 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Neural Dialog Models for Conversational Understanding
Jun 07, 2020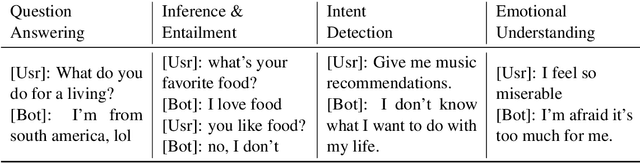
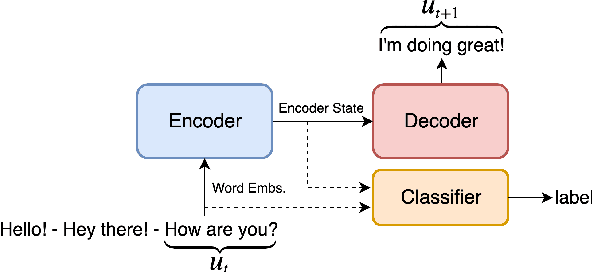
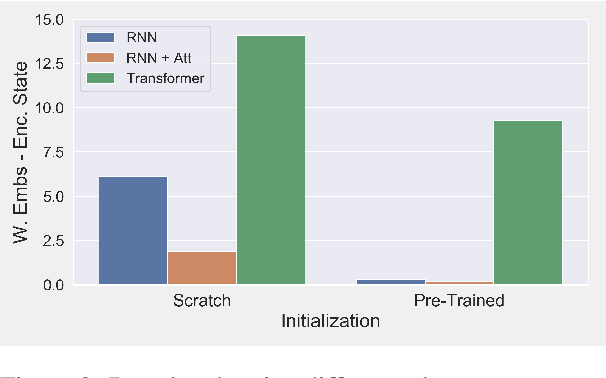
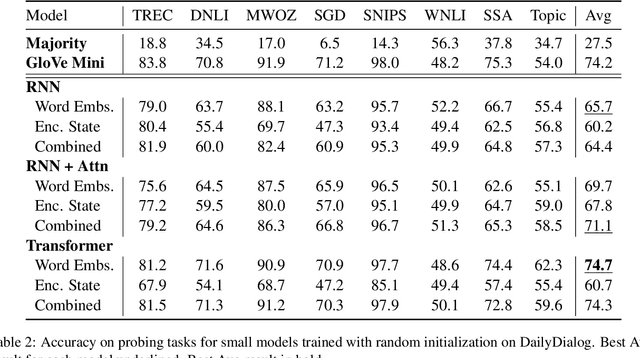
The predominant approach to open-domain dialog generation relies on end-to-end training of neural models on chat datasets. However, this approach provides little insight as to what these models learn (or do not learn) about engaging in dialog. In this study, we analyze the internal representations learned by neural open-domain dialog systems and evaluate the quality of these representations for learning basic conversational skills. Our results suggest that standard open-domain dialog systems struggle with answering questions, inferring contradiction, and determining the topic of conversation, among other tasks. We also find that the dyadic, turn-taking nature of dialog is not fully leveraged by these models. By exploring these limitations, we highlight the need for additional research into architectures and training methods that can better capture high-level information about dialog.
Hierarchical Reinforcement Learning for Open-Domain Dialog
Sep 18, 2019
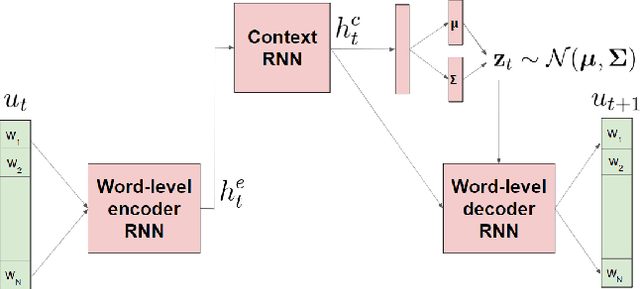
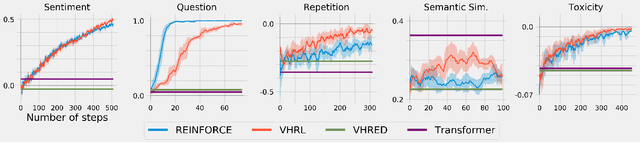
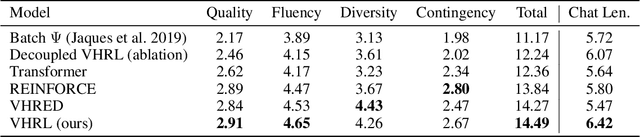
Open-domain dialog generation is a challenging problem; maximum likelihood training can lead to repetitive outputs, models have difficulty tracking long-term conversational goals, and training on standard movie or online datasets may lead to the generation of inappropriate, biased, or offensive text. Reinforcement Learning (RL) is a powerful framework that could potentially address these issues, for example by allowing a dialog model to optimize for reducing toxicity and repetitiveness. However, previous approaches which apply RL to open-domain dialog generation do so at the word level, making it difficult for the model to learn proper credit assignment for long-term conversational rewards. In this paper, we propose a novel approach to hierarchical reinforcement learning, VHRL, which uses policy gradients to tune the utterance-level embedding of a variational sequence model. This hierarchical approach provides greater flexibility for learning long-term, conversational rewards. We use self-play and RL to optimize for a set of human-centered conversation metrics, and show that our approach provides significant improvements -- in terms of both human evaluation and automatic metrics -- over state-of-the-art dialog models, including Transformers.
