 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Perceiver Language Model for Outcome Prediction in Emergency Department
Apr 03, 2023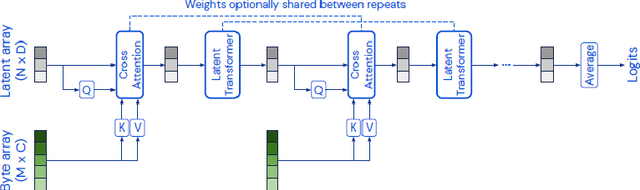

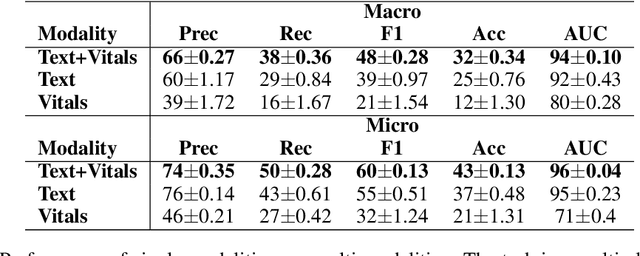
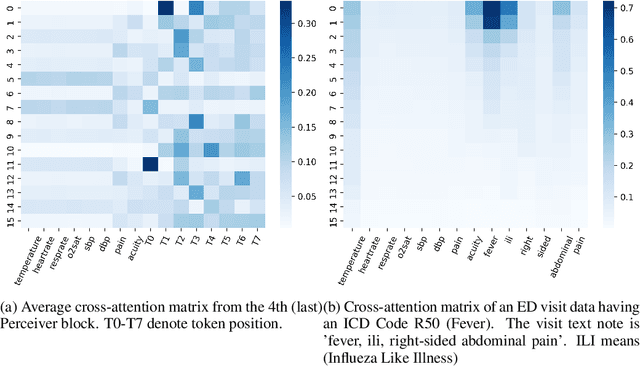
Language modeling have shown impressive progress in generating compelling text with good accuracy and high semantic coherence. An interesting research direction is to augment these powerful models for specific applications using contextual information. In this work, we explore multi-modal language modeling for healthcare applications. We are interested in outcome prediction and patient triage in hospital emergency department based on text information in chief complaints and vital signs recorded at triage. We adapt Perceiver - a modality-agnostic transformer-based model that has shown promising results in several applications. Since vital-sign modality is represented in tabular format, we modified Perceiver position encoding to ensure permutation invariance. We evaluated the multi-modal language model for the task of diagnosis code prediction using MIMIC-IV ED dataset on 120K visits. In the experimental analysis, we show that mutli-modality improves the prediction performance compared with models trained solely on text or vital signs. We identified disease categories for which multi-modality leads to performance improvement and show that for these categories, vital signs have added predictive power. By analyzing the cross-attention layer, we show how multi-modality contributes to model predictions. This work gives interesting insights on the development of multi-modal language models for healthcare applications.
