 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Inductive Bias in Time-Series Pretraining: A Case Study in Learning Generalizable Representations for Clinical Time Series
May 27, 2026Clinical time-series learning is routinely constrained by small, heterogeneous cohorts and protocol drift, while its downstream use spans both classification (e.g., pathology diagnosis) and regression (e.g., temporal forecasting). These constraints make foundation-model pretraining appealing, but raises an important question of which inductive biases should the pretraining objective impose so that representations transfer across task types and subjects. We study this question in pathological gait analysis for spinal cord injury (SCI) via PathoFM, an encoder-centric transformer pretrained on multivariate gait windows with three complementary objectives: Local Completion (reconstruct contiguous masked spans to enforce local structure), Temporal Continuity (predict a masked mid-horizon continuation from an observed prefix to enforce smoothness and causal consistency), and Unsupervised In-Context Dynamics (support-query reconstruction conditioned on subject exemplar windows via attention). Empirically comparing objective families (grouping/contrastive, dynamics-based, and generative reconstruction), we find that dynamics-centric mixtures produce the most balanced transfer: grouping objectives favor discriminative margins but can degrade magnitude fidelity needed for continuous targets, whereas reconstruction-only objectives preserve waveform structure but may underperform on classification. Overall, combining local reconstruction with temporal continuity, and adding in-context conditioning when exemplar access is realistic, yields robust subject-generalizing representations.
An Addendum to NeBula: Towards Extending TEAM CoSTAR's Solution to Larger Scale Environments
Apr 18, 2025This paper presents an appendix to the original NeBula autonomy solution developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), participating in the DARPA Subterranean Challenge. Specifically, this paper presents extensions to NeBula's hardware, software, and algorithmic components that focus on increasing the range and scale of the exploration environment. From the algorithmic perspective, we discuss the following extensions to the original NeBula framework: (i) large-scale geometric and semantic environment mapping; (ii) an adaptive positioning system; (iii) probabilistic traversability analysis and local planning; (iv) large-scale POMDP-based global motion planning and exploration behavior; (v) large-scale networking and decentralized reasoning; (vi) communication-aware mission planning; and (vii) multi-modal ground-aerial exploration solutions. We demonstrate the application and deployment of the presented systems and solutions in various large-scale underground environments, including limestone mine exploration scenarios as well as deployment in the DARPA Subterranean challenge.
Cross-Modal Diffusion for Biomechanical Dynamical Systems Through Local Manifold Alignment
Mar 15, 2025We present a mutually aligned diffusion framework for cross-modal biomechanical motion generation, guided by a dynamical systems perspective. By treating each modality, e.g., observed joint angles ($X$) and ground reaction forces ($Y$), as complementary observations of a shared underlying locomotor dynamical system, our method aligns latent representations at each diffusion step, so that one modality can help denoise and disambiguate the other. Our alignment approach is motivated by the fact that local time windows of $X$ and $Y$ represent the same phase of an underlying dynamical system, thereby benefiting from a shared latent manifold. We introduce a simple local latent manifold alignment (LLMA) strategy that incorporates first-order and second-order alignment within the latent space for robust cross-modal biomechanical generation without bells and whistles. Through experiments on multimodal human biomechanics data, we show that aligning local latent dynamics across modalities improves generation fidelity and yields better representations.
Redefining Robot Generalization Through Interactive Intelligence
Feb 09, 2025Recent advances in large-scale machine learning have produced high-capacity foundation models capable of adapting to a broad array of downstream tasks. While such models hold great promise for robotics, the prevailing paradigm still portrays robots as single, autonomous decision-makers, performing tasks like manipulation and navigation, with limited human involvement. However, a large class of real-world robotic systems, including wearable robotics (e.g., prostheses, orthoses, exoskeletons), teleoperation, and neural interfaces, are semiautonomous, and require ongoing interactive coordination with human partners, challenging single-agent assumptions. In this position paper, we argue that robot foundation models must evolve to an interactive multi-agent perspective in order to handle the complexities of real-time human-robot co-adaptation. We propose a generalizable, neuroscience-inspired architecture encompassing four modules: (1) a multimodal sensing module informed by sensorimotor integration principles, (2) an ad-hoc teamwork model reminiscent of joint-action frameworks in cognitive science, (3) a predictive world belief model grounded in internal model theories of motor control, and (4) a memory/feedback mechanism that echoes concepts of Hebbian and reinforcement-based plasticity. Although illustrated through the lens of cyborg systems, where wearable devices and human physiology are inseparably intertwined, the proposed framework is broadly applicable to robots operating in semi-autonomous or interactive contexts. By moving beyond single-agent designs, our position emphasizes how foundation models in robotics can achieve a more robust, personalized, and anticipatory level of performance.
