 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Propaganda Detection in News Articles
Aug 29, 2021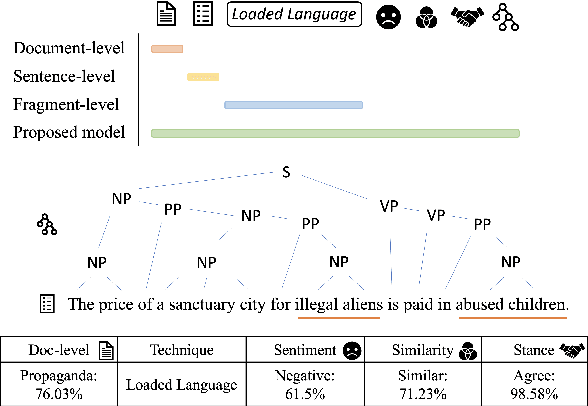

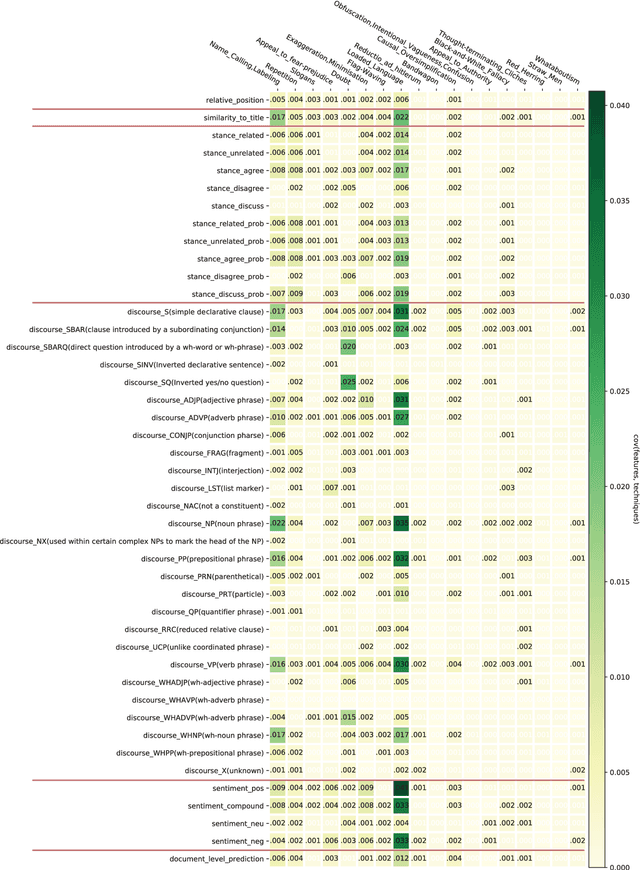
Online users today are exposed to misleading and propagandistic news articles and media posts on a daily basis. To counter thus, a number of approaches have been designed aiming to achieve a healthier and safer online news and media consumption. Automatic systems are able to support humans in detecting such content; yet, a major impediment to their broad adoption is that besides being accurate, the decisions of such systems need also to be interpretable in order to be trusted and widely adopted by users. Since misleading and propagandistic content influences readers through the use of a number of deception techniques, we propose to detect and to show the use of such techniques as a way to offer interpretability. In particular, we define qualitatively descriptive features and we analyze their suitability for detecting deception techniques. We further show that our interpretable features can be easily combined with pre-trained language models, yielding state-of-the-art results.
