 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Computational Propaganda Detection
Jul 15, 2020

Propaganda campaigns aim at influencing people's mindset with the purpose of advancing a specific agenda. They exploit the anonymity of the Internet, the micro-profiling ability of social networks, and the ease of automatically creating and managing coordinated networks of accounts, to reach millions of social network users with persuasive messages, specifically targeted to topics each individual user is sensitive to, and ultimately influencing the outcome on a targeted issue. In this survey, we review the state of the art on computational propaganda detection from the perspective of Natural Language Processing and Network Analysis, arguing about the need for combined efforts between these communities. We further discuss current challenges and future research directions.
* propaganda detection, disinformation, misinformation, fake news, media bias
Overview of CheckThat! 2020: Automatic Identification and Verification of Claims in Social Media
Jul 15, 2020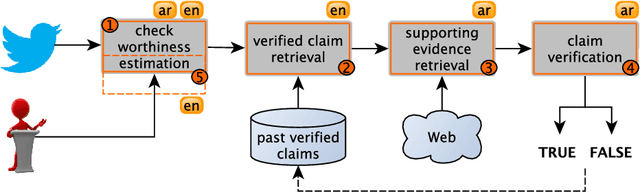
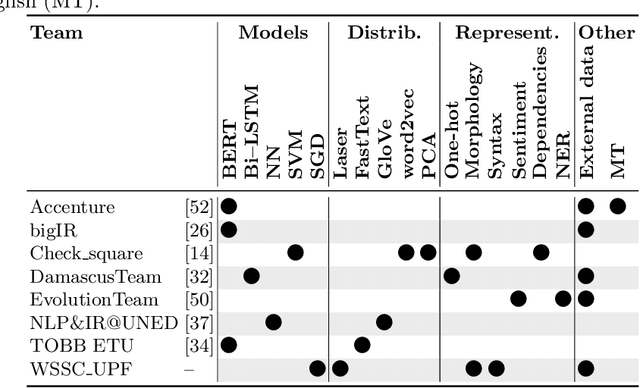
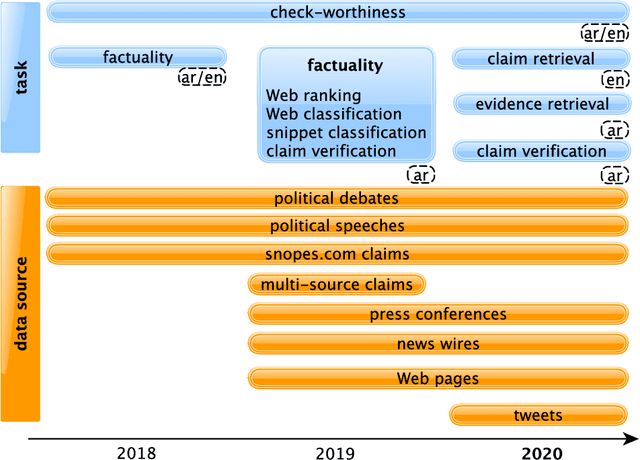
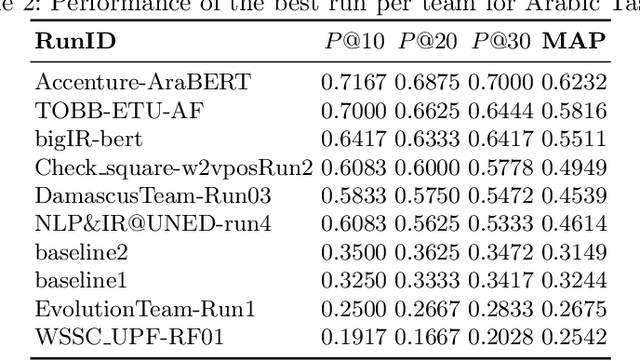
We present an overview of the third edition of the CheckThat! Lab at CLEF 2020. The lab featured five tasks in two different languages: English and Arabic. The first four tasks compose the full pipeline of claim verification in social media: Task 1 on check-worthiness estimation, Task 2 on retrieving previously fact-checked claims, Task 3 on evidence retrieval, and Task 4 on claim verification. The lab is completed with Task 5 on check-worthiness estimation in political debates and speeches. A total of 67 teams registered to participate in the lab (up from 47 at CLEF 2019), and 23 of them actually submitted runs (compared to 14 at CLEF 2019). Most teams used deep neural networks based on BERT, LSTMs, or CNNs, and achieved sizable improvements over the baselines on all tasks. Here we describe the tasks setup, the