Continual Imitation Learning for Prosthetic Limbs
May 02, 2024



Lower limb amputations and neuromuscular impairments severely restrict mobility, necessitating advancements beyond conventional prosthetics. Motorized bionic limbs offer promise, but their utility depends on mimicking the evolving synergy of human movement in various settings. In this context, we present a novel model for bionic prostheses' application that leverages camera-based motion capture and wearable sensor data, to learn the synergistic coupling of the lower limbs during human locomotion, empowering it to infer the kinematic behavior of a missing lower limb across varied tasks, such as climbing inclines and stairs. We propose a model that can multitask, adapt continually, anticipate movements, and refine. The core of our method lies in an approach which we call -- multitask prospective rehearsal -- that anticipates and synthesizes future movements based on the previous prediction and employs a corrective mechanism for subsequent predictions. We design an evolving architecture that merges lightweight, task-specific modules on a shared backbone, ensuring both specificity and scalability. We empirically validate our model against various baselines using real-world human gait datasets, including experiments with transtibial amputees, which encompass a broad spectrum of locomotion tasks. The results show that our approach consistently outperforms baseline models, particularly under scenarios affected by distributional shifts, adversarial perturbations, and noise.
Enhancing Joint Motion Prediction for Individuals with Limb Loss Through Model Reprogramming
Mar 12, 2024Mobility impairment caused by limb loss is a significant challenge faced by millions of individuals worldwide. The development of advanced assistive technologies, such as prosthetic devices, has the potential to greatly improve the quality of life for amputee patients. A critical component in the design of such technologies is the accurate prediction of reference joint motion for the missing limb. However, this task is hindered by the scarcity of joint motion data available for amputee patients, in contrast to the substantial quantity of data from able-bodied subjects. To overcome this, we leverage deep learning's reprogramming property to repurpose well-trained models for a new goal without altering the model parameters. With only data-level manipulation, we adapt models originally designed for able-bodied people to forecast joint motion in amputees. The findings in this study have significant implications for advancing assistive tech and amputee mobility.
Embracing Large Language and Multimodal Models for Prosthetic Technologies
Mar 11, 2024This article presents a vision for the future of prosthetic devices, leveraging the advancements in large language models (LLMs) and Large Multimodal Models (LMMs) to revolutionize the interaction between humans and assistive technologies. Unlike traditional prostheses, which rely on limited and predefined commands, this approach aims to develop intelligent prostheses that understand and respond to users' needs through natural language and multimodal inputs. The realization of this vision involves developing a control system capable of understanding and translating a wide array of natural language and multimodal inputs into actionable commands for prosthetic devices. This includes the creation of models that can extract and interpret features from both textual and multimodal data, ensuring devices not only follow user commands but also respond intelligently to the environment and user intent, thus marking a significant leap forward in prosthetic technology.
Computer Vision for Primate Behavior Analysis in the Wild
Jan 29, 2024Advances in computer vision as well as increasingly widespread video-based behavioral monitoring have great potential for transforming how we study animal cognition and behavior. However, there is still a fairly large gap between the exciting prospects and what can actually be achieved in practice today, especially in videos from the wild. With this perspective paper, we want to contribute towards closing this gap, by guiding behavioral scientists in what can be expected from current methods and steering computer vision researchers towards problems that are relevant to advance research in animal behavior. We start with a survey of the state-of-the-art methods for computer vision problems that are directly relevant to the video-based study of animal behavior, including object detection, multi-individual tracking, (inter)action recognition and individual identification. We then review methods for effort-efficient learning, which is one of the biggest challenges from a practical perspective. Finally, we close with an outlook into the future of the emerging field of computer vision for animal behavior, where we argue that the field should move fast beyond the common frame-by-frame processing and treat video as a first-class citizen.