* propaganda, propaganda techniques, disinformation, misinformation, fake news, explainability, interpretability
Contrastive Language Adaptation for Cross-Lingual Stance Detection
Oct 04, 2019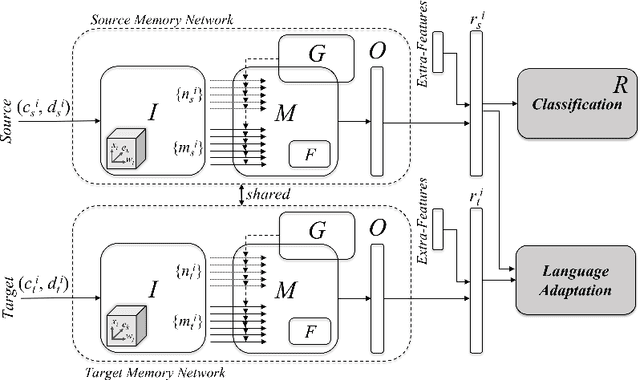

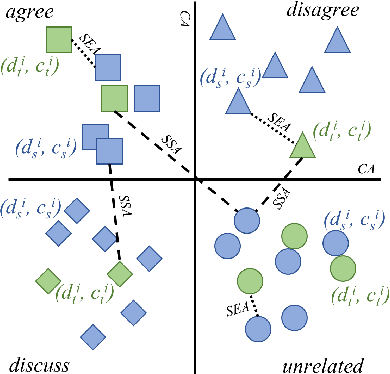
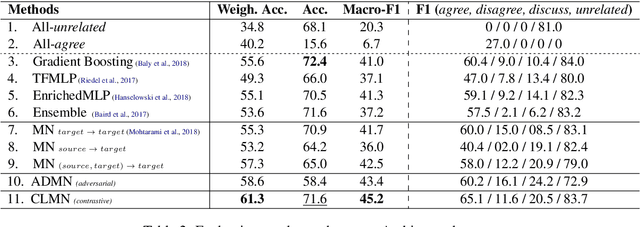
We study cross-lingual stance detection, which aims to leverage labeled data in one language to identify the relative perspective (or stance) of a given document with respect to a claim in a different target language. In particular, we introduce a novel contrastive language adaptation approach applied to memory networks, which ensures accurate alignment of stances in the source and target languages, and can effectively deal with the challenge of limited labeled data in the target language. The evaluation results on public benchmark datasets and comparison against current state-of-the-art approaches demonstrate the effectiveness of our approach.
Automatic Fact-Checking Using Context and Discourse Information
Aug 04, 2019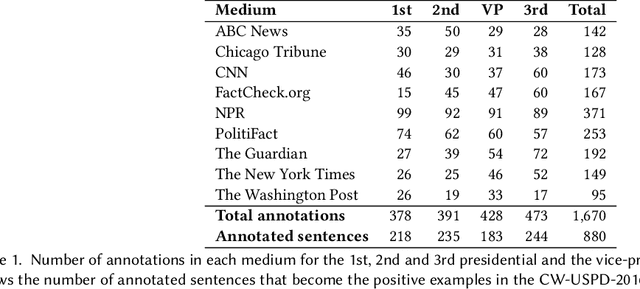
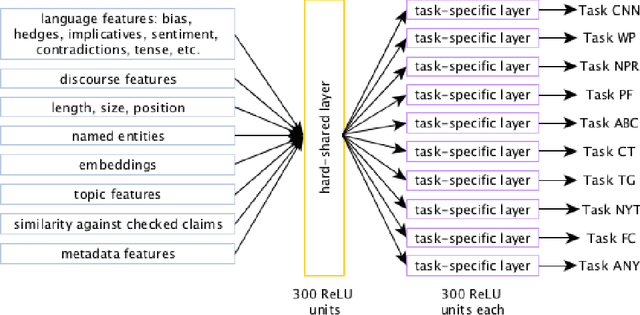

We study the problem of automatic fact-checking, paying special attention to the impact of contextual and discourse information. We address two related tasks: (i) detecting check-worthy claims, and (ii) fact-checking claims. We develop supervised systems based on neural networks, kernel-based support vector machines, and combinations thereof, which make use of rich input representations in terms of discourse cues and contextual features. For the check-worthiness estimation task, we focus on political debates, and we model the target claim in the context of the full intervention of a participant and the previous and the following turns in the debate, taking into account contextual meta information. For the fact-checking task, we focus on answer verification in a community forum, and we model the veracity of the answer with respect to the entire question--answer thread in which it occurs as well as with respect to other related posts from the entire forum. We develop annotated datasets for both tasks and we run extensive experimental evaluation, confirming that both types of information ---but especially contextual features--- play an important role.
