 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Can Detect Your Bias: Predicting the Political Ideology of News Articles
Oct 11, 2020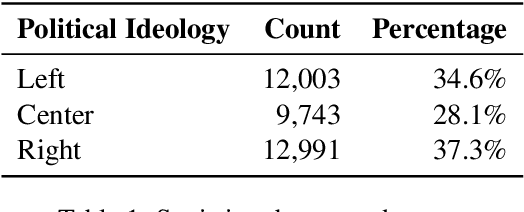
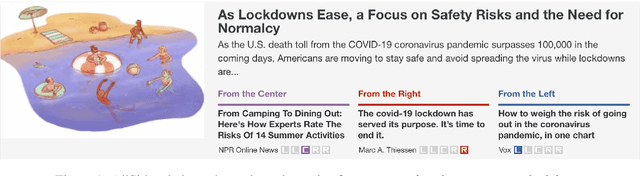
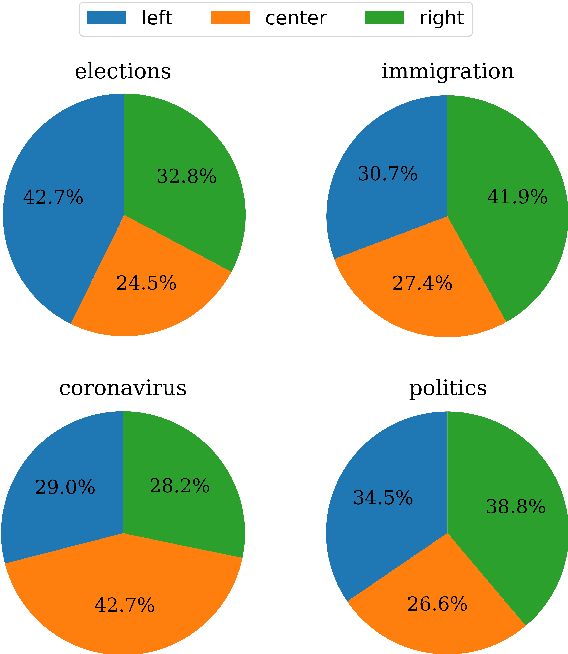
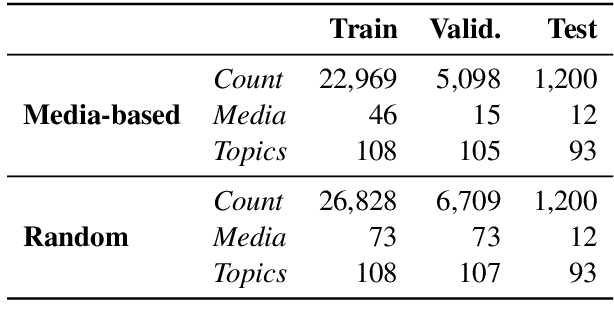
We explore the task of predicting the leading political ideology or bias of news articles. First, we collect and release a large dataset of 34,737 articles that were manually annotated for political ideology -left, center, or right-, which is well-balanced across both topics and media. We further use a challenging experimental setup where the test examples come from media that were not seen during training, which prevents the model from learning to detect the source of the target news article instead of predicting its political ideology. From a modeling perspective, we propose an adversarial media adaptation, as well as a specially adapted triplet loss. We further add background information about the source, and we show that it is quite helpful for improving article-level prediction. Our experimental results show very sizable improvements over using state-of-the-art pre-trained Transformers in this challenging setup.