STEP: Stochastic Traversability Evaluation and Planning for Risk-Aware Off-road Navigation; Results from the DARPA Subterranean Challenge
Mar 02, 2023
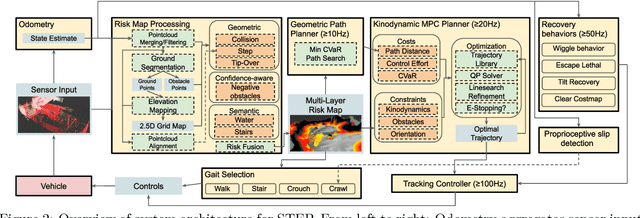


Although autonomy has gained widespread usage in structured and controlled environments, robotic autonomy in unknown and off-road terrain remains a difficult problem. Extreme, off-road, and unstructured environments such as undeveloped wilderness, caves, rubble, and other post-disaster sites pose unique and challenging problems for autonomous navigation. Based on our participation in the DARPA Subterranean Challenge, we propose an approach to improve autonomous traversal of robots in subterranean environments that are perceptually degraded and completely unknown through a traversability and planning framework called STEP (Stochastic Traversability Evaluation and Planning). We present 1) rapid uncertainty-aware mapping and traversability evaluation, 2) tail risk assessment using the Conditional Value-at-Risk (CVaR), 3) efficient risk and constraint-aware kinodynamic motion planning using sequential quadratic programming-based (SQP) model predictive control (MPC), 4) fast recovery behaviors to account for unexpected scenarios that may cause failure, and 5) risk-based gait adaptation for quadrupedal robots. We illustrate and validate extensive results from our experiments on wheeled and legged robotic platforms in field studies at the Valentine Cave, CA (cave environment), Kentucky Underground, KY (mine environment), and Louisville Mega Cavern, KY (final competition site for the DARPA Subterranean Challenge with tunnel, urban, and cave environments).
Self-Supervised Traversability Prediction by Learning to Reconstruct Safe Terrain
Aug 02, 2022
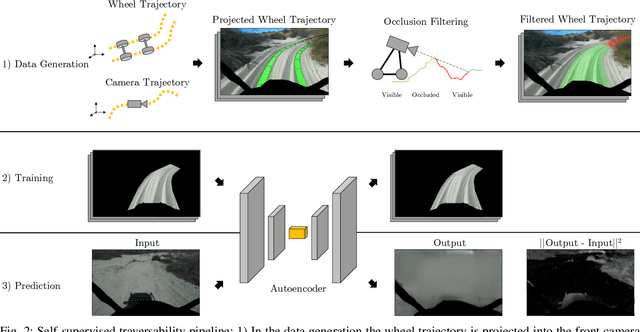


Navigating off-road with a fast autonomous vehicle depends on a robust perception system that differentiates traversable from non-traversable terrain. Typically, this depends on a semantic understanding which is based on supervised learning from images annotated by a human expert. This requires a significant investment in human time, assumes correct expert classification, and small details can lead to misclassification. To address these challenges, we propose a method for predicting high- and low-risk terrains from only past vehicle experience in a self-supervised fashion. First, we develop a tool that projects the vehicle trajectory into the front camera image. Second, occlusions in the 3D representation of the terrain are filtered out. Third, an autoencoder trained on masked vehicle trajectory regions identifies low- and high-risk terrains based on the reconstruction error. We evaluated our approach with two models and different bottleneck sizes with two different training and testing sites with a fourwheeled off-road vehicle. Comparison with two independent test sets of semantic labels from similar terrain as training sites demonstrates the ability to separate the ground as low-risk and the vegetation as high-risk with 81.1% and 85.1% accuracy.