* JDIQ,Special Issue on Combating Digital Misinformation and Disinformation
FAKTA: An Automatic End-to-End Fact Checking System
Jun 07, 2019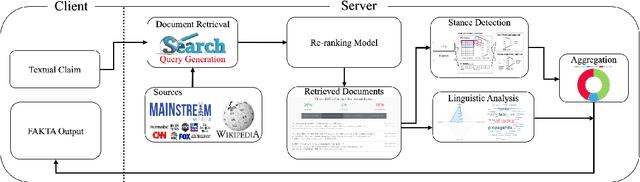
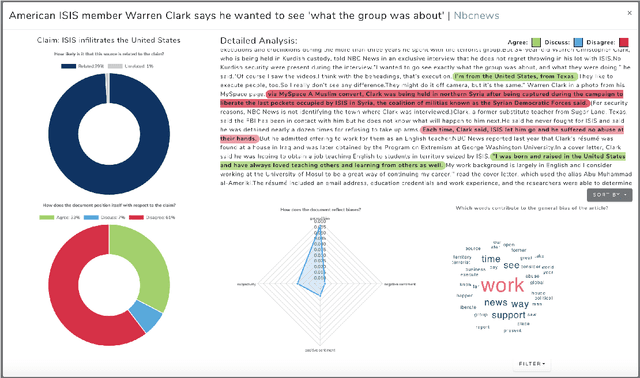
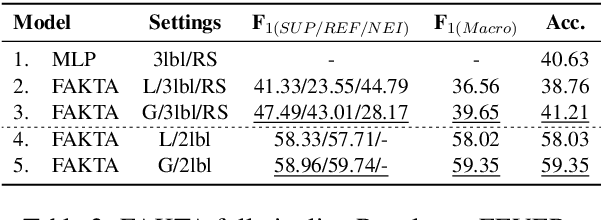
We present FAKTA which is a unified framework that integrates various components of a fact checking process: document retrieval from media sources with various types of reliability, stance detection of documents with respect to given claims, evidence extraction, and linguistic analysis. FAKTA predicts the factuality of given claims and provides evidence at the document and sentence level to explain its predictions
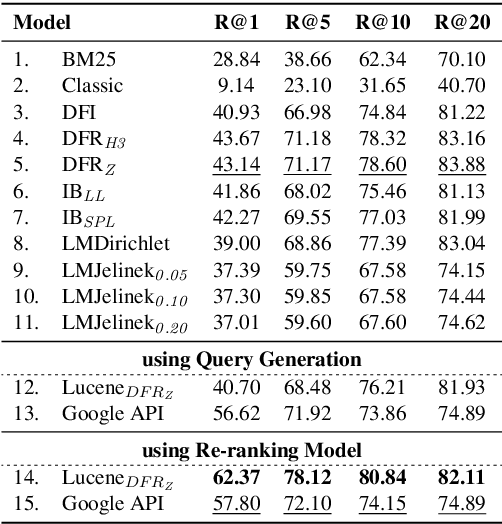
SemEval-2019 Task 8: Fact Checking in Community Question Answering Forums
May 25, 2019
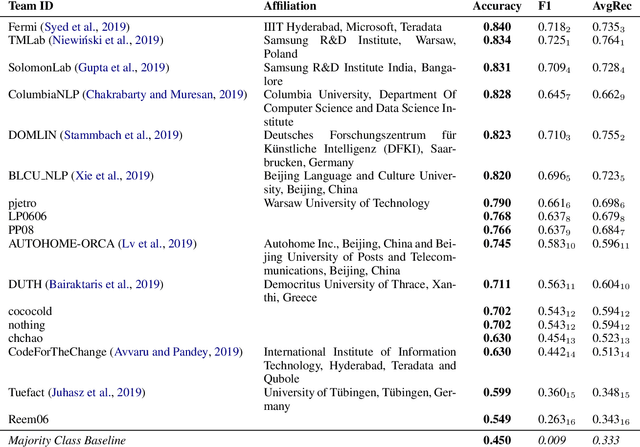
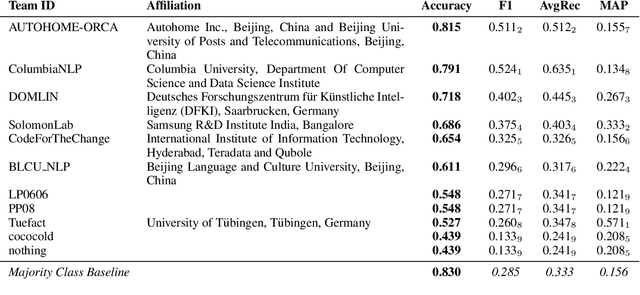
We present SemEval-2019 Task 8 on Fact Checking in Community Question Answering Forums, which features two subtasks. Subtask A is about deciding whether a question asks for factual information vs. an opinion/advice vs. just socializing. Subtask B asks to predict whether an answer to a factual question is true, false or not a proper answer. We received 17 official submissions for subtask A and 11 official submissions for Subtask B. For subtask A, all systems improved over the majority class baseline. For Subtask B, all systems were below a majority class baseline, but several systems were very close to it. The leaderboard and the data from the competition can be found at http://competitions.codalab.org/competitions/20022
Team QCRI-MIT at SemEval-2019 Task 4: Propaganda Analysis Meets Hyperpartisan News Detection