Fairness in TabNet Model by Disentangled Representation for the Prediction of Hospital No-Show
Mar 06, 2021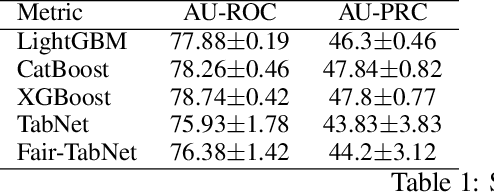
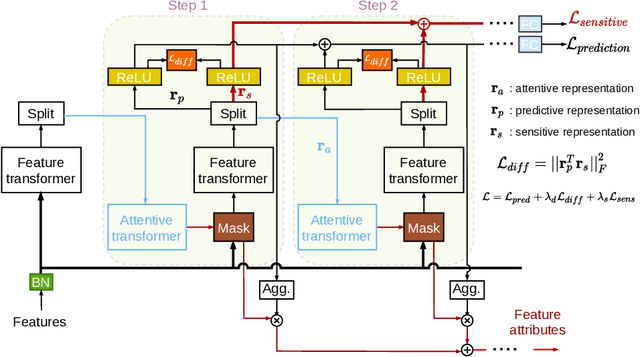

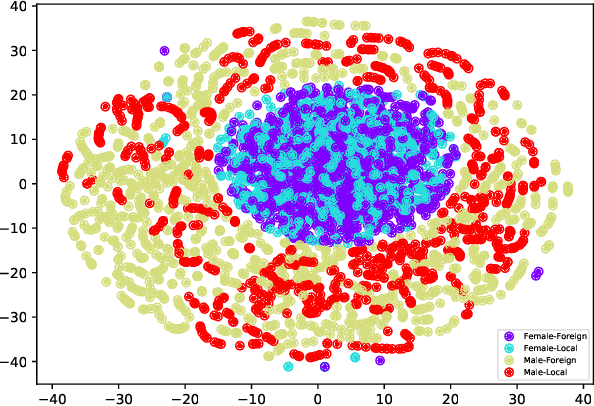
Patient no-shows is a major burden for health centers leading to loss of revenue, increased waiting time and deteriorated health outcome. Developing machine learning (ML) models for the prediction of no -shows could help addressing this important issue. It is crucial to consider fair ML models for no-show prediction in order to ensure equality of opportunity in accessing healthcare services. In this wo rk, we are interested in developing deep learning models for no-show prediction based on tabular data while ensuring fairness properties. Our baseline model, TabNet, uses on attentive feature transforme rs and has shown promising results for tabular data. We propose Fair-TabNet based on representation learning that disentangles predictive from sensitive components. The model is trained to jointly min imize loss functions on no-shows and sensitive variables while ensuring that the sensitive and prediction representations are orthogonal. In the experimental analysis, we used a hospital dataset of 210, 000 appointments collected in 2019. Our preliminary results show that the proposed Fair-TabNet improves the predictive, fairness performance and convergence speed over TabNet for the task of appointment no-show prediction. The comparison with the state-of-the art models for tabular data shows promising results and could be further improved by a better tuning of hyper-parameters.
Federated Uncertainty-Aware Learning for Distributed Hospital EHR Data
Oct 27, 2019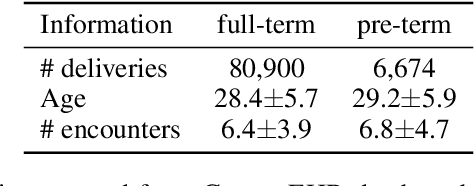
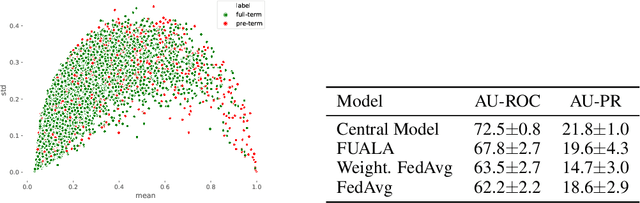

Recent works have shown that applying Machine Learning to Electronic Health Records (EHR) can strongly accelerate precision medicine. This requires developing models based on diverse EHR sources. Federated Learning (FL) has enabled predictive modeling using distributed training which lifted the need of sharing data and compromising privacy. Since models are distributed in FL, it is attractive to devise ensembles of Deep Neural Networks that also assess model uncertainty. We propose a new FL model called Federated Uncertainty-Aware Learning Algorithm (FUALA) that improves on Federated Averaging (FedAvg) in the context of EHR. FUALA embeds uncertainty information in two ways: It reduces the contribution of models with high uncertainty in the aggregated model. It also introduces model ensembling at prediction time by keeping the last layers of each hospital from the final round. In FUALA, the Federator (central node) sends at each round the average model to all hospitals as well as a randomly assigned hospital model update to estimate its generalization on that hospital own data. Each hospital sends back its model update as well a generalization estimation of the assigned model. At prediction time, the model outputs C predictions for each sample where C is the number of hospital models. The experimental analysis conducted on a cohort of 87K deliveries for the task of preterm-birth prediction showed that the proposed approach outperforms FedAvg when evaluated on out-of-distribution data. We illustrated how uncertainty could be measured using the proposed approach.