Team QCRI-MIT at SemEval-2019 Task 4: Propaganda Analysis Meets Hyperpartisan News Detection
Apr 06, 2019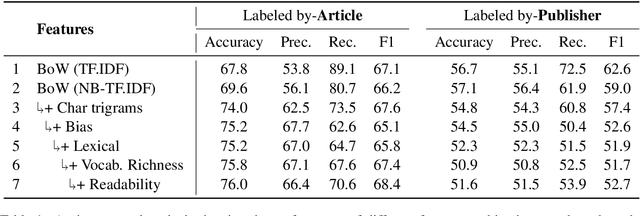
In this paper, we describe our submission to SemEval-2019 Task 4 on Hyperpartisan News Detection. Our system relies on a variety of engineered features originally used to detect propaganda. This is based on the assumption that biased messages are propagandistic in the sense that they promote a particular political cause or viewpoint. We trained a logistic regression model with features ranging from simple bag-of-words to vocabulary richness and text readability features. Our system achieved 72.9% accuracy on the test data that is annotated manually and 60.8% on the test data that is annotated with distant supervision. Additional experiments showed that significant performance improvements can be achieved with better feature pre-processing.
Multi-Task Ordinal Regression for Jointly Predicting the Trustworthiness and the Leading Political Ideology of News Media
Apr 01, 2019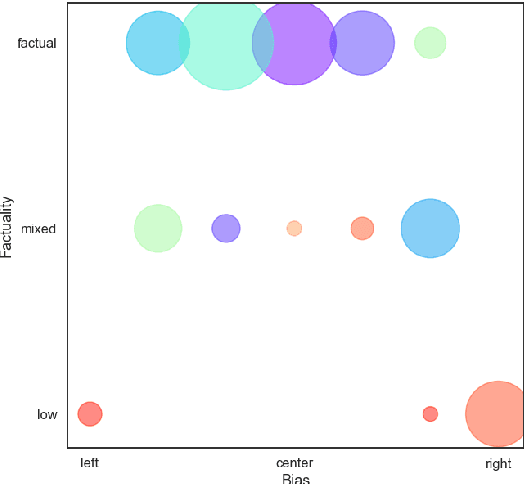
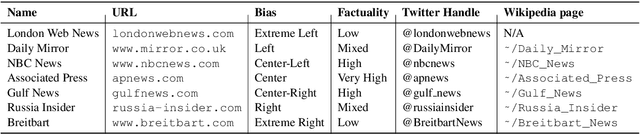
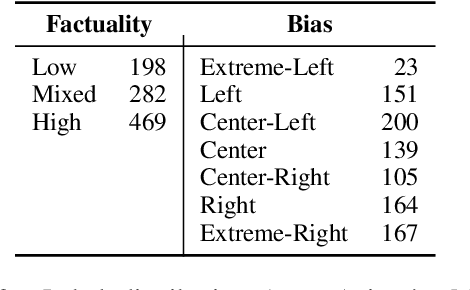
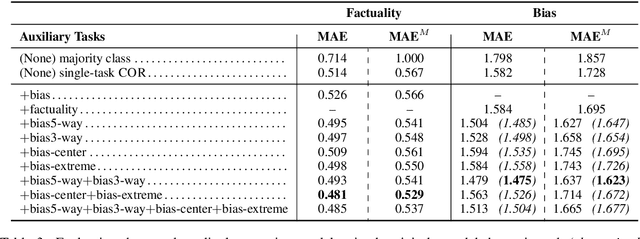
In the context of fake news, bias, and propaganda, we study two important but relatively under-explored problems: (i) trustworthiness estimation (on a 3-point scale) and (ii) political ideology detection (left/right bias on a 7-point scale) of entire news outlets, as opposed to evaluating individual articles. In particular, we propose a multi-task ordinal regression framework that models the two problems jointly. This is motivated by the observation that hyper-partisanship is often linked to low trustworthiness, e.g., appealing to emotions rather than sticking to the facts, while center media tend to be generally more impartial and trustworthy. We further use several auxiliary tasks, modeling centrality, hyperpartisanship, as well as left-vs.-right bias on a coarse-grained scale. The evaluation results show sizable performance gains by the joint models over models that target the problems in isolation.