Apr 06, 2019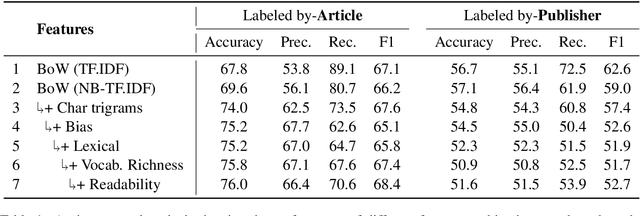
In this paper, we describe our submission to SemEval-2019 Task 4 on Hyperpartisan News Detection. Our system relies on a variety of engineered features originally used to detect propaganda. This is based on the assumption that biased messages are propagandistic in the sense that they promote a particular political cause or viewpoint. We trained a logistic regression model with features ranging from simple bag-of-words to vocabulary richness and text readability features. Our system achieved 72.9% accuracy on the test data that is annotated manually and 60.8% on the test data that is annotated with distant supervision. Additional experiments showed that significant performance improvements can be achieved with better feature pre-processing.
Adversarial Domain Adaptation for Stance Detection
Feb 06, 2019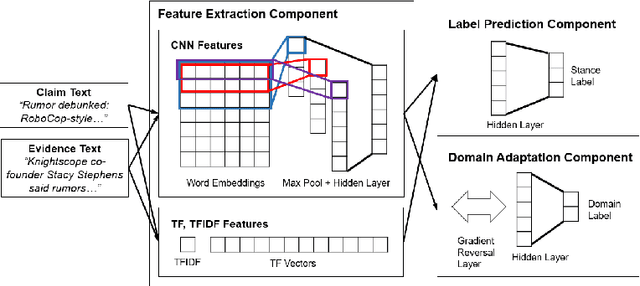
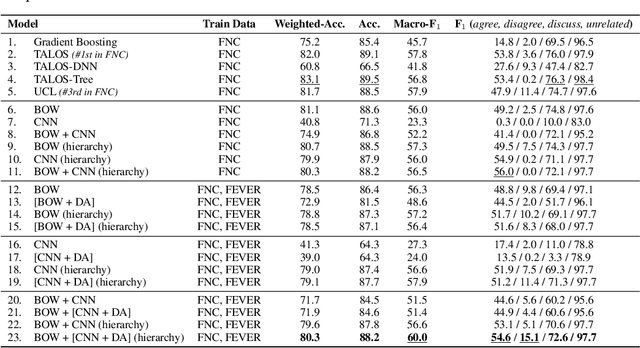
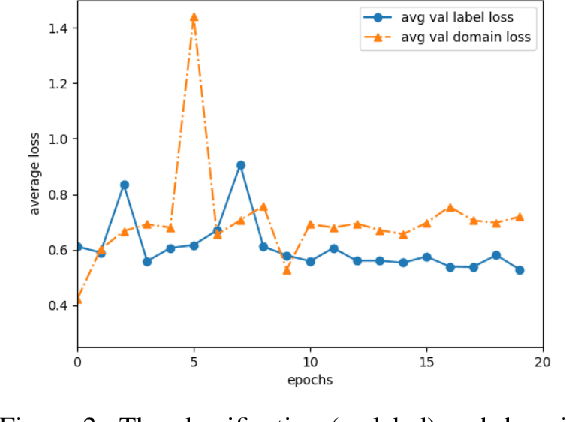
This paper studies the problem of stance detection which aims to predict the perspective (or stance) of a given document with respect to a given claim. Stance detection is a major component of automated fact checking. As annotating stances in different domains is a tedious and costly task, automatic methods based on machine learning are viable alternatives. In this paper, we focus on adversarial domain adaptation for stance detection where we assume there exists sufficient labeled data in the source domain and limited labeled data in the target domain. Extensive experiments on publicly available datasets show the effectiveness of our domain adaption model in transferring knowledge for accurate stance detection across domains.
