 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Prompt Localization for Agent-as-a-Judge: Language and Backbone Sensitivity in Requirement-Level Evaluation
Apr 06, 2026Evaluation language is typically treated as a fixed English default in agentic code benchmarks, yet we show that changing the judge's language can invert backbone rankings. We localize the Agent-as-a-Judge prompt stack to five typologically diverse languages (English, Arabic, Turkish, Chinese, Hindi) and evaluate 55 DevAI development tasks across three developer-agent frameworks and six judge backbones, totaling 4950 judge runs. The central finding is that backbone and language interact: GPT-4o achieves the highest satisfaction in English (44.72\%), while Gemini leads in Arabic (51.72\%, $p<0.001$ vs.\ GPT-4o) and Hindi (53.22\%). No single backbone dominates across all languages, and inter-backbone agreement on individual requirement judgments is modest (Fleiss' $κ\leq 0.231$). A controlled ablation further shows that localizing judge-side instructions, not just benchmark content, can be decisive: Hindi satisfaction drops from 42.8\% to 23.2\% under partial localization. These results indicate that language should be treated as an explicit evaluation variable in agentic benchmarks. Full requirement-level judgments and runtime statistics are released for reproducibility.
4D Synchronized Fields: Motion-Language Gaussian Splatting for Temporal Scene Understanding
Mar 15, 2026Current 4D representations decouple geometry, motion, and semantics: reconstruction methods discard interpretable motion structure; language-grounded methods attach semantics after motion is learned, blind to how objects move; and motion-aware methods encode dynamics as opaque per-point residuals without object-level organization. We propose 4D Synchronized Fields, a 4D Gaussian representation that learns object-factored motion in-loop during reconstruction and synchronizes language to the resulting kinematics through a per-object conditioned field. Each Gaussian trajectory is decomposed into shared object motion plus an implicit residual, and a kinematic-conditioned ridge map predicts temporal semantic variation, yielding a single representation in which reconstruction, motion, and semantics are structurally coupled and enabling open-vocabulary temporal queries that retrieve both objects and moments. On HyperNeRF, 4D Synchronized Fields achieves 28.52 dB mean PSNR, the highest among all language-grounded and motion-aware baselines, within 1.5 dB of reconstruction-only methods. On targeted temporal-state retrieval, the kinematic-conditioned field attains 0.884 mean accuracy, 0.815 mean vIoU, and 0.733 mean tIoU, surpassing 4D LangSplat (0.620, 0.433, and 0.439 respectively) and LangSplat (0.415, 0.304, and 0.262). Ablation confirms that kinematic conditioning is the primary driver, accounting for +0.45 tIoU over a static-embedding-only baseline. 4D Synchronized Fields is the only method that jointly exposes interpretable motion primitives and temporally grounded language fields from a single trained representation. Code will be released.
Knowing When Not to Answer: Abstention-Aware Scientific Reasoning
Feb 15, 2026Large language models are increasingly used to answer and verify scientific claims, yet existing evaluations typically assume that a model must always produce a definitive answer. In scientific settings, however, unsupported or uncertain conclusions can be more harmful than abstaining. We study this problem through an abstention-aware verification framework that decomposes scientific claims into minimal conditions, audits each condition against available evidence using natural language inference (NLI), and selectively decides whether to support, refute, or abstain. We evaluate this framework across two complementary scientific benchmarks: SciFact and PubMedQA, covering both closed-book and open-domain evidence settings. Experiments are conducted with six diverse language models, including encoder-decoder, open-weight chat models, and proprietary APIs. Across all benchmarks and models, we observe that raw accuracy varies only modestly across architectures, while abstention plays a critical role in controlling error. In particular, confidence-based abstention substantially reduces risk at moderate coverage levels, even when absolute accuracy improvements are limited. Our results suggest that in scientific reasoning tasks, the primary challenge is not selecting a single best model, but rather determining when available evidence is sufficient to justify an answer. This work highlights abstention-aware evaluation as a practical and model-agnostic lens for assessing scientific reliability, and provides a unified experimental basis for future work on selective reasoning in scientific domains. Code is available at https://github.com/sabdaljalil2000/ai4science .