* Political bias, bias in news, neural networks bias, adversarial adaptation, triplet loss, transformers, recurrent neural networks
What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context
May 09, 2020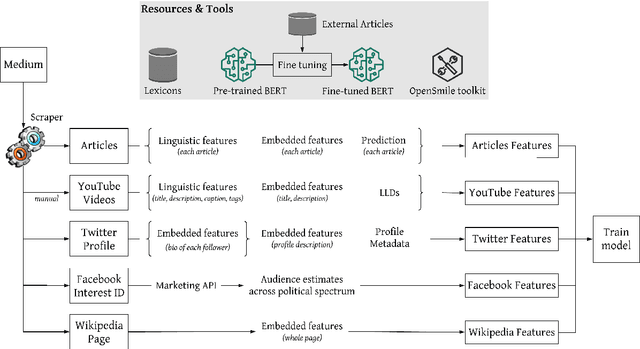
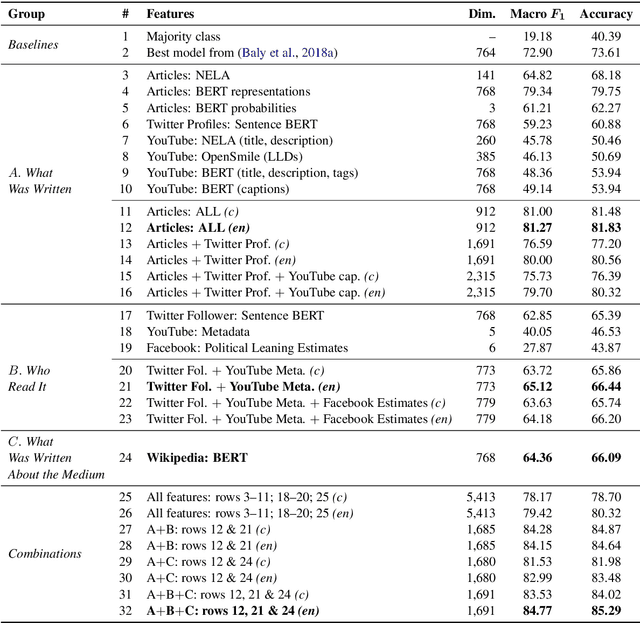
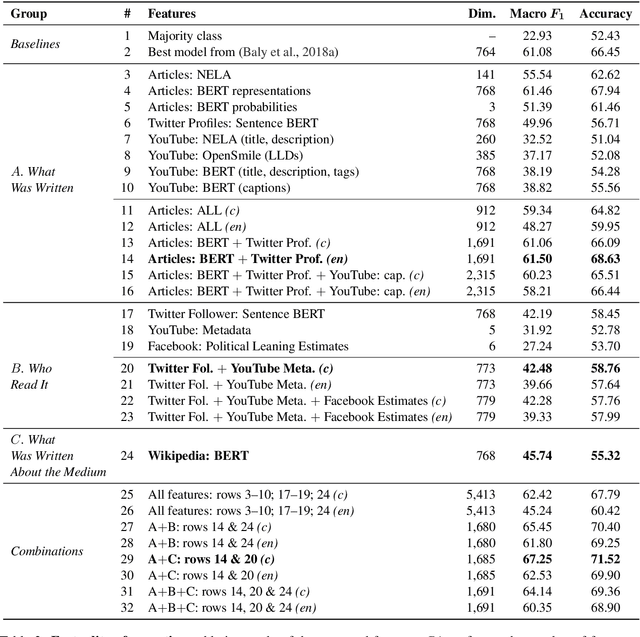
Predicting the political bias and the factuality of reporting of entire news outlets are critical elements of media profiling, which is an understudied but an increasingly important research direction. The present level of proliferation of fake, biased, and propagandistic content online, has made it impossible to fact-check every single suspicious claim, either manually or automatically. Alternatively, we can profile entire news outlets and look for those that are likely to publish fake or biased content. This approach makes it possible to detect likely "fake news" the moment they are published, by simply checking the reliability of their source. From a practical perspective, political bias and factuality of reporting have a linguistic aspect but also a social context. Here, we study the impact of both, namely (i) what was written (i.e., what was published by the target medium, and how it describes itself on Twitter) vs. (ii) who read it (i.e., analyzing the readers of the target medium on Facebook, Twitter, and YouTube). We further study (iii) what was written about the target medium on Wikipedia. The evaluation results show that what was written matters most, and that putting all information sources together yields huge improvements over the current state-of-the-art.