evaluation results, and a summary of the approaches used by the participants, and we discuss some lessons learned. Last but not least, we release to the research community all datasets from the lab as well as the evaluation scripts, which should enable further research in the important tasks of check-worthiness estimation and automatic claim verification.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
CheckThat! at CLEF 2020: Enabling the Automatic Identification and Verification of Claims in Social Media
Jan 21, 2020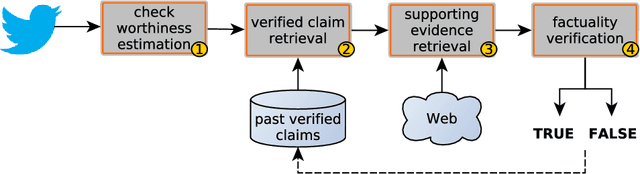
We describe the third edition of the CheckThat! Lab, which is part of the 2020 Cross-Language Evaluation Forum (CLEF). CheckThat! proposes four complementary tasks and a related task from previous lab editions, offered in English, Arabic, and Spanish. Task 1 asks to predict which tweets in a Twitter stream are worth fact-checking. Task 2 asks to determine whether a claim posted in a tweet can be verified using a set of previously fact-checked claims. Task 3 asks to retrieve text snippets from a given set of Web pages that would be useful for verifying a target tweet's claim. Task 4 asks to predict the veracity of a target tweet's claim using a set of Web pages and potentially useful snippets in them. Finally, the lab offers a fifth task that asks to predict the check-worthiness of the claims made in English political debates and speeches. CheckThat! features a full evaluation framework. The evaluation is carried out using mean average precision or precision at rank k for ranking tasks, and F1 for classification tasks.
* Computational journalism, Check-worthiness, Fact-checking, Veracity, CLEF-2020 CheckThat! Lab
Overview of the CLEF-2018 CheckThat! Lab on Automatic Identification and Verification of Political Claims. Task 1: Check-Worthiness
Aug 08, 2018
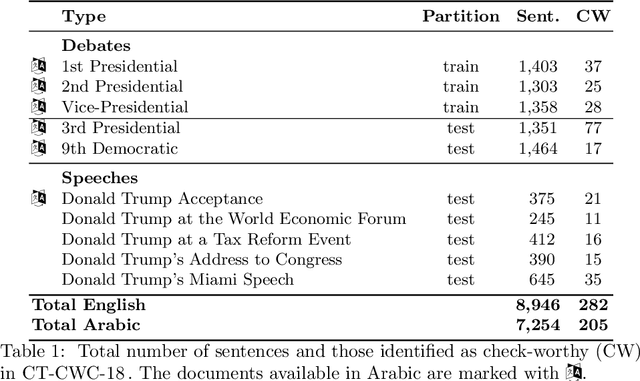

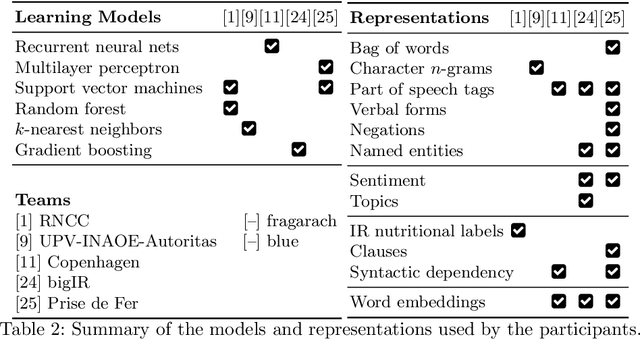
