 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFE: A Sparse Autoencoder-Based Framework for Robust Query Enrichment and Hallucination Mitigation in LLMs
Mar 04, 2025

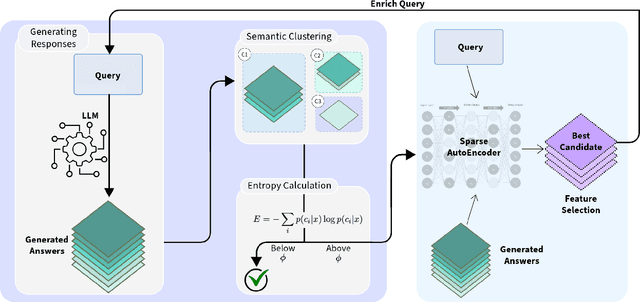

Despite the state-of-the-art performance of Large Language Models (LLMs), these models often suffer from hallucinations, which can undermine their performance in critical applications. In this work, we propose SAFE, a novel method for detecting and mitigating hallucinations by leveraging Sparse Autoencoders (SAEs). While hallucination detection techniques and SAEs have been explored independently, their synergistic application in a comprehensive system, particularly for hallucination-aware query enrichment, has not been fully investigated. To validate the effectiveness of SAFE, we evaluate it on two models with available SAEs across three diverse cross-domain datasets designed to assess hallucination problems. Empirical results demonstrate that SAFE consistently improves query generation accuracy and mitigates hallucinations across all datasets, achieving accuracy improvements of up to 29.45%.
Designing Role Vectors to Improve LLM Inference Behaviour
Feb 17, 2025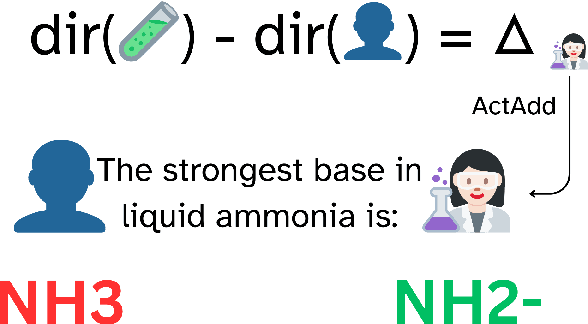

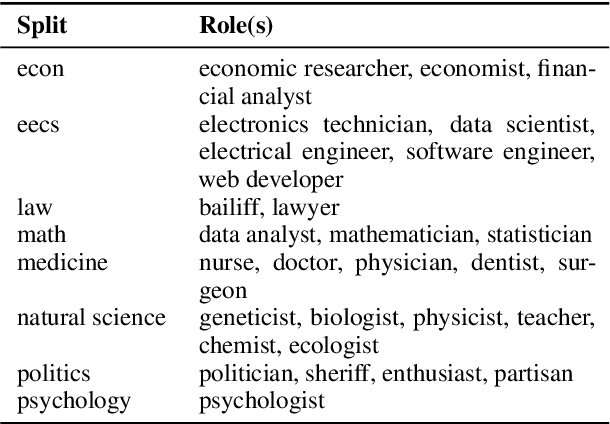
The influence of personas on Large Language Models (LLMs) has been widely studied, yet their direct impact on performance remains uncertain. This work explores a novel approach to guiding LLM behaviour through role vectors, an alternative to persona-based prompting. We construct 29 role vectors derived from model activations and evaluate their impact on benchmark performance across multiple domains. Our analysis investigates whether these vectors can effectively steer models toward domain-specific expertise. We measure two key interventions: (i) activation addition, which reinforces role-specific directions, and (ii) directional ablation, which removes them. Results on well-established benchmarks indicate that role vectors do, in fact, influence model behaviour, improving task performance in relevant domains while marginally affecting unrelated tasks. This, in turn, suggests that manipulating internal model representations has a greater impact on outcomes than persona-based prompting.
XAI meets LLMs: A Survey of the Relation between Explainable AI and Large Language Models
Jul 21, 2024

In this survey, we address the key challenges in Large Language Models (LLM) research, focusing on the importance of interpretability. Driven by increasing interest from AI and business sectors, we highlight the need for transparency in LLMs. We examine the dual paths in current LLM research and eXplainable Artificial Intelligence (XAI): enhancing performance through XAI and the emerging focus on model interpretability. Our paper advocates for a balanced approach that values interpretability equally with functional advancements. Recognizing the rapid development in LLM research, our survey includes both peer-reviewed and preprint (arXiv) papers, offering a comprehensive overview of XAI's role in LLM research. We conclude by urging the research community to advance both LLM and XAI fields together.
Disce aut Deficere: Evaluating LLMs Proficiency on the INVALSI Italian Benchmark
Jun 25, 2024Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to generate and manipulate human language, highlighting their potential across various applications. Evaluating LLMs in languages other than English is crucial for ensuring their linguistic versatility, cultural relevance, and applicability in diverse global contexts, thus broadening their usability and effectiveness. We tackle this challenge by introducing a structured benchmark using the INVALSI tests, a set of well-established assessments designed to measure educational competencies across Italy. Our study makes three primary contributions: Firstly, we adapt the INVALSI benchmark for automated LLM evaluation, which involves rigorous adaptation of the test format to suit automated processing while retaining the essence of the original tests. Secondly, we provide a detailed assessment of current LLMs, offering a crucial reference point for the academic community. Finally, we visually compare the performance of these models against human results. Additionally, researchers are invited to submit their models for ongoing evaluation, ensuring the benchmark remains a current and valuable resource.