 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
May 23, 2024When leveraging language models for reasoning tasks, generating explicit chain-of-thought (CoT) steps often proves essential for achieving high accuracy in final outputs. In this paper, we investigate if models can be taught to internalize these CoT steps. To this end, we propose a simple yet effective method for internalizing CoT steps: starting with a model trained for explicit CoT reasoning, we gradually remove the intermediate steps and finetune the model. This process allows the model to internalize the intermediate reasoning steps, thus simplifying the reasoning process while maintaining high performance. Our approach enables a GPT-2 Small model to solve 9-by-9 multiplication with up to 99% accuracy, whereas standard training cannot solve beyond 4-by-4 multiplication. Furthermore, our method proves effective on larger language models, such as Mistral 7B, achieving over 50% accuracy on GSM8K without producing any intermediate steps.
Implicit Chain of Thought Reasoning via Knowledge Distillation
Nov 02, 2023To augment language models with the ability to reason, researchers usually prompt or finetune them to produce chain of thought reasoning steps before producing the final answer. However, although people use natural language to reason effectively, it may be that LMs could reason more effectively with some intermediate computation that is not in natural language. In this work, we explore an alternative reasoning approach: instead of explicitly producing the chain of thought reasoning steps, we use the language model's internal hidden states to perform implicit reasoning. The implicit reasoning steps are distilled from a teacher model trained on explicit chain-of-thought reasoning, and instead of doing reasoning "horizontally" by producing intermediate words one-by-one, we distill it such that the reasoning happens "vertically" among the hidden states in different layers. We conduct experiments on a multi-digit multiplication task and a grade school math problem dataset and find that this approach enables solving tasks previously not solvable without explicit chain-of-thought, at a speed comparable to no chain-of-thought.
Causal Analysis of Syntactic Agreement Mechanisms in Neural Language Models
Jun 22, 2021

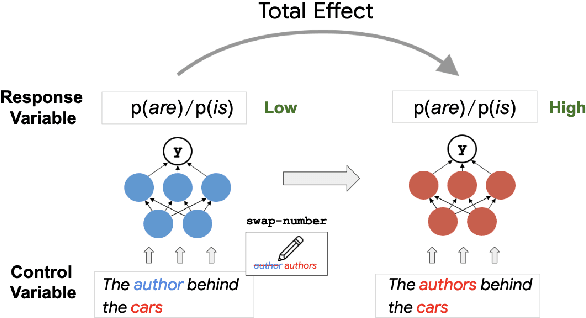
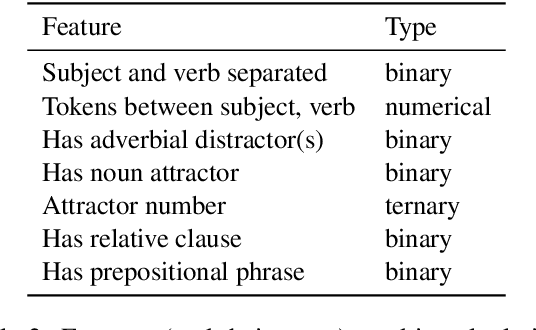
Targeted syntactic evaluations have demonstrated the ability of language models to perform subject-verb agreement given difficult contexts. To elucidate the mechanisms by which the models accomplish this behavior, this study applies causal mediation analysis to pre-trained neural language models. We investigate the magnitude of models' preferences for grammatical inflections, as well as whether neurons process subject-verb agreement similarly across sentences with different syntactic structures. We uncover similarities and differences across architectures and model sizes -- notably, that larger models do not necessarily learn stronger preferences. We also observe two distinct mechanisms for producing subject-verb agreement depending on the syntactic structure of the input sentence. Finally, we find that language models rely on similar sets of neurons when given sentences with similar syntactic structure.