* Factuality of reporting, fact-checking, political ideology, media bias, disinformation, propaganda, social media, news media
Tanbih: Get To Know What You Are Reading
Oct 04, 2019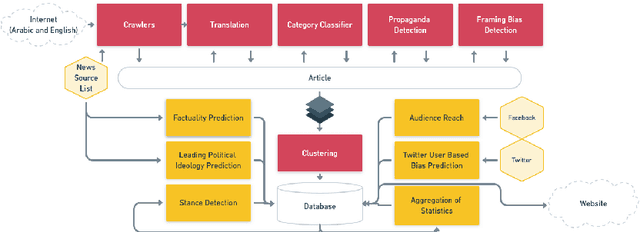
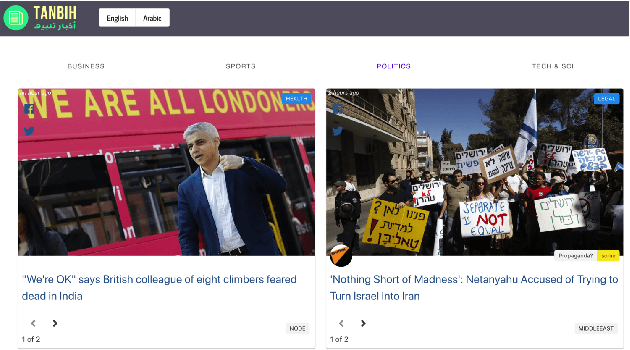
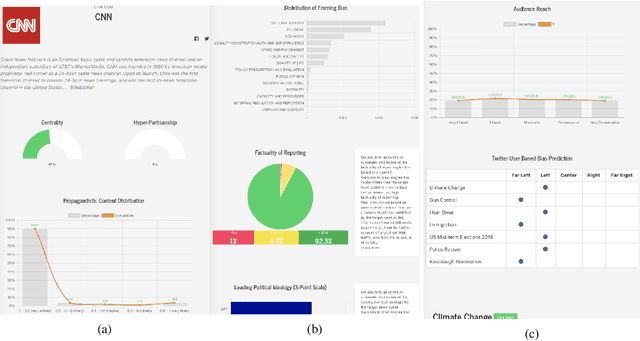
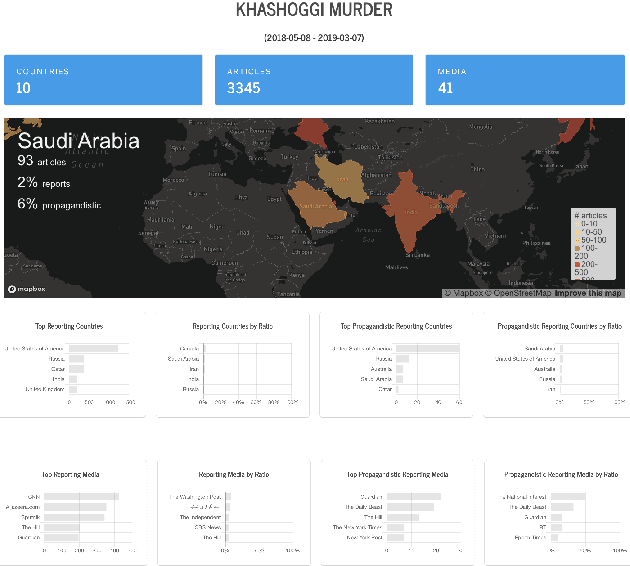
We introduce Tanbih, a news aggregator with intelligent analysis tools to help readers understanding what's behind a news story. Our system displays news grouped into events and generates media profiles that show the general factuality of reporting, the degree of propagandistic content, hyper-partisanship, leading political ideology, general frame of reporting, and stance with respect to various claims and topics of a news outlet. In addition, we automatically analyse each article to detect whether it is propagandistic and to determine its stance with respect to a number of controversial topics.
