 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions
Apr 27, 2025
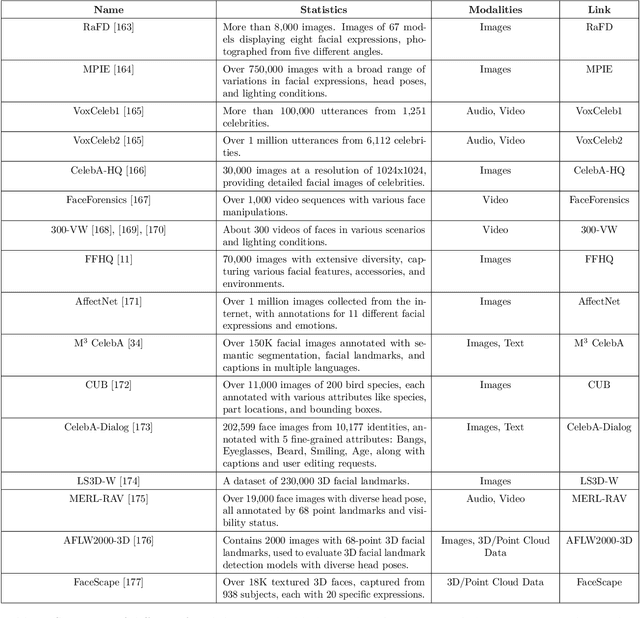
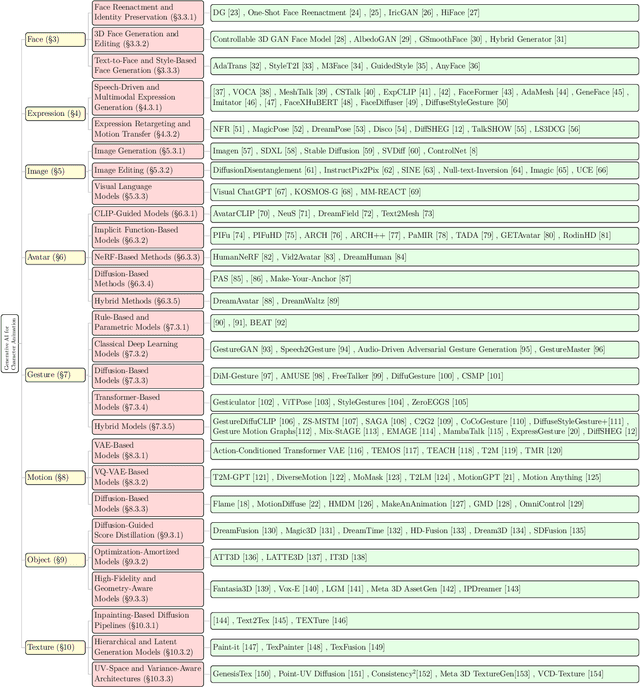
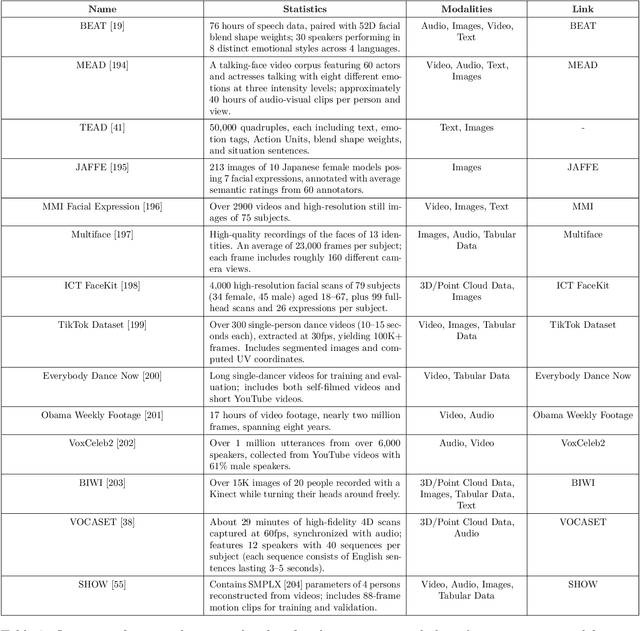
Generative AI is reshaping art, gaming, and most notably animation. Recent breakthroughs in foundation and diffusion models have reduced the time and cost of producing animated content. Characters are central animation components, involving motion, emotions, gestures, and facial expressions. The pace and breadth of advances in recent months make it difficult to maintain a coherent view of the field, motivating the need for an integrative review. Unlike earlier overviews that treat avatars, gestures, or facial animation in isolation, this survey offers a single, comprehensive perspective on all the main generative AI applications for character animation. We begin by examining the state-of-the-art in facial animation, expression rendering, image synthesis, avatar creation, gesture modeling, motion synthesis, object generation, and texture synthesis. We highlight leading research, practical deployments, commonly used datasets, and emerging trends for each area. To support newcomers, we also provide a comprehensive background section that introduces foundational models and evaluation metrics, equipping readers with the knowledge needed to enter the field. We discuss open challenges and map future research directions, providing a roadmap to advance AI-driven character-animation technologies. This survey is intended as a resource for researchers and developers entering the field of generative AI animation or adjacent fields. Resources are available at: https://github.com/llm-lab-org/Generative-AI-for-Character-Animation-Survey.