Probing Neural Dialog Models for Conversational Understanding
Jun 07, 2020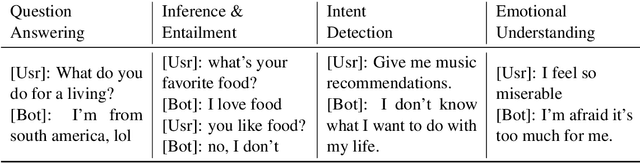
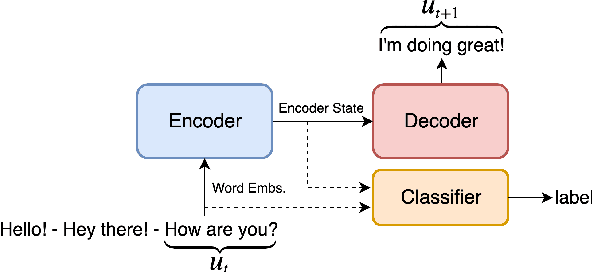
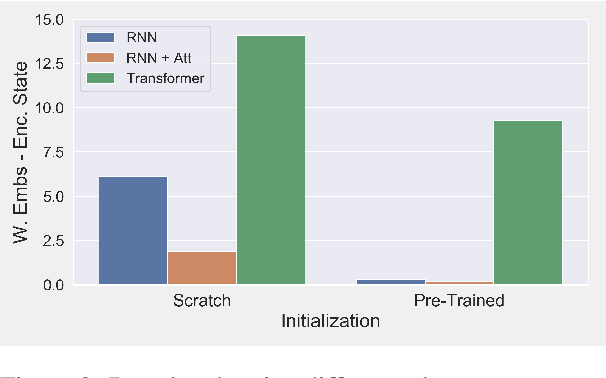
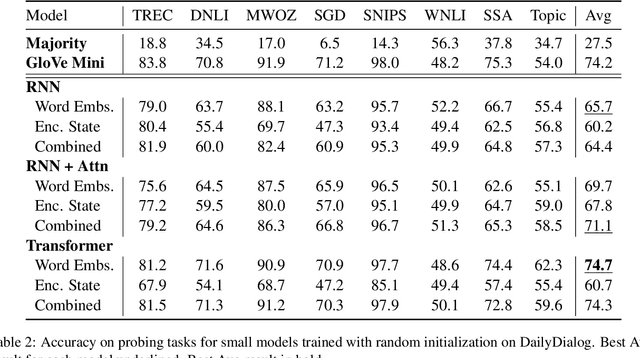
The predominant approach to open-domain dialog generation relies on end-to-end training of neural models on chat datasets. However, this approach provides little insight as to what these models learn (or do not learn) about engaging in dialog. In this study, we analyze the internal representations learned by neural open-domain dialog systems and evaluate the quality of these representations for learning basic conversational skills. Our results suggest that standard open-domain dialog systems struggle with answering questions, inferring contradiction, and determining the topic of conversation, among other tasks. We also find that the dyadic, turn-taking nature of dialog is not fully leveraged by these models. By exploring these limitations, we highlight the need for additional research into architectures and training methods that can better capture high-level information about dialog.
Linguistic Features for Readability Assessment
May 30, 2020
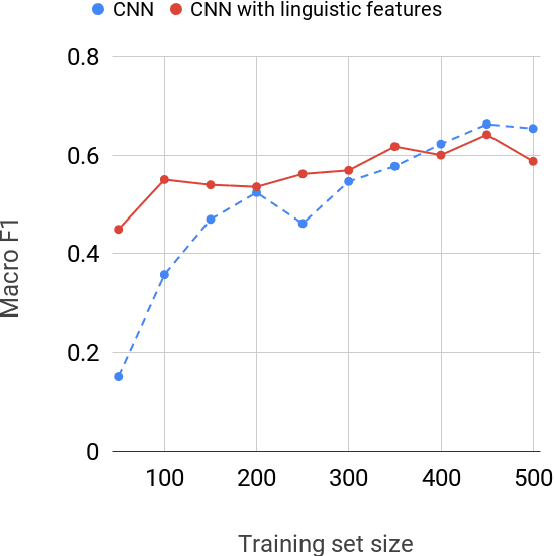
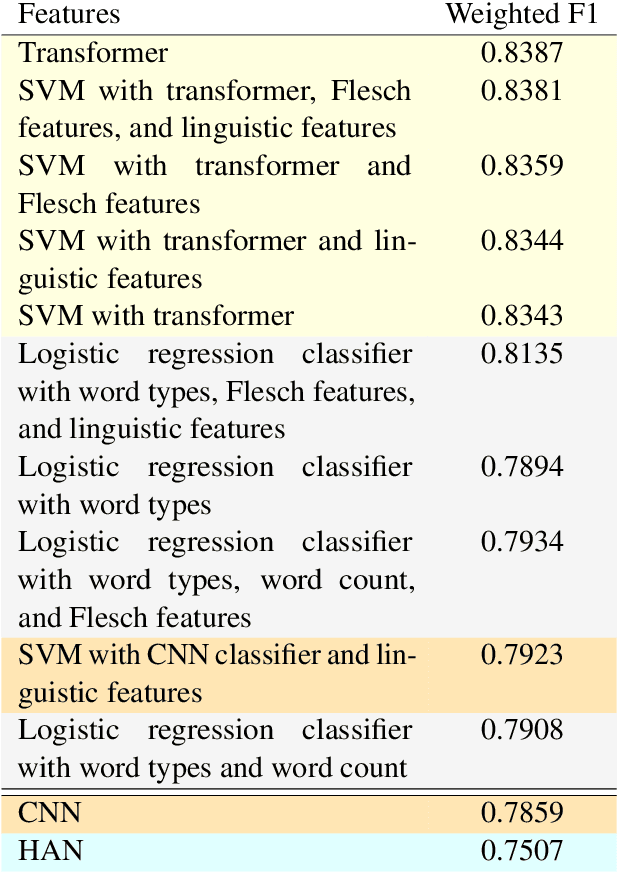

Readability assessment aims to automatically classify text by the level appropriate for learning readers. Traditional approaches to this task utilize a variety of linguistically motivated features paired with simple machine learning models. More recent methods have improved performance by discarding these features and utilizing deep learning models. However, it is unknown whether augmenting deep learning models with linguistically motivated features would improve performance further. This paper combines these two approaches with the goal of improving overall