Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenetic approach for arabic part of speech tagging
Paper and Code
Jul 11, 2013
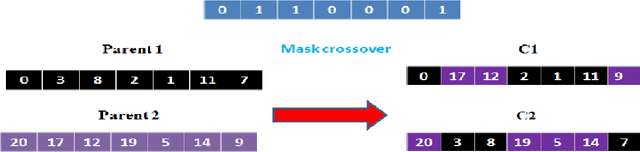
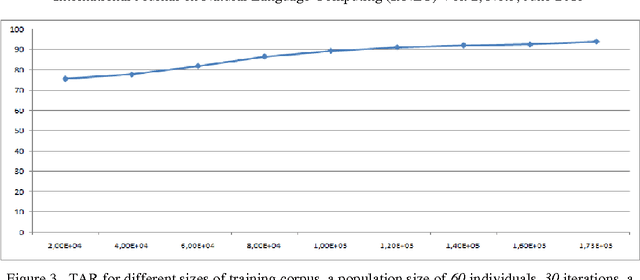
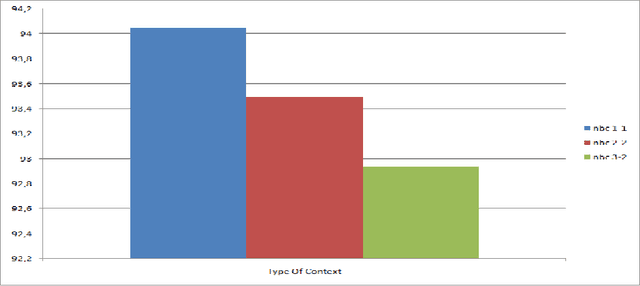
With the growing number of textual resources available, the ability to understand them becomes critical. An essential first step in understanding these sources is the ability to identify the part of speech in each sentence. Arabic is a morphologically rich language, wich presents a challenge for part of speech tagging. In this paper, our goal is to propose, improve and implement a part of speech tagger based on a genetic alorithm. The accuracy obtained with this method is comparable to that of other probabilistic approaches.
* International Journal on Natural Language Computing (IJNLC) Vol.
2, No.3, June 2013 * 12 pages, 8 figures
View paper on