 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEICAP: Deep Dive in Assessment and Enhancement of Large Language Models in Emotional Intelligence through Multi-Turn Conversations
Aug 08, 2025Emotional Intelligence (EI) is a critical yet underexplored dimension in the development of human-aligned LLMs. To address this gap, we introduce a unified, psychologically grounded four-layer taxonomy of EI tailored for large language models (LLMs), encompassing emotional tracking, cause inference, appraisal, and emotionally appropriate response generation. Building on this framework, we present EICAP-Bench, a novel MCQ style multi-turn benchmark designed to evaluate EI capabilities in open-source LLMs across diverse linguistic and cultural contexts. We evaluate six LLMs: LLaMA3 (8B), LLaMA3-Instruct, Gemma (9B), Gemma-Instruct, Qwen2.5 (7B), and Qwen2.5-Instruct on EmoCap-Bench, identifying Qwen2.5-Instruct as the strongest baseline. To assess the potential for enhancing EI capabilities, we fine-tune both Qwen2.5-Base and Qwen2.5-Instruct using LoRA adapters on UltraChat (UC), a large-scale, instruction-tuned dialogue dataset, in both English and Arabic. Our statistical analysis reveals that among the five EI layers, only the Appraisal layer shows significant improvement through UC-based fine-tuning. These findings highlight the limitations of existing pretraining and instruction-tuning paradigms in equipping LLMs with deeper emotional reasoning and underscore the need for targeted data and modeling strategies for comprehensive EI alignment.
Generative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions
Apr 27, 2025
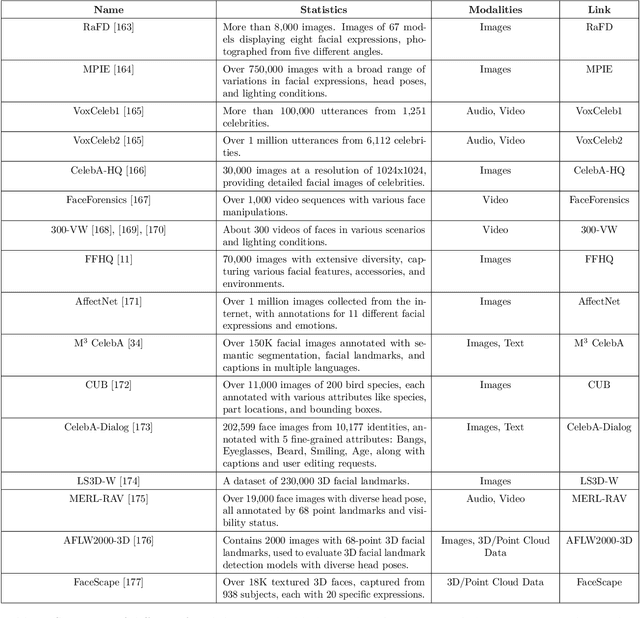
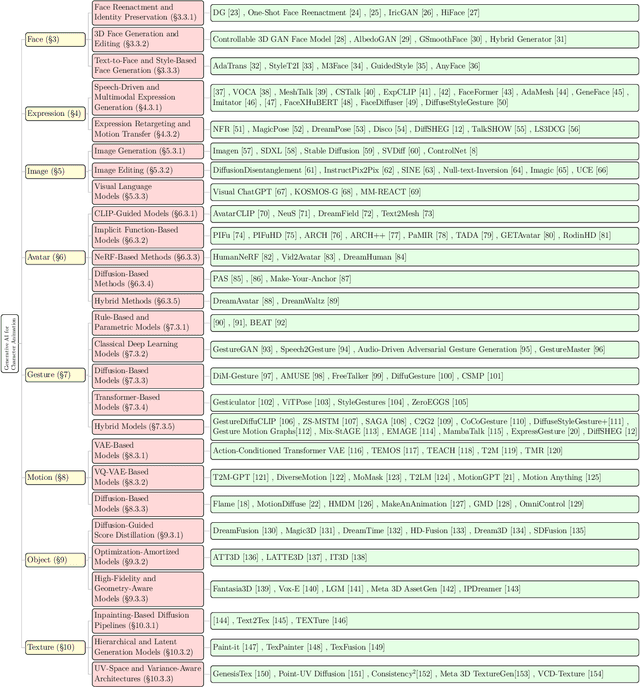
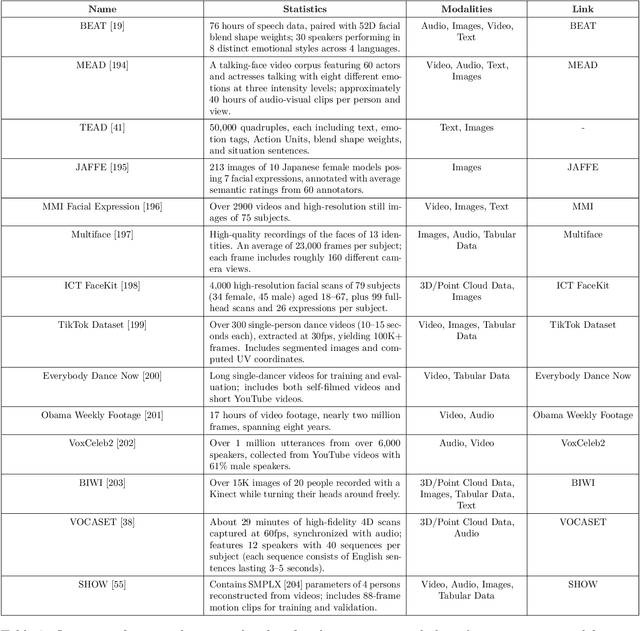
Generative AI is reshaping art, gaming, and most notably animation. Recent breakthroughs in foundation and diffusion models have reduced the time and cost of producing animated content. Characters are central animation components, involving motion, emotions, gestures, and facial expressions. The pace and breadth of advances in recent months make it difficult to maintain a coherent view of the field, motivating the need for an integrative review. Unlike earlier overviews that treat avatars, gestures, or facial animation in isolation, this survey offers a single, comprehensive perspective on all the main generative AI applications for character animation. We begin by examining the state-of-the-art in facial animation, expression rendering, image synthesis, avatar creation, gesture modeling, motion synthesis, object generation, and texture synthesis. We highlight leading research, practical deployments, commonly used datasets, and emerging trends for each area. To support newcomers, we also provide a comprehensive background section that introduces foundational models and evaluation metrics, equipping readers with the knowledge needed to enter the field. We discuss open challenges and map future research directions, providing a roadmap to advance AI-driven character-animation technologies. This survey is intended as a resource for researchers and developers entering the field of generative AI animation or adjacent fields. Resources are available at: https://github.com/llm-lab-org/Generative-AI-for-Character-Animation-Survey.