Integrating Stance Detection and Fact Checking in a Unified Corpus
Apr 21, 2018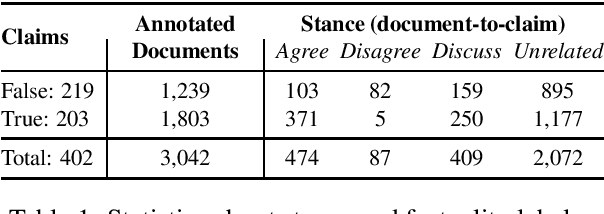
A reasonable approach for fact checking a claim involves retrieving potentially relevant documents from different sources (e.g., news websites, social media, etc.), determining the stance of each document with respect to the claim, and finally making a prediction about the claim's factuality by aggregating the strength of the stances, while taking the reliability of the source into account. Moreover, a fact checking system should be able to explain its decision by providing relevant extracts (rationales) from the documents. Yet, this setup is not directly supported by existing datasets, which treat fact checking, document retrieval, source credibility, stance detection and rationale extraction as independent tasks. In this paper, we support the interdependencies between these tasks as annotations in the same corpus. We implement this setup on an Arabic fact checking corpus, the first of its kind.
Automatic Stance Detection Using End-to-End Memory Networks
Apr 20, 2018

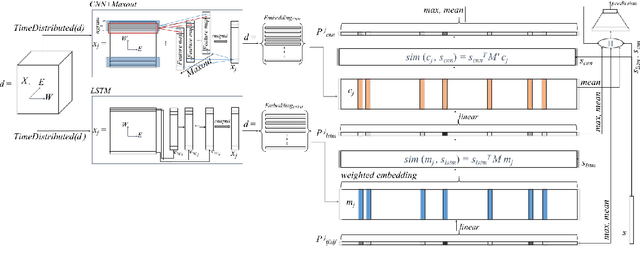
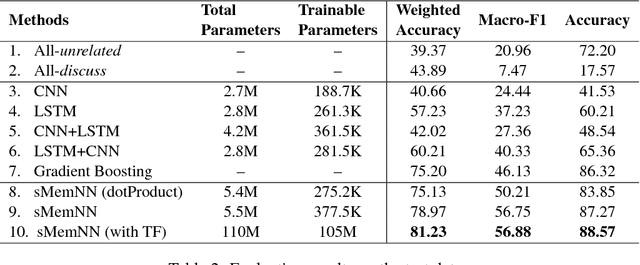
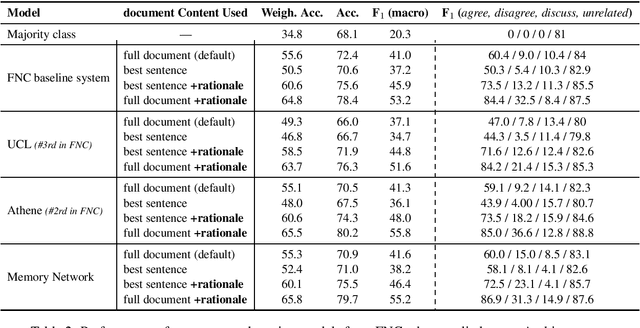
We present a novel end-to-end memory network for stance detection, which jointly (i) predicts whether a document agrees, disagrees, discusses or is unrelated with respect to a given target claim, and also (ii) extracts snippets of evidence for that prediction. The network operates at the paragraph level and integrates convolutional and recurrent neural networks, as well as a similarity matrix as part of the overall architecture. The experimental evaluation on the Fake News Challenge dataset shows state-of-the-art performance.
