 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUper Team at SemEval-2016 Task 3: Building a feature-rich system for community question answering
Sep 26, 2021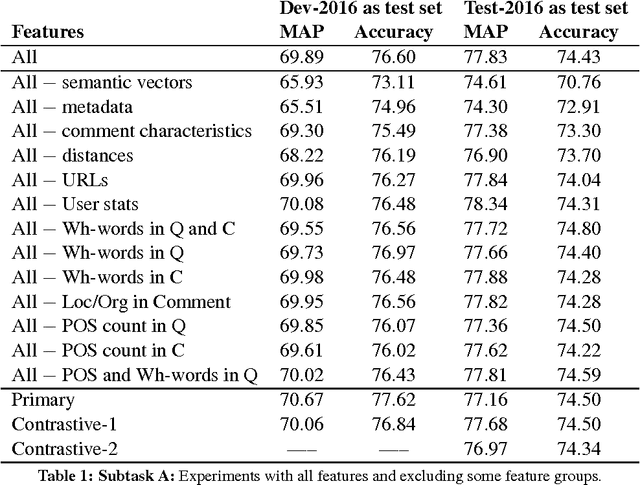
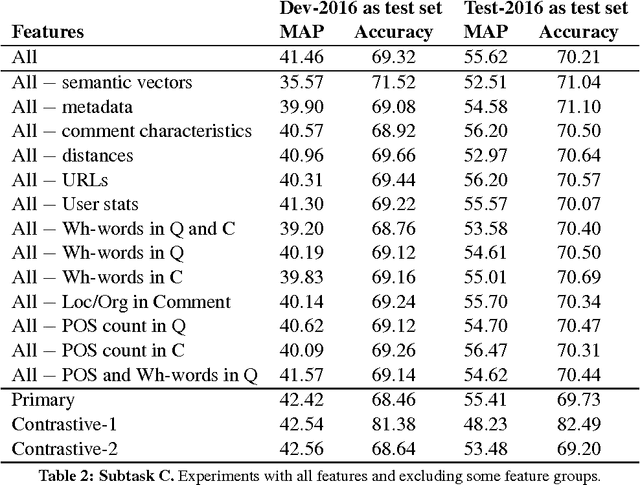
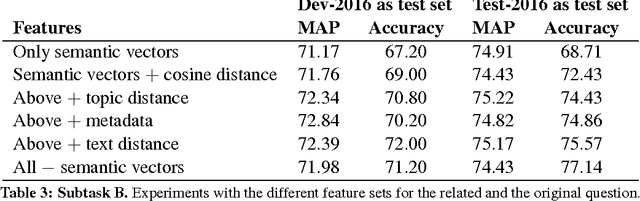
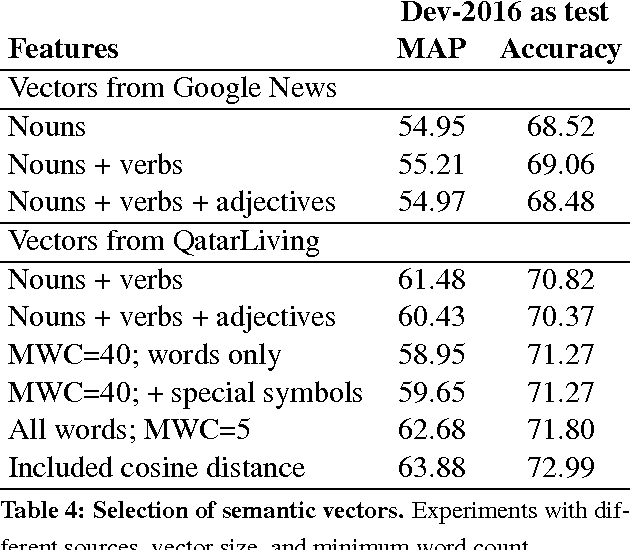
We present the system we built for participating in SemEval-2016 Task 3 on Community Question Answering. We achieved the best results on subtask C, and strong results on subtasks A and B, by combining a rich set of various types of features: semantic, lexical, metadata, and user-related. The most important group turned out to be the metadata for the question and for the comment, semantic vectors trained on QatarLiving data and similarities between the question and the comment for subtasks A and C, and between the original and the related question for Subtask B.