Detecting Bias and Enhancing Diagnostic Accuracy in Large Language Models for Healthcare
Oct 09, 2024Biased AI-generated medical advice and misdiagnoses can jeopardize patient safety, making the integrity of AI in healthcare more critical than ever. As Large Language Models (LLMs) take on a growing role in medical decision-making, addressing their biases and enhancing their accuracy is key to delivering safe, reliable care. This study addresses these challenges head-on by introducing new resources designed to promote ethical and precise AI in healthcare. We present two datasets: BiasMD, featuring 6,007 question-answer pairs crafted to evaluate and mitigate biases in health-related LLM outputs, and DiseaseMatcher, with 32,000 clinical question-answer pairs spanning 700 diseases, aimed at assessing symptom-based diagnostic accuracy. Using these datasets, we developed the EthiClinician, a fine-tuned model built on the ChatDoctor framework, which outperforms GPT-4 in both ethical reasoning and clinical judgment. By exposing and correcting hidden biases in existing models for healthcare, our work sets a new benchmark for safer, more reliable patient outcomes.
TuringQ: Benchmarking AI Comprehension in Theory of Computation
Oct 09, 2024We present TuringQ, the first benchmark designed to evaluate the reasoning capabilities of large language models (LLMs) in the theory of computation. TuringQ consists of 4,006 undergraduate and graduate-level question-answer pairs, categorized into four difficulty levels and covering seven core theoretical areas. We evaluate several open-source LLMs, as well as GPT-4, using Chain of Thought prompting and expert human assessment. Additionally, we propose an automated LLM-based evaluation system that demonstrates competitive accuracy when compared to human evaluation. Fine-tuning a Llama3-8B model on TuringQ shows measurable improvements in reasoning ability and out-of-domain tasks such as algebra. TuringQ serves as both a benchmark and a resource for enhancing LLM performance in complex computational reasoning tasks. Our analysis offers insights into LLM capabilities and advances in AI comprehension of theoretical computer science.
WSC+: Enhancing The Winograd Schema Challenge Using Tree-of-Experts
Jan 31, 2024The Winograd Schema Challenge (WSC) serves as a prominent benchmark for evaluating machine understanding. While Large Language Models (LLMs) excel at answering WSC questions, their ability to generate such questions remains less explored. In this work, we propose Tree-of-Experts (ToE), a novel prompting method which enhances the generation of WSC instances (50% valid cases vs. 10% in recent methods). Using this approach, we introduce WSC+, a novel dataset comprising 3,026 LLM-generated sentences. Notably, we extend the WSC framework by incorporating new 'ambiguous' and 'offensive' categories, providing a deeper insight into model overconfidence and bias. Our analysis reveals nuances in generation-evaluation consistency, suggesting that LLMs may not always outperform in evaluating their own generated questions when compared to those crafted by other models. On WSC+, GPT-4, the top-performing LLM, achieves an accuracy of 68.7%, significantly below the human benchmark of 95.1%.