SemEval-2019 Task 8: Fact Checking in Community Question Answering Forums
May 25, 2019
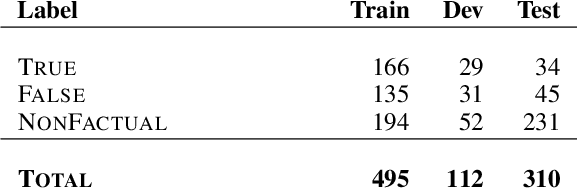
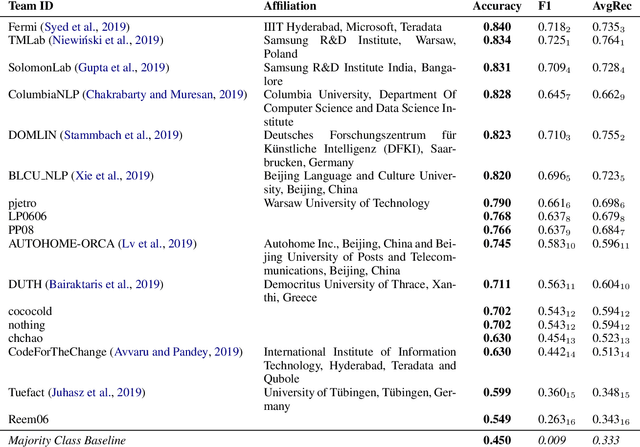
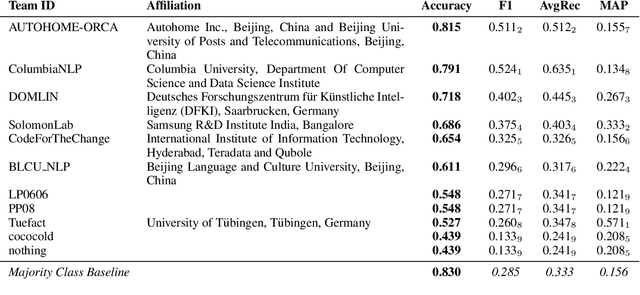
We present SemEval-2019 Task 8 on Fact Checking in Community Question Answering Forums, which features two subtasks. Subtask A is about deciding whether a question asks for factual information vs. an opinion/advice vs. just socializing. Subtask B asks to predict whether an answer to a factual question is true, false or not a proper answer. We received 17 official submissions for subtask A and 11 official submissions for Subtask B. For subtask A, all systems improved over the majority class baseline. For Subtask B, all systems were below a majority class baseline, but several systems were very close to it. The leaderboard and the data from the competition can be found at http://competitions.codalab.org/competitions/20022
ArSentD-LEV: A Multi-Topic Corpus for Target-based Sentiment Analysis in Arabic Levantine Tweets
May 25, 2019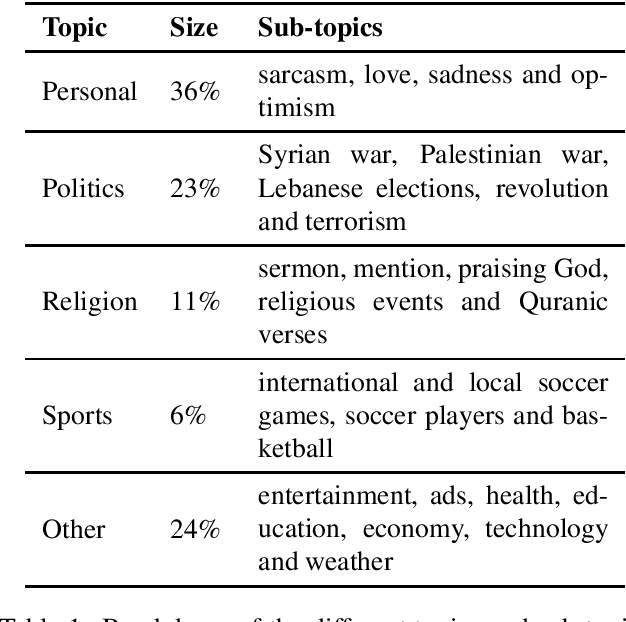
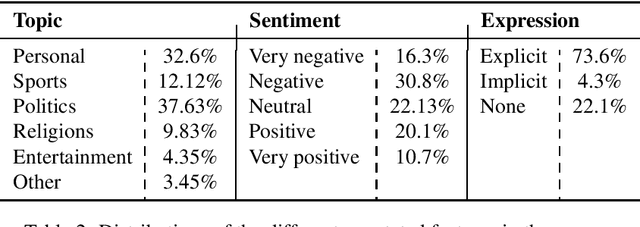
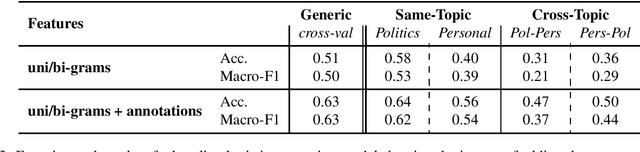
Sentiment analysis is a highly subjective and challenging task. Its complexity further increases when applied to the Arabic language, mainly because of the large variety of dialects that are unstandardized and widely used in the Web, especially in social media. While many datasets have been released to train sentiment classifiers in Arabic, most of these datasets contain shallow annotation, only