Halluverse-M^3: A multitask multilingual benchmark for hallucination in LLMs
Feb 06, 2026Hallucinations in large language models remain a persistent challenge, particularly in multilingual and generative settings where factual consistency is difficult to maintain. While recent models show strong performance on English-centric benchmarks, their behavior across languages, tasks, and hallucination types is not yet well understood. In this work, we introduce Halluverse-M^3, a dataset designed to enable systematic analysis of hallucinations across multiple languages, multiple generation tasks, and multiple hallucination categories. Halluverse-M^3 covers four languages, English, Arabic, Hindi, and Turkish, and supports two generation tasks: question answering and dialogue summarization. The dataset explicitly distinguishes between entity-level, relation-level, and sentence-level hallucinations. Hallucinated outputs are constructed through a controlled editing process and validated by human annotators, ensuring clear alignment between original content and hallucinated generations. Using this dataset, we evaluate a diverse set of contemporary open-source and proprietary language models on fine-grained hallucination detection. Our results show that question answering is consistently easier than dialogue summarization, while sentence-level hallucinations remain challenging even for the strongest models. Performance is highest in English and degrades in lower-resource languages, with Hindi exhibiting the lowest detection accuracy. Overall, Halluverse-M^3 provides a realistic and challenging benchmark for studying hallucinations in multilingual, multi-task settings. We release the dataset to support future research on hallucination detection and mitigation\footnote{https://huggingface.co/datasets/sabdalja/HalluVerse-M3}.
Evaluating Multilingual and Code-Switched Alignment in LLMs via Synthetic Natural Language Inference
Aug 20, 2025Large language models (LLMs) are increasingly applied in multilingual contexts, yet their capacity for consistent, logically grounded alignment across languages remains underexplored. We present a controlled evaluation framework for multilingual natural language inference (NLI) that generates synthetic, logic-based premise-hypothesis pairs and translates them into a typologically diverse set of languages. This design enables precise control over semantic relations and allows testing in both monolingual and mixed-language (code-switched) conditions. Surprisingly, code-switching does not degrade, and can even improve, performance, suggesting that translation-induced lexical variation may serve as a regularization signal. We validate semantic preservation through embedding-based similarity analyses and cross-lingual alignment visualizations, confirming the fidelity of translated pairs. Our findings expose both the potential and the brittleness of current LLM cross-lingual reasoning, and identify code-switching as a promising lever for improving multilingual robustness. Code available at: https://github.com/KurbanIntelligenceLab/nli-stress-testing
Theorem-of-Thought: A Multi-Agent Framework for Abductive, Deductive, and Inductive Reasoning in Language Models
Jun 08, 2025Large language models (LLMs) have shown strong performance across natural language reasoning tasks, yet their reasoning processes remain brittle and difficult to interpret. Prompting techniques like Chain-of-Thought (CoT) enhance reliability by eliciting intermediate reasoning steps or aggregating multiple outputs. However, they lack mechanisms for enforcing logical structure and assessing internal coherence. We introduce Theorem-of-Thought (ToTh), a novel framework that models reasoning as collaboration among three parallel agents, each simulating a distinct mode of inference: abductive, deductive, and inductive. Each agent produces a reasoning trace, which is structured into a formal reasoning graph. To evaluate consistency, we apply Bayesian belief propagation guided by natural language inference (NLI), assigning confidence scores to each step. The most coherent graph is selected to derive the final answer. Experiments on symbolic (WebOfLies) and numerical (MultiArith) reasoning benchmarks show that ToTh consistently outperforms CoT, Self-Consistency, and CoT-Decoding across multiple LLMs, while producing interpretable and logically grounded reasoning chains. Our findings suggest a promising direction for building more robust and cognitively inspired LLM reasoning. The implementation is available at https://github.com/KurbanIntelligenceLab/theorem-of-thought.