We present an overview of the CLEF-2018 CheckThat! Lab on Automatic Identification and Verification of Political Claims, with focus on Task 1: Check-Worthiness. The task asks to predict which claims in a political debate should be prioritized for fact-checking. In particular, given a debate or a political speech, the goal was to produce a ranked list of its sentences based on their worthiness for fact checking. We offered the task in both English and Arabic, based on debates from the 2016 US Presidential Campaign, as well as on some speeches during and after the campaign. A total of 30 teams registered to participate in the Lab and seven teams actually submitted systems for Task~1. The most successful approaches used by the participants relied on recurrent and multi-layer neural networks, as well as on combinations of distributional representations, on matchings claims' vocabulary against lexicons, and on measures of syntactic dependency. The best systems achieved mean average precision of 0.18 and 0.15 on the English and on the Arabic test datasets, respectively. This leaves large room for further improvement, and thus we release all datasets and the scoring scripts, which should enable further research in check-worthiness estimation.
* Computational journalism, Check-worthiness, Fact-checking, Veracity
ClaimRank: Detecting Check-Worthy Claims in Arabic and English
Apr 20, 2018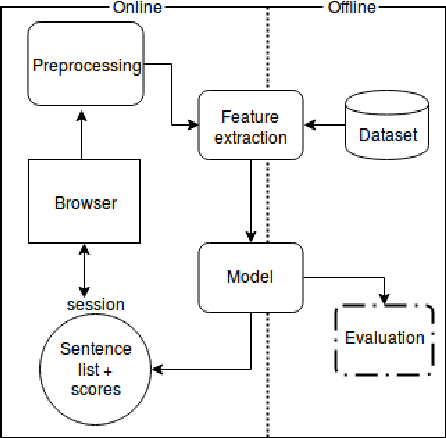

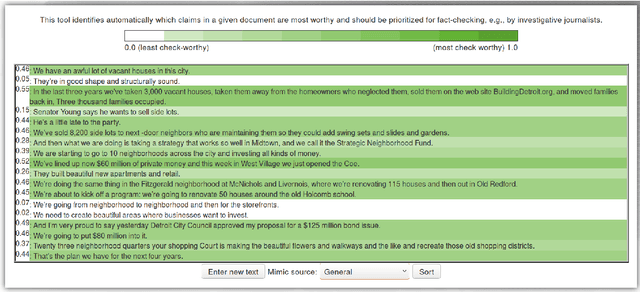
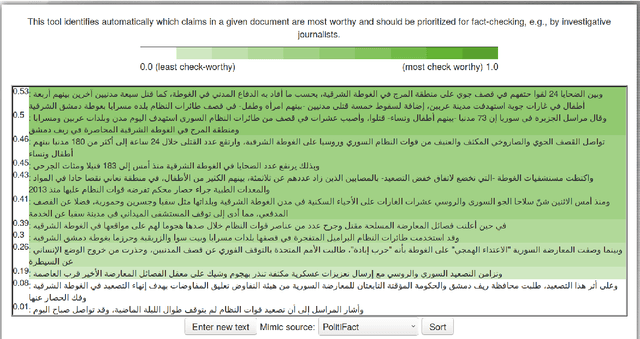
We present ClaimRank, an online system for detecting check-worthy claims. While originally trained on political debates, the system can work for any kind of text, e.g., interviews or regular news articles. Its aim is to facilitate manual fact-checking efforts by prioritizing the claims that fact-checkers should consider first. ClaimRank supports both Arabic and English, it is trained on actual annotations from nine reputable fact-checking organizations (PolitiFact, FactCheck, ABC, CNN, NPR, NYT, Chicago Tribune, The Guardian, and Washington Post), and thus it can mimic the claim selection strategies for each and any of them, as well as for the union of them all.