marking the sentiment of the text unit, as a word, a sentence or a document. In this paper, we present the Arabic Sentiment Twitter Dataset for the Levantine dialect (ArSenTD-LEV). Based on findings from analyzing tweets from the Levant region, we created a dataset of 4,000 tweets with the following annotations: the overall sentiment of the tweet, the target to which the sentiment was expressed, how the sentiment was expressed, and the topic of the tweet. Results confirm the importance of these annotations at improving the performance of a baseline sentiment classifier. They also confirm the gap of training in a certain domain, and testing in another domain.
Team QCRI-MIT at SemEval-2019 Task 4: Propaganda Analysis Meets Hyperpartisan News Detection
Apr 06, 2019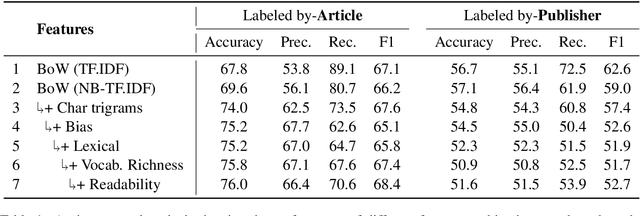
In this paper, we describe our submission to SemEval-2019 Task 4 on Hyperpartisan News Detection. Our system relies on a variety of engineered features originally used to detect propaganda. This is based on the assumption that biased messages are propagandistic in the sense that they promote a particular political cause or viewpoint. We trained a logistic regression model with features ranging from simple bag-of-words to vocabulary richness and text readability features. Our system achieved 72.9% accuracy on the test data that is annotated manually and 60.8% on the test data that is annotated with distant supervision. Additional experiments showed that significant performance improvements can be achieved with better feature pre-processing.