Alternating Loss Correction for Preterm-Birth Prediction from EHR Data with Noisy Labels
Nov 24, 2018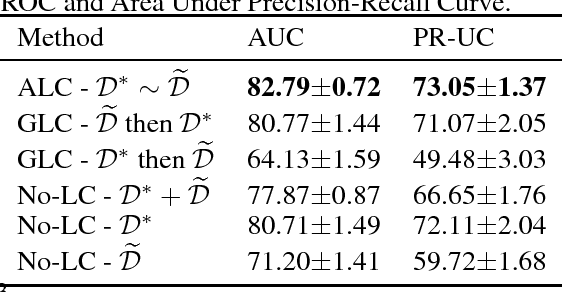
In this paper we are interested in the prediction of preterm birth based on diagnosis codes from longitudinal EHR. We formulate the prediction problem as a supervised classification with noisy labels. Our base classifier is a Recurrent Neural Network with an attention mechanism. We assume the availability of a data subset with both noisy and clean labels. For the cohort definition, most of the diagnosis codes on mothers' records related to pregnancy are ambiguous for the definition of full-term and preterm classes. On the other hand, diagnosis codes on babies' records provide fine-grained information on prematurity. Due to data de-identification, the links between mothers and babies are not available. We developed a heuristic based on admission and discharge times to match babies to their mothers and hence enrich mothers' records with additional information on delivery status. The obtained additional dataset from the matching heuristic has noisy labels and was used to leverage the training of the deep learning model. We propose an Alternating Loss Correction (ALC) method to train deep models with both clean and noisy labels. First, the label corruption matrix is estimated using the data subset with both noisy and clean labels. Then it is used in the model as a dense output layer to correct for the label noise. The network is alternately trained on epochs with the clean dataset with a simple cross-entropy loss and on next epoch with the noisy dataset and a loss corrected with the estimated corruption matrix. The experiments for the prediction of preterm birth at 90 days before delivery showed an improvement in performance compared with baseline and state of-the-art methods.
Genetic approach for arabic part of speech tagging
Jul 11, 2013
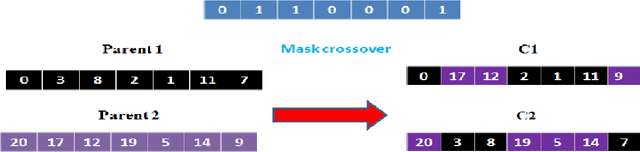
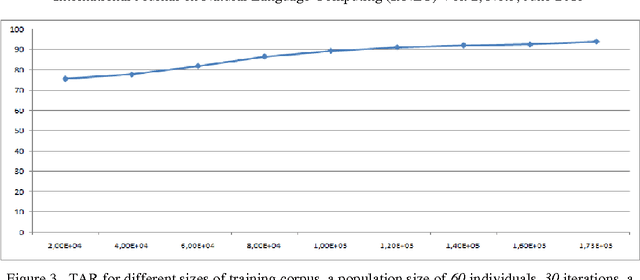
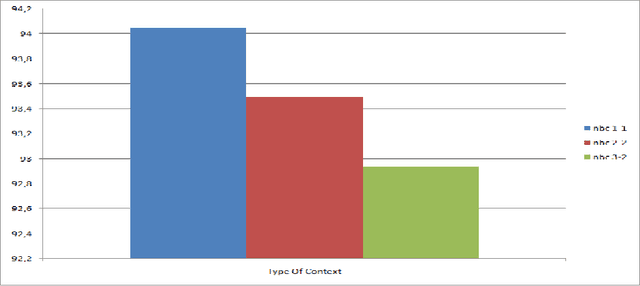
With the growing number of textual resources available, the ability to understand them becomes critical. An essential first step in understanding these sources is the ability to identify the part of speech in each sentence. Arabic is a morphologically rich language, wich presents a challenge for part of speech tagging. In this paper, our goal is to propose, improve and implement a part of speech tagger based on a genetic alorithm. The accuracy obtained with this method is comparable to that of other probabilistic approaches.
* 12 pages, 8 figures