 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"On the goals of linguistic theory": Revisiting Chomskyan theories in the era of AI
Nov 15, 2024



Theoretical linguistics seeks to explain what human language is, and why. Linguists and cognitive scientists have proposed different theoretical models of what language is, as well as cognitive factors that shape it, and allow humans to 'produce', 'understand', and 'acquire' natural languages. However, humans may no longer be the only ones learning to 'generate', 'parse', and 'learn' natural language: artificial intelligence (AI) models such as large language models are proving to have impressive linguistic capabilities. Many are thus questioning what role, if any, such models should play in helping theoretical linguistics reach its ultimate research goals? In this paper, we propose to answer this question, by reiterating the tenets of generative linguistics, a leading school of thought in the field, and by considering how AI models as theories of language relate to each of these important concepts. Specifically, we consider three foundational principles, finding roots in the early works of Noam Chomsky: (1) levels of theoretical adequacy; (2) procedures for linguistic theory development; (3) language learnability and Universal Grammar. In our discussions of each principle, we give special attention to two types of AI models: neural language models and neural grammar induction models. We will argue that such models, in particular neural grammar induction models, do have a role to play, but that this role is largely modulated by the stance one takes regarding each of these three guiding principles.
Linguistic Features for Readability Assessment
May 30, 2020
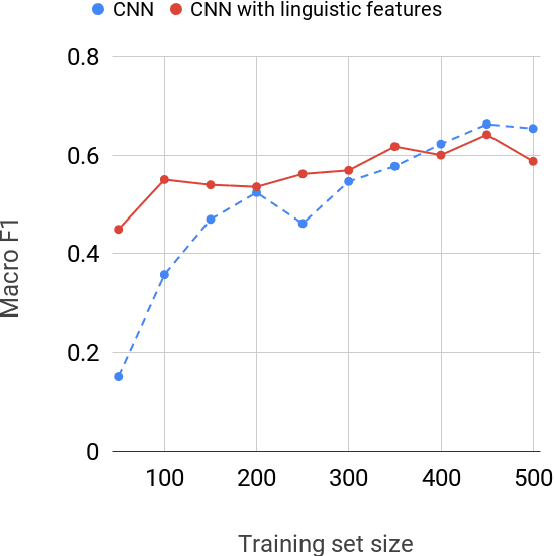
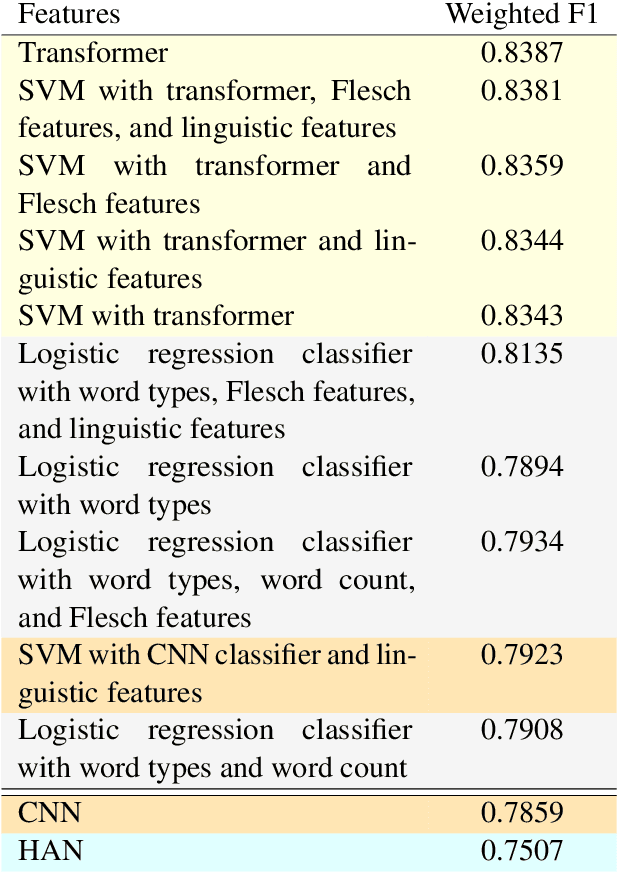

Readability assessment aims to automatically classify text by the level appropriate for learning readers. Traditional approaches to this task utilize a variety of linguistically motivated features paired with simple machine learning models. More recent methods have improved performance by discarding these features and utilizing deep learning models. However, it is unknown whether augmenting deep learning models with linguistically motivated features would improve performance further. This paper combines these two approaches with the goal of improving overall model performance and addressing this question. Evaluating on two large readability corpora, we find that, given sufficient training data, augmenting deep learning models with linguistically motivated features does not improve state-of-the-art performance. Our results provide preliminary evidence for the hypothesis that the state-of-the-art deep learning models represent linguistic features of the text related to readability. Future research on the nature of representations formed in these models can shed light on the learned features and their relations to linguistically motivated ones hypothesized in traditional approaches.