Multi-Task Ordinal Regression for Jointly Predicting the Trustworthiness and the Leading Political Ideology of News Media
Apr 01, 2019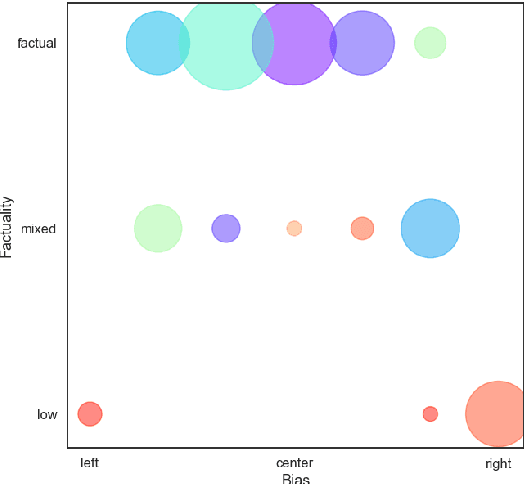
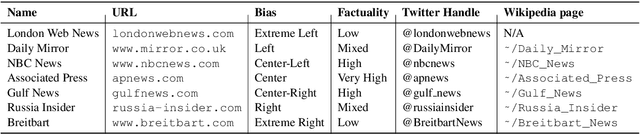
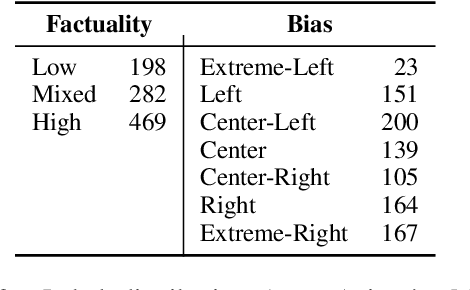
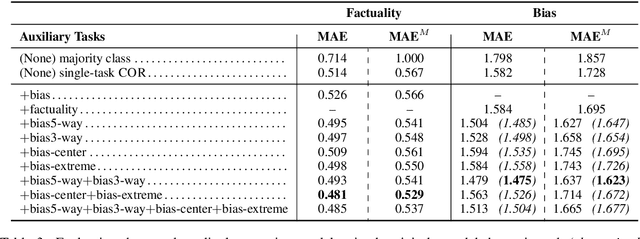
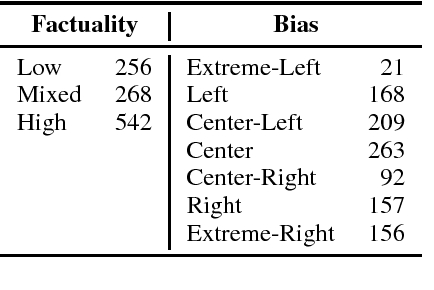
In the context of fake news, bias, and propaganda, we study two important but relatively under-explored problems: (i) trustworthiness estimation (on a 3-point scale) and (ii) political ideology detection (left/right bias on a 7-point scale) of entire news outlets, as opposed to evaluating individual articles. In particular, we propose a multi-task ordinal regression framework that models the two problems jointly. This is motivated by the observation that hyper-partisanship is often linked to low trustworthiness, e.g., appealing to emotions rather than sticking to the facts, while center media tend to be generally more impartial and trustworthy. We further use several auxiliary tasks, modeling centrality, hyperpartisanship, as well as left-vs.-right bias on a coarse-grained scale. The evaluation results show sizable performance gains by the joint models over models that target the problems in isolation.
Predicting Factuality of Reporting and Bias of News Media Sources
Oct 02, 2018

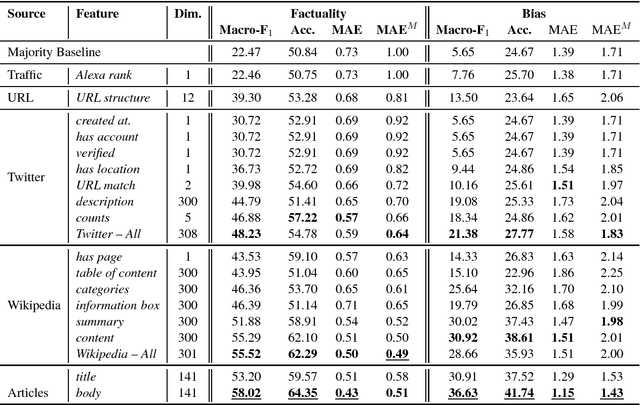
We present a study on predicting the factuality of reporting and bias of news media. While previous work has focused on studying the veracity of claims or documents, here we are interested in characterizing entire news media. These are under-studied but arguably important research problems, both in their own right and as a prior for fact-checking systems. We experiment with a large list of news websites and with a rich set of features derived from (i) a sample of articles from the target news medium, (ii) its Wikipedia page, (iii) its Twitter account, (iv) the structure of its URL, and (v) information about the Web traffic it attracts. The experimental results show sizable performance gains over the baselines, and confirm the importance of each feature type.
