 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Scene Graphs for Object Grounding of Natural Language Commands
Feb 04, 2026Robots are finding wider adoption in human environments, increasing the need for natural human-robot interaction. However, understanding a natural language command requires the robot to infer the intended task and how to decompose it into executable actions, and to ground those actions in the robot's knowledge of the environment, including relevant objects, agents, and locations. This challenge can be addressed by combining the capabilities of Large language models (LLMs) to understand natural language with 3D scene graphs (3DSGs) for grounding inferred actions in a semantic representation of the environment. However, many 3DSGs lack explicit spatial relations between objects, even though humans often rely on these relations to describe an environment. This paper investigates whether incorporating open- or closed-vocabulary spatial relations into 3DSGs can improve the ability of LLMs to interpret natural language commands. To address this, we propose an LLM-based pipeline for target object grounding from open-vocabulary language commands and a vision language model (VLM)-based pipeline to add open-vocabulary spatial edges to 3DSGs from images captured while mapping. Finally, two LLMs are evaluated in a study assessing their performance on the downstream task of target object grounding. Our study demonstrates that explicit spatial relations improve the ability of LLMs to ground objects. Moreover, open-vocabulary relation generation with VLMs proves feasible from robot-captured images, but their advantage over closed-vocabulary relations is found to be limited.
Can We Improve Educational Diagram Generation with In-Context Examples? Not if a Hallucination Spoils the Bunch
Jan 28, 2026Generative artificial intelligence (AI) has found a widespread use in computing education; at the same time, quality of generated materials raises concerns among educators and students. This study addresses this issue by introducing a novel method for diagram code generation with in-context examples based on the Rhetorical Structure Theory (RST), which aims to improve diagram generation by aligning models' output with user expectations. Our approach is evaluated by computer science educators, who assessed 150 diagrams generated with large language models (LLMs) for logical organization, connectivity, layout aesthetic, and AI hallucination. The assessment dataset is additionally investigated for its utility in automated diagram evaluation. The preliminary results suggest that our method decreases the rate of factual hallucination and improves diagram faithfulness to provided context; however, due to LLMs' stochasticity, the quality of the generated diagrams varies. Additionally, we present an in-depth analysis and discussion on the connection between AI hallucination and the quality of generated diagrams, which reveals that text contexts of higher complexity lead to higher rates of hallucination and LLMs often fail to detect mistakes in their output.
Do Visual-Language Maps Capture Latent Semantics?
Mar 15, 2024Visual-language models (VLMs) have recently been introduced in robotic mapping by using the latent representations, i.e., embeddings, of the VLMs to represent the natural language semantics in the map. The main benefit is moving beyond a small set of human-created labels toward open-vocabulary scene understanding. While there is anecdotal evidence that maps built this way support downstream tasks, such as navigation, rigorous analysis of the quality of the maps using these embeddings is lacking. We investigate two critical properties of map quality: queryability and consistency. The evaluation of queryability addresses the ability to retrieve information from the embeddings. We investigate two aspects of consistency: intra-map consistency and inter-map consistency. Intra-map consistency captures the ability of the embeddings to represent abstract semantic classes, and inter-map consistency captures the generalization properties of the representation. In this paper, we propose a way to analyze the quality of maps created using VLMs, which forms an open-source benchmark to be used when proposing new open-vocabulary map representations. We demonstrate the benchmark by evaluating the maps created by two state-of-the-art methods, VLMaps and OpenScene, using two encoders, LSeg and OpenSeg, using real-world data from the Matterport3D data set. We find that OpenScene outperforms VLMaps with both encoders, and LSeg outperforms OpenSeg with both methods.
Discrete Latent Structure in Neural Networks
Jan 18, 2023


Many types of data from fields including natural language processing, computer vision, and bioinformatics, are well represented by discrete, compositional structures such as trees, sequences, or matchings. Latent structure models are a powerful tool for learning to extract such representations, offering a way to incorporate structural bias, discover insight about the data, and interpret decisions. However, effective training is challenging, as neural networks are typically designed for continuous computation. This text explores three broad strategies for learning with discrete latent structure: continuous relaxation, surrogate gradients, and probabilistic estimation. Our presentation relies on consistent notations for a wide range of models. As such, we reveal many new connections between latent structure learning strategies, showing how most consist of the same small set of fundamental building blocks, but use them differently, leading to substantially different applicability and properties.