model performance and addressing this question. Evaluating on two large readability corpora, we find that, given sufficient training data, augmenting deep learning models with linguistically motivated features does not improve state-of-the-art performance. Our results provide preliminary evidence for the hypothesis that the state-of-the-art deep learning models represent linguistic features of the text related to readability. Future research on the nature of representations formed in these models can shed light on the learned features and their relations to linguistically motivated ones hypothesized in traditional approaches.
Causal Mediation Analysis for Interpreting Neural NLP: The Case of Gender Bias
Apr 26, 2020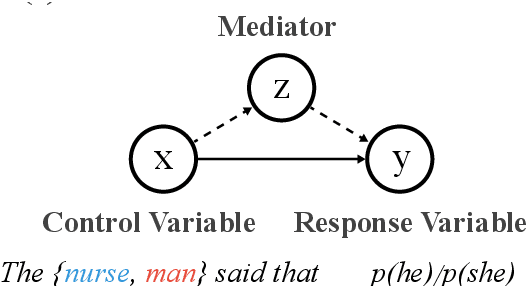
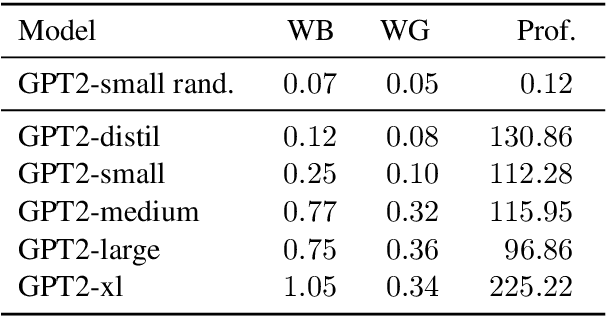

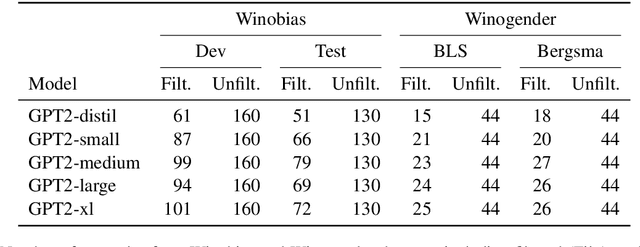
Common methods for interpreting neural models in natural language processing typically examine either their structure or their behavior, but not both. We propose a methodology grounded in the theory of causal mediation analysis for interpreting which parts of a model are causally implicated in its behavior. It enables us to analyze the mechanisms by which information flows from input to output through various model components, known as mediators. We apply this methodology to analyze gender bias in pre-trained Transformer language models. We study the role of individual neurons and attention heads in mediating gender bias across three datasets designed to gauge a model's sensitivity to gender bias. Our mediation analysis reveals that gender bias effects are (i) sparse, concentrated in a small part of the network; (ii) synergistic, amplified or repressed by different components; and (iii) decomposable into effects flowing directly from the input and indirectly through the mediators.