Integrating Stance Detection and Fact Checking in a Unified Corpus
Apr 21, 2018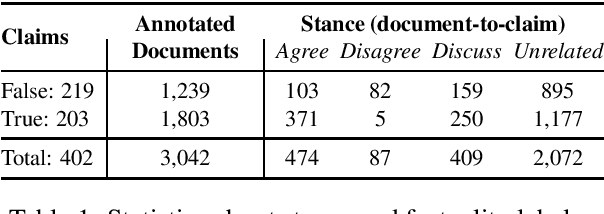
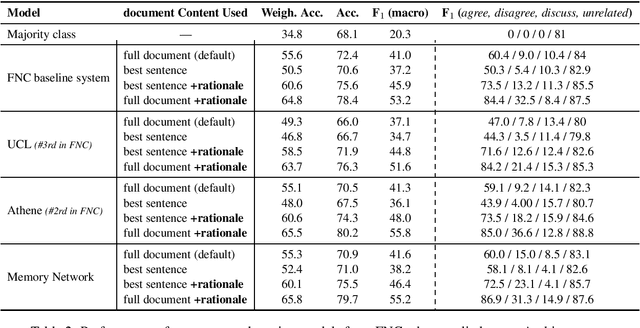
A reasonable approach for fact checking a claim involves retrieving potentially relevant documents from different sources (e.g., news websites, social media, etc.), determining the stance of each document with respect to the claim, and finally making a prediction about the claim's factuality by aggregating the strength of the stances, while taking the reliability of the source into account. Moreover, a fact checking system should be able to explain its decision by providing relevant extracts (rationales) from the documents. Yet, this setup is not directly supported by existing datasets, which treat fact checking, document retrieval, source credibility, stance detection and rationale extraction as independent tasks. In this paper, we support the interdependencies between these tasks as annotations in the same corpus. We implement this setup on an Arabic fact checking corpus, the first of its kind.
Automatic Stance Detection Using End-to-End Memory Networks
Apr 20, 2018

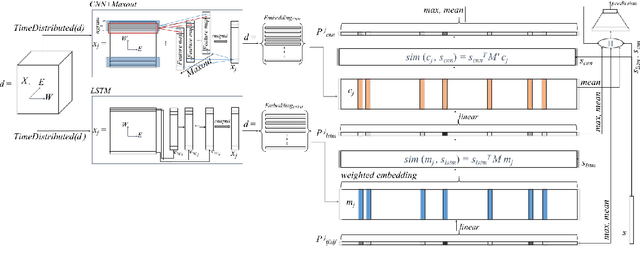
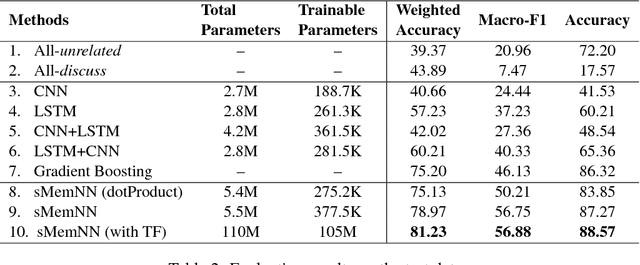
We present a novel end-to-end memory network for stance detection, which jointly (i) predicts whether a document agrees, disagrees, discusses or is unrelated with respect to a given target claim, and also (ii) extracts snippets of evidence for that prediction. The network operates at the paragraph level and integrates convolutional and recurrent neural networks, as well as a similarity matrix as part of the overall architecture. The experimental evaluation on the Fake News Challenge dataset shows state-of-the-art performance.