Modeling Structure with Undirected Neural Networks
Feb 08, 2022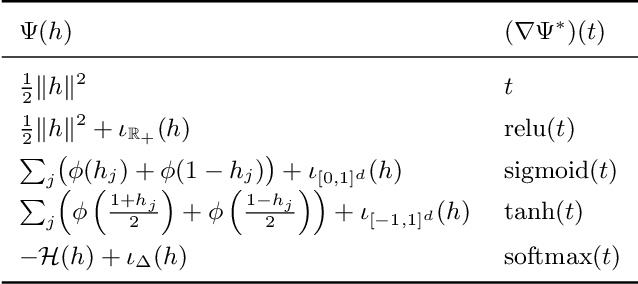
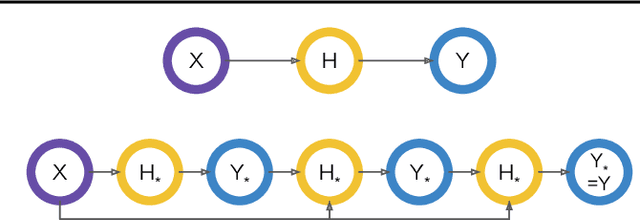

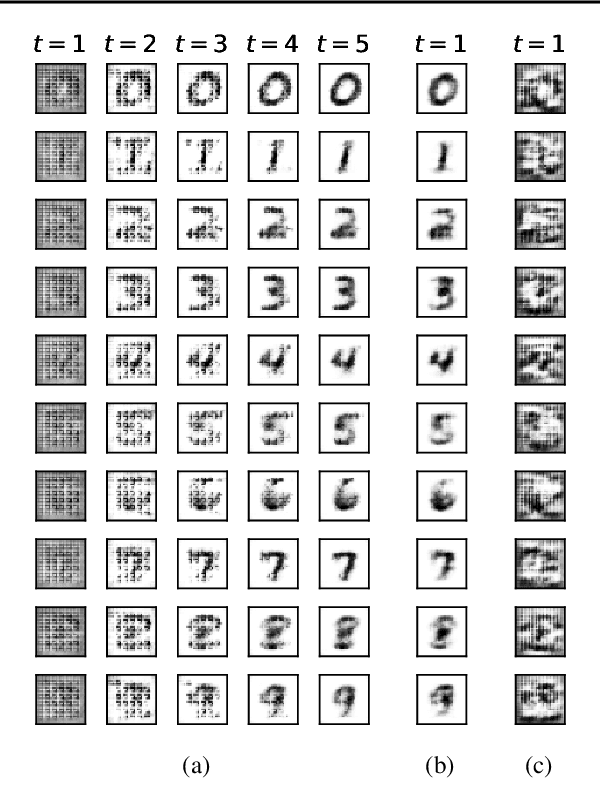
Neural networks are powerful function estimators, leading to their status as a paradigm of choice for modeling structured data. However, unlike other structured representations that emphasize the modularity of the problem -- e.g., factor graphs -- neural networks are usually monolithic mappings from inputs to outputs, with a fixed computation order. This limitation prevents them from capturing different directions of computation and interaction between the modeled variables. In this paper, we combine the representational strengths of factor graphs and of neural networks, proposing undirected neural networks (UNNs): a flexible framework for specifying computations that can be performed in any order. For particular choices, our proposed models subsume and extend many existing architectures: feed-forward, recurrent, self-attention networks, auto-encoders, and networks with implicit layers. We demonstrate the effectiveness of undirected neural architectures, both unstructured and structured, on a range of tasks: tree-constrained dependency parsing, convolutional image classification, and sequence completion with attention. By varying the computation order, we show how a single UNN can be used both as a classifier and a prototype generator, and how it can fill in missing parts of an input sequence, making them a promising field for further research.
SUper Team at SemEval-2016 Task 3: Building a feature-rich system for community question answering
Sep 26, 2021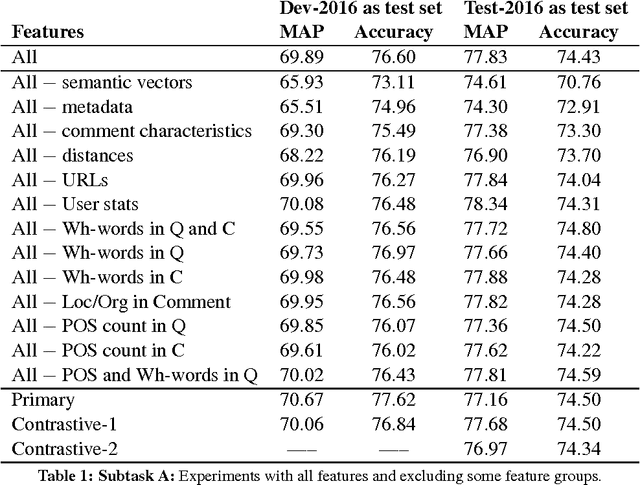
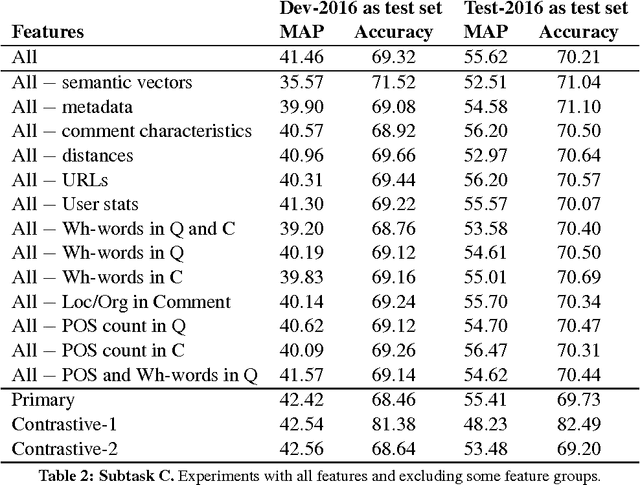
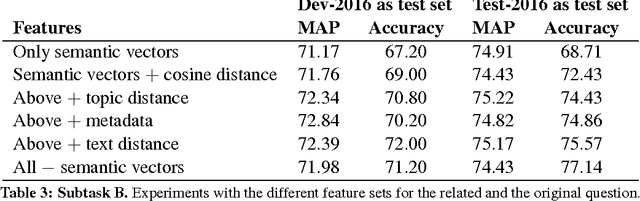
