 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Role Vectors to Improve LLM Inference Behaviour
Paper and Code
Feb 17, 2025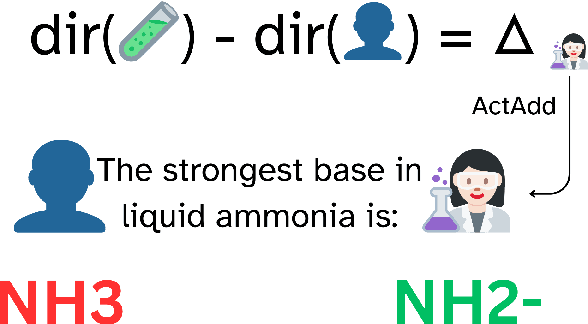
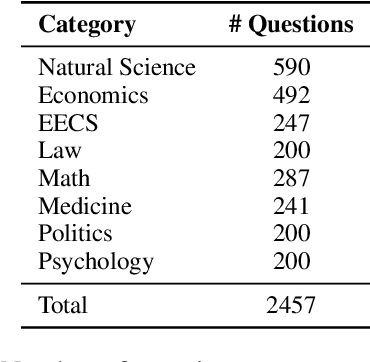

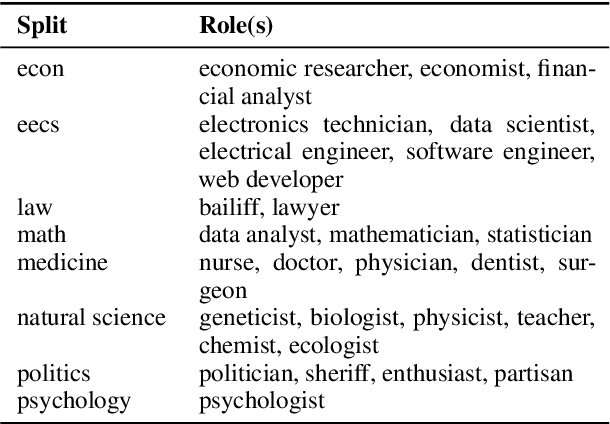
The influence of personas on Large Language Models (LLMs) has been widely studied, yet their direct impact on performance remains uncertain. This work explores a novel approach to guiding LLM behaviour through role vectors, an alternative to persona-based prompting. We construct 29 role vectors derived from model activations and evaluate their impact on benchmark performance across multiple domains. Our analysis investigates whether these vectors can effectively steer models toward domain-specific expertise. We measure two key interventions: (i) activation addition, which reinforces role-specific directions, and (ii) directional ablation, which removes them. Results on well-established benchmarks indicate that role vectors do, in fact, influence model behaviour, improving task performance in relevant domains while marginally affecting unrelated tasks. This, in turn, suggests that manipulating internal model representations has a greater impact on outcomes than persona-based prompting.