* community question answering, question-question similarity, question-comment similarity, answer reranking
A Context-Aware Approach for Detecting Check-Worthy Claims in Political Debates
Dec 14, 2019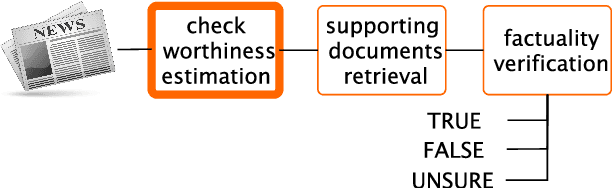

In the context of investigative journalism, we address the problem of automatically identifying which claims in a given document are most worthy and should be prioritized for fact-checking. Despite its importance, this is a relatively understudied problem. Thus, we create a new dataset of political debates, containing statements that have been fact-checked by nine reputable sources, and we train machine learning models to predict which claims should be prioritized for fact-checking, i.e., we model the problem as a ranking task. Unlike previous work, which has looked primarily at sentences in isolation, in this paper we focus on a rich input representation modeling the context: relationship between the target statement and the larger context of the debate, interaction between the opponents, and reaction by the moderator and by the public. Our experiments show state-of-the-art results, outperforming a strong rivaling system by a margin, while also confirming the importance of the contextual information.
* Check-worthiness; Fact-Checking; Veracity; Neural Networks. arXiv admin note: substantial text overlap with arXiv:1908.01328
ClaimRank: Detecting Check-Worthy Claims in Arabic and English
Apr 20, 2018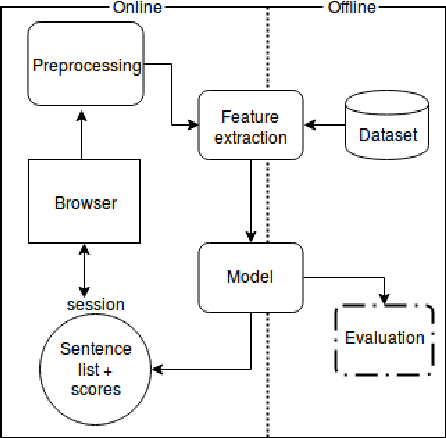

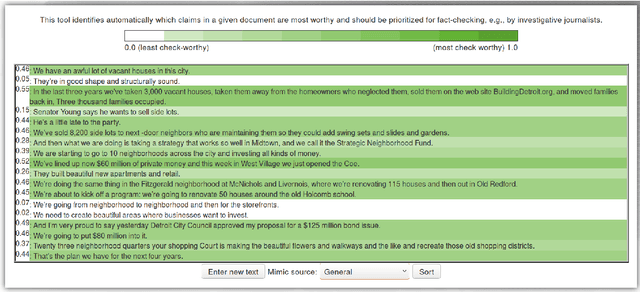
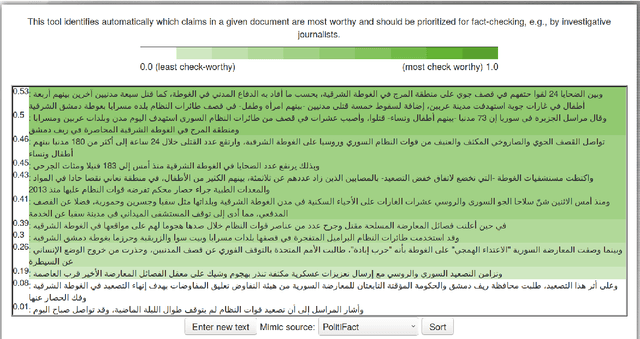
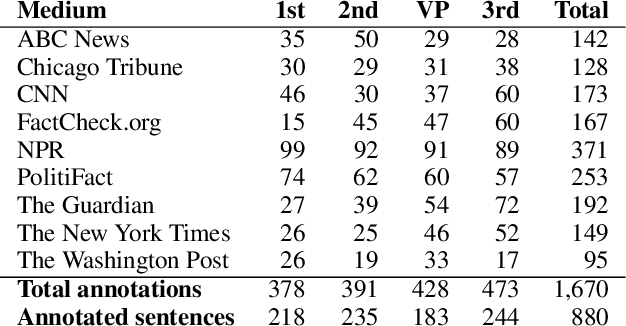
We present ClaimRank, an online system for detecting check-worthy claims. While originally trained on political debates, the system can work for any kind of text, e.g., interviews or regular news articles. Its aim is to facilitate manual fact-checking efforts by prioritizing the claims that fact-checkers should consider first. ClaimRank supports both Arabic and English, it is trained on actual annotations from nine reputable fact-checking organizations (PolitiFact, FactCheck, ABC, CNN, NPR, NYT, Chicago Tribune, The Guardian, and Washington Post), and thus it can mimic the claim selection strategies for each and any of them, as well as for the union of them all.