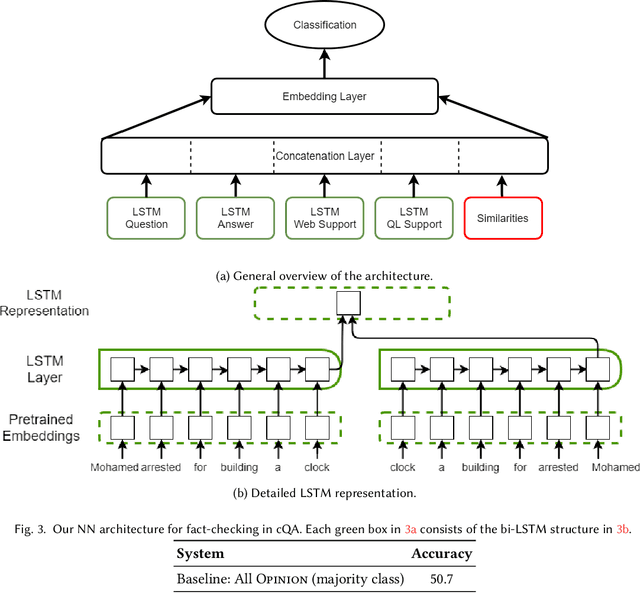
Fact Checking in Community Forums
Mar 08, 2018
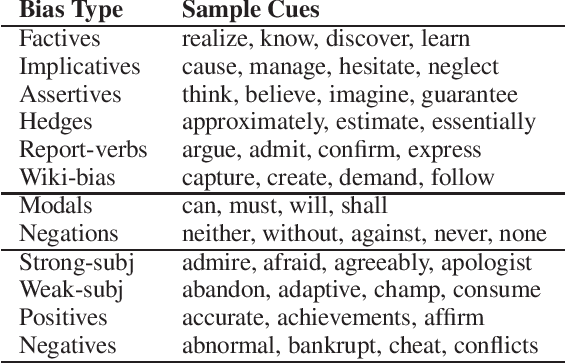
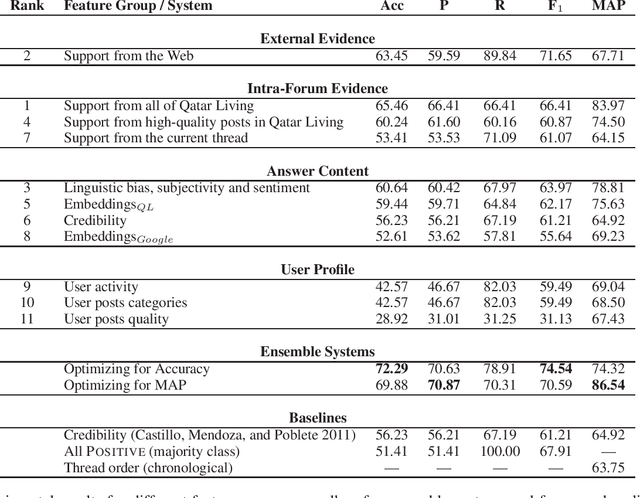

Community Question Answering (cQA) forums are very popular nowadays, as they represent effective means for communities around particular topics to share information. Unfortunately, this information is not always factual. Thus, here we explore a new dimension in the context of cQA, which has been ignored so far: checking the veracity of answers to particular questions in cQA forums. As this is a new problem, we create a specialized dataset for it. We further propose a novel multi-faceted model, which captures information from the answer content (what is said and how), from the author profile (who says it), from the rest of the community forum (where it is said), and from external authoritative sources of information (external support). Evaluation results show a MAP value of 86.54, which is 21 points absolute above the baseline.