 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Estimation of Causal Effects Using Proxies of a Latent Interference Network
May 13, 2025Network interference occurs when treatments assigned to some units affect the outcomes of others. Traditional approaches often assume that the observed network correctly specifies the interference structure. However, in practice, researchers frequently only have access to proxy measurements of the interference network due to limitations in data collection or potential mismatches between measured networks and actual interference pathways. In this paper, we introduce a framework for estimating causal effects when only proxy networks are available. Our approach leverages a structural causal model that accommodates diverse proxy types, including noisy measurements, multiple data sources, and multilayer networks, and defines causal effects as interventions on population-level treatments. Since the true interference network is latent, estimation poses significant challenges. To overcome them, we develop a Bayesian inference framework. We propose a Block Gibbs sampler with Locally Informed Proposals to update the latent network, thereby efficiently exploring the high-dimensional posterior space composed of both discrete and continuous parameters. We illustrate the performance of our method through numerical experiments, demonstrating its accuracy in recovering causal effects even when only proxies of the interference network are available.
Causal Mediation Analysis for Interpreting Neural NLP: The Case of Gender Bias
Apr 26, 2020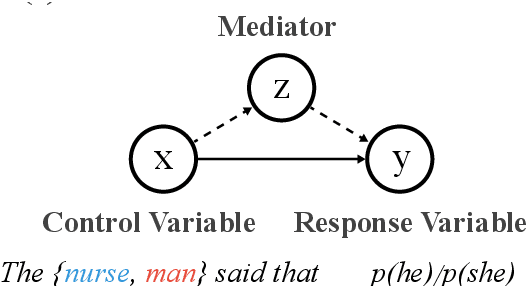
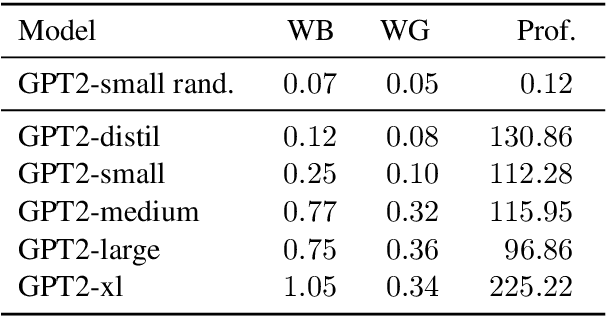

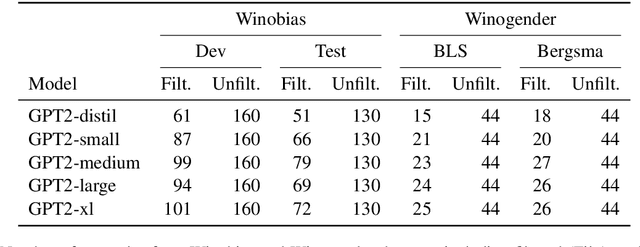
Common methods for interpreting neural models in natural language processing typically examine either their structure or their behavior, but not both. We propose a methodology grounded in the theory of causal mediation analysis for interpreting which parts of a model are causally implicated in its behavior. It enables us to analyze the mechanisms by which information flows from input to output through various model components, known as mediators. We apply this methodology to analyze gender bias in pre-trained Transformer language models. We study the role of individual neurons and attention heads in mediating gender bias across three datasets designed to gauge a model's sensitivity to gender bias. Our mediation analysis reveals that gender bias effects are (i) sparse, concentrated in a small part of the network; (ii) synergistic, amplified or repressed by different components; and (iii) decomposable into effects flowing directly from the input and indirectly through the mediators.