Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Domain Adaptation for Stance Detection
Paper and Code
Feb 06, 2019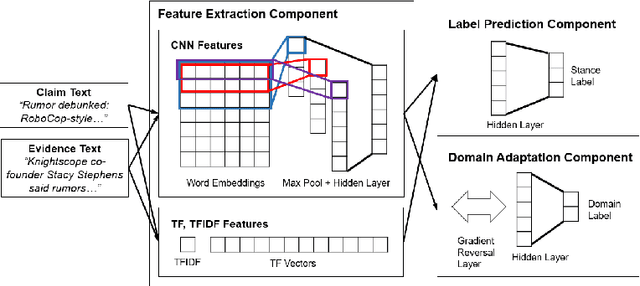
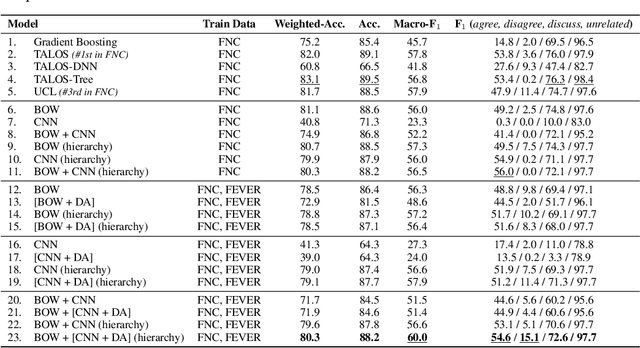
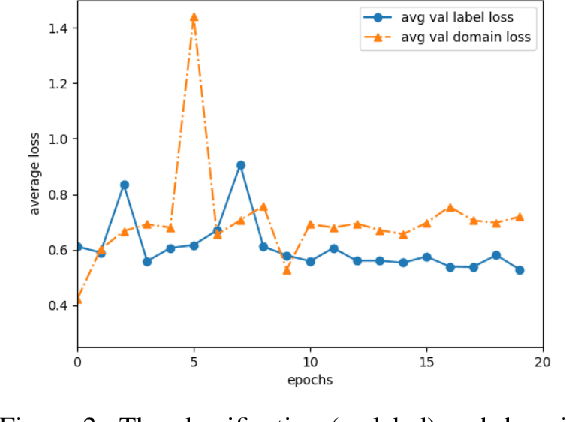
This paper studies the problem of stance detection which aims to predict the perspective (or stance) of a given document with respect to a given claim. Stance detection is a major component of automated fact checking. As annotating stances in different domains is a tedious and costly task, automatic methods based on machine learning are viable alternatives. In this paper, we focus on adversarial domain adaptation for stance detection where we assume there exists sufficient labeled data in the source domain and limited labeled data in the target domain. Extensive experiments on publicly available datasets show the effectiveness of our domain adaption model in transferring knowledge for accurate stance detection across domains.
* Accepted at NIPS-CL-2018, Stance Detection, Fact Checking,
Adversarial Domain Adaptation
View paper on