* Check-worthiness; Fact-Checking; Veracity; Community-Question Answering; Neural Networks; Arabic; English
Fact Checking in Community Forums
Mar 08, 2018
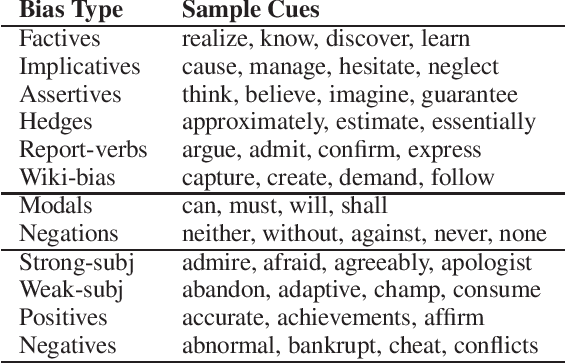
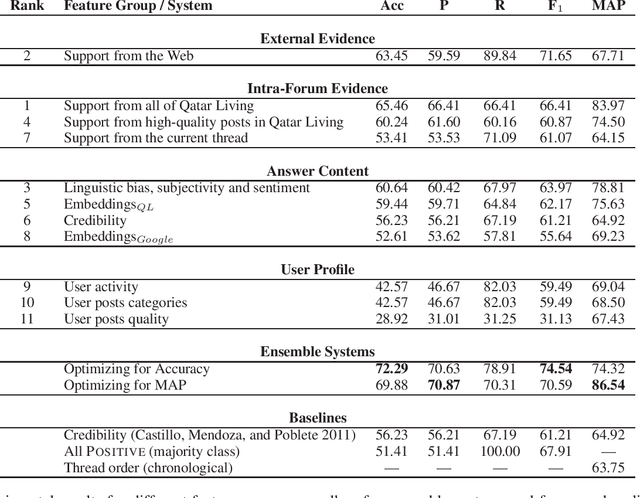

Community Question Answering (cQA) forums are very popular nowadays, as they represent effective means for communities around particular topics to share information. Unfortunately, this information is not always factual. Thus, here we explore a new dimension in the context of cQA, which has been ignored so far: checking the veracity of answers to particular questions in cQA forums. As this is a new problem, we create a specialized dataset for it. We further propose a novel multi-faceted model, which captures information from the answer content (what is said and how), from the author profile (who says it), from the rest of the community forum (where it is said), and from external authoritative sources of information (external support). Evaluation results show a MAP value of 86.54, which is 21 points absolute above the baseline.
Cross-Language Question Re-Ranking
Oct 04, 2017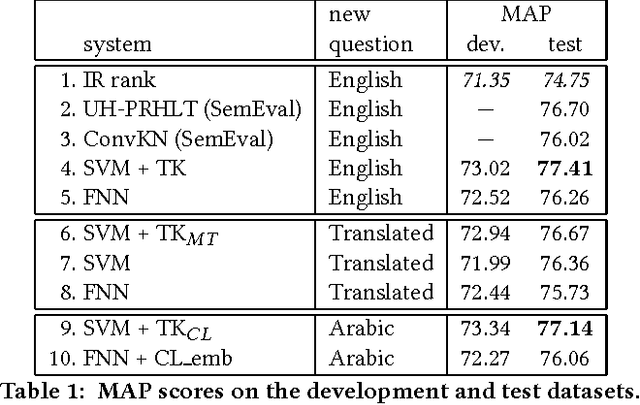
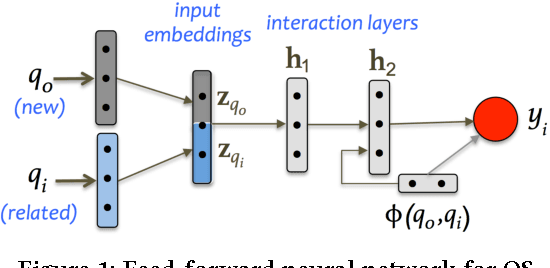
We study how to find relevant questions in community forums when the language of the new questions is different from that of the existing questions in the forum. In particular, we explore the Arabic-English language pair. We compare a kernel-based system with a feed-forward neural network in a scenario where a large parallel corpus is available for training a machine translation system, bilingual dictionaries, and cross-language word embeddings. We observe that both approaches degrade the performance of the system when working on the translated text, especially the kernel-based system, which depends heavily on a syntactic kernel. We address this issue using a cross-language tree kernel, which compares the original Arabic tree to the English trees of the related questions. We show that this kernel almost closes the performance gap with respect to the monolingual system. On the neural network side, we use the parallel corpus to train cross-language embeddings, which we then use to represent the Arabic input and the English related questions in the same space. The results also improve to close to those of the monolingual neural network. Overall, the kernel system shows a better performance compared to the neural network in all cases.