HalluVerse25: Fine-grained Multilingual Benchmark Dataset for LLM Hallucinations
Mar 10, 2025



Large Language Models (LLMs) are increasingly used in various contexts, yet remain prone to generating non-factual content, commonly referred to as "hallucinations". The literature categorizes hallucinations into several types, including entity-level, relation-level, and sentence-level hallucinations. However, existing hallucination datasets often fail to capture fine-grained hallucinations in multilingual settings. In this work, we introduce HalluVerse25, a multilingual LLM hallucination dataset that categorizes fine-grained hallucinations in English, Arabic, and Turkish. Our dataset construction pipeline uses an LLM to inject hallucinations into factual biographical sentences, followed by a rigorous human annotation process to ensure data quality. We evaluate several LLMs on HalluVerse25, providing valuable insights into how proprietary models perform in detecting LLM-generated hallucinations across different contexts.
SINdex: Semantic INconsistency Index for Hallucination Detection in LLMs
Mar 07, 2025Large language models (LLMs) are increasingly deployed across diverse domains, yet they are prone to generating factually incorrect outputs - commonly known as "hallucinations." Among existing mitigation strategies, uncertainty-based methods are particularly attractive due to their ease of implementation, independence from external data, and compatibility with standard LLMs. In this work, we introduce a novel and scalable uncertainty-based semantic clustering framework for automated hallucination detection. Our approach leverages sentence embeddings and hierarchical clustering alongside a newly proposed inconsistency measure, SINdex, to yield more homogeneous clusters and more accurate detection of hallucination phenomena across various LLMs. Evaluations on prominent open- and closed-book QA datasets demonstrate that our method achieves AUROC improvements of up to 9.3% over state-of-the-art techniques. Extensive ablation studies further validate the effectiveness of each component in our framework.
SAFE: A Sparse Autoencoder-Based Framework for Robust Query Enrichment and Hallucination Mitigation in LLMs
Mar 04, 2025

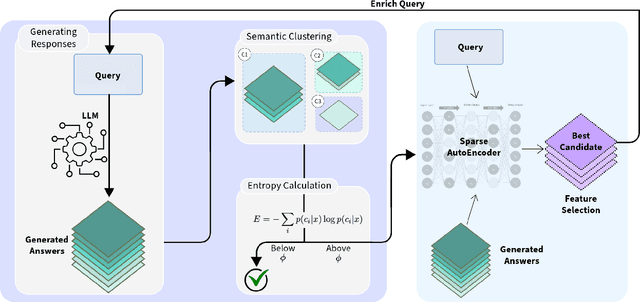

Despite the state-of-the-art performance of Large Language Models (LLMs), these models often suffer from hallucinations, which can undermine their performance in critical applications. In this work, we propose SAFE, a novel method for detecting and mitigating hallucinations by leveraging Sparse Autoencoders (SAEs). While hallucination detection techniques and SAEs have been explored independently, their synergistic application in a comprehensive system, particularly for hallucination-aware query enrichment, has not been fully investigated. To validate the effectiveness of SAFE, we evaluate it on two models with available SAEs across three diverse cross-domain datasets designed to assess hallucination problems. Empirical results demonstrate that SAFE consistently improves query generation accuracy and mitigates hallucinations across all datasets, achieving accuracy improvements of up to 29.45%.
ArAIEval Shared Task: Persuasion Techniques and Disinformation Detection in Arabic Text
Nov 06, 2023



We present an overview of the ArAIEval shared task, organized as part of the first ArabicNLP 2023 conference co-located with EMNLP 2023. ArAIEval offers two tasks over Arabic text: (i) persuasion technique detection, focusing on identifying persuasion techniques in tweets and news articles, and (ii) disinformation detection in binary and multiclass setups over tweets. A total of 20 teams participated in the final evaluation phase, with 14 and 16 teams participating in Tasks 1 and 2, respectively. Across both tasks, we observed that fine-tuning transformer models such as AraBERT was at the core of the majority of the participating systems. We provide a description of the task setup, including a description of the dataset construction and the evaluation setup. We further give a brief overview of the participating systems. All datasets and evaluation scripts from the shared task are released to the research community. (https://araieval.gitlab.io/) We hope this will enable further research on these important tasks in Arabic.