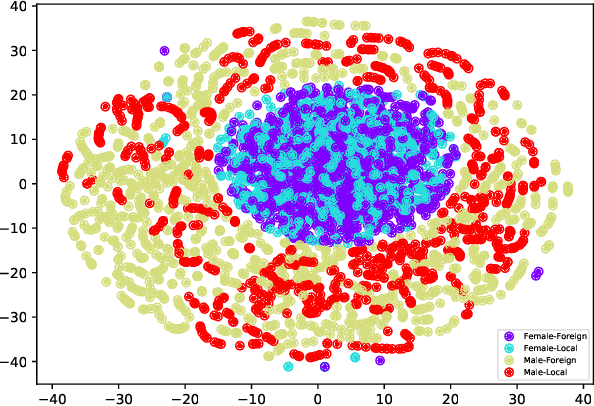
Patient no-shows is a major burden for health centers leading to loss of revenue, increased waiting time and deteriorated health outcome. Developing machine learning (ML) models for the prediction of no -shows could help addressing this important issue. It is crucial to consider fair ML models for no-show prediction in order to ensure equality of opportunity in accessing healthcare services. In this wo rk, we are interested in developing deep learning models for no-show prediction based on tabular data while ensuring fairness properties. Our baseline model, TabNet, uses on attentive feature transforme rs and has shown promising results for tabular data. We propose Fair-TabNet based on representation learning that disentangles predictive from sensitive components. The model is trained to jointly min imize loss functions on no-shows and sensitive variables while ensuring that the sensitive and prediction representations are orthogonal. In the experimental analysis, we used a hospital dataset of 210, 000 appointments collected in 2019. Our preliminary results show that the proposed Fair-TabNet improves the predictive, fairness performance and convergence speed over TabNet for the task of appointment no-show prediction. The comparison with the state-of-the art models for tabular data shows promising results and could be further improved by a better tuning of hyper-parameters.