LLMeBench: A Flexible Framework for Accelerating LLMs Benchmarking
Aug 09, 2023


The recent development and success of Large Language Models (LLMs) necessitate an evaluation of their performance across diverse NLP tasks in different languages. Although several frameworks have been developed and made publicly available, their customization capabilities for specific tasks and datasets are often complex for different users. In this study, we introduce the LLMeBench framework. Initially developed to evaluate Arabic NLP tasks using OpenAI's GPT and BLOOM models; it can be seamlessly customized for any NLP task and model, regardless of language. The framework also features zero- and few-shot learning settings. A new custom dataset can be added in less than 10 minutes, and users can use their own model API keys to evaluate the task at hand. The developed framework has been already tested on 31 unique NLP tasks using 53 publicly available datasets within 90 experimental setups, involving approximately 296K data points. We plan to open-source the framework for the community (https://github.com/qcri/LLMeBench/). A video demonstrating the framework is available online (https://youtu.be/FkQn4UjYA0s).
Benchmarking Arabic AI with Large Language Models
May 24, 2023With large Foundation Models (FMs), language technologies (AI in general) are entering a new paradigm: eliminating the need for developing large-scale task-specific datasets and supporting a variety of tasks through set-ups ranging from zero-shot to few-shot learning. However, understanding FMs capabilities requires a systematic benchmarking effort by comparing FMs performance with the state-of-the-art (SOTA) task-specific models. With that goal, past work focused on the English language and included a few efforts with multiple languages. Our study contributes to ongoing research by evaluating FMs performance for standard Arabic NLP and Speech processing, including a range of tasks from sequence tagging to content classification across diverse domains. We start with zero-shot learning using GPT-3.5-turbo, Whisper, and USM, addressing 33 unique tasks using 59 publicly available datasets resulting in 96 test setups. For a few tasks, FMs performs on par or exceeds the performance of the SOTA models but for the majority it under-performs. Given the importance of prompt for the FMs performance, we discuss our prompt strategies in detail and elaborate on our findings. Our future work on Arabic AI will explore few-shot prompting, expand the range of tasks, and investigate additional open-source models.