* Check-worthiness; Fact-Checking; Veracity; Community-Question Answering; Neural Networks; Arabic; English
We Built a Fake News & Click-bait Filter: What Happened Next Will Blow Your Mind!
Mar 10, 2018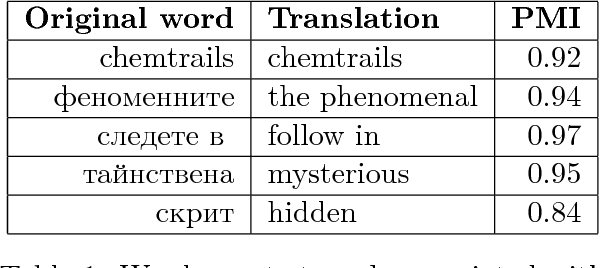
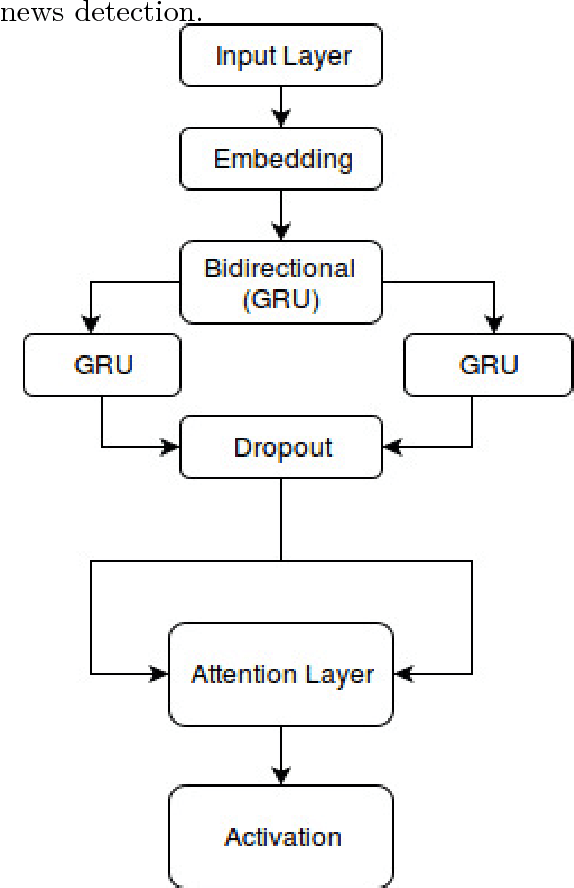
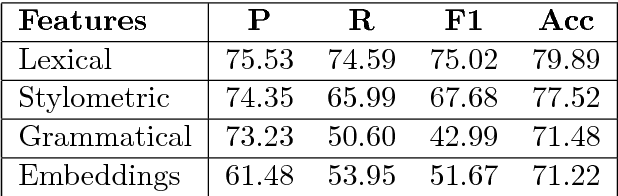
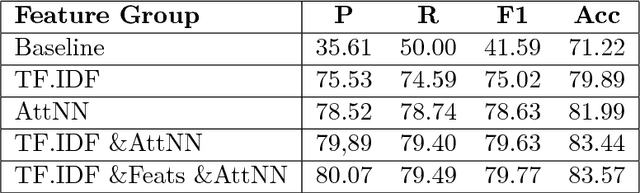
It is completely amazing! Fake news and click-baits have totally invaded the cyber space. Let us face it: everybody hates them for three simple reasons. Reason #2 will absolutely amaze you. What these can achieve at the time of election will completely blow your mind! Now, we all agree, this cannot go on, you know, somebody has to stop it. So, we did this research on fake news/click-bait detection and trust us, it is totally great research, it really is! Make no mistake. This is the best research ever! Seriously, come have a look, we have it all: neural networks, attention mechanism, sentiment lexicons, author profiling, you name it. Lexical features, semantic features, we absolutely have it all. And we have totally tested it, trust us! We have results, and numbers, really big numbers. The best numbers ever! Oh, and analysis, absolutely top notch analysis. Interested? Come read the shocking truth about fake news and click-bait in the Bulgarian cyber space. You won't believe what we have found!