* SIGIR-2017; Community Question Answering; Cross-language Approaches; Question Retrieval; Kernel-based Methods; Neural Networks; Distributed Representations
Fully Automated Fact Checking Using External Sources
Oct 01, 2017
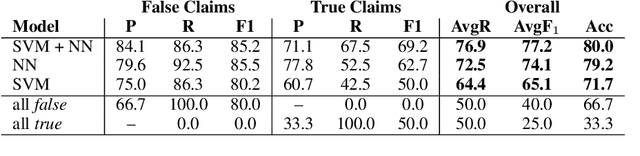
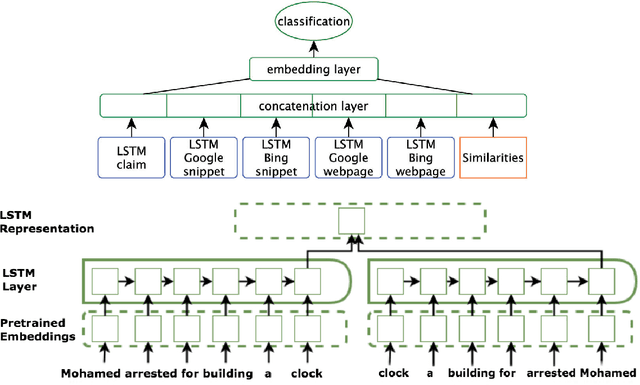
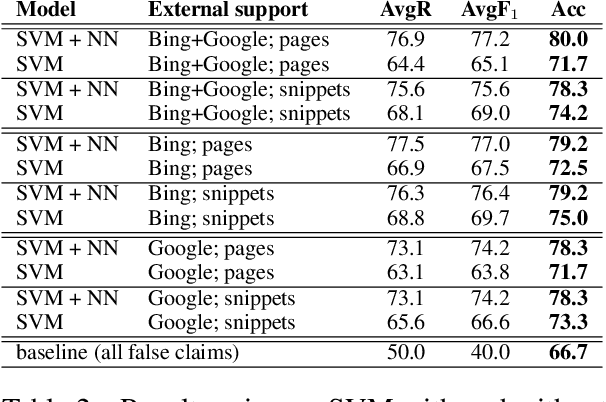
Given the constantly growing proliferation of false claims online in recent years, there has been also a growing research interest in automatically distinguishing false rumors from factually true claims. Here, we propose a general-purpose framework for fully-automatic fact checking using external sources, tapping the potential of the entire Web as a knowledge source to confirm or reject a claim. Our framework uses a deep neural network with LSTM text encoding to combine semantic kernels with task-specific embeddings that encode a claim together with pieces of potentially-relevant text fragments from the Web, taking the source reliability into account. The evaluation results show good performance on two different tasks and datasets: (i) rumor detection and (ii) fact checking of the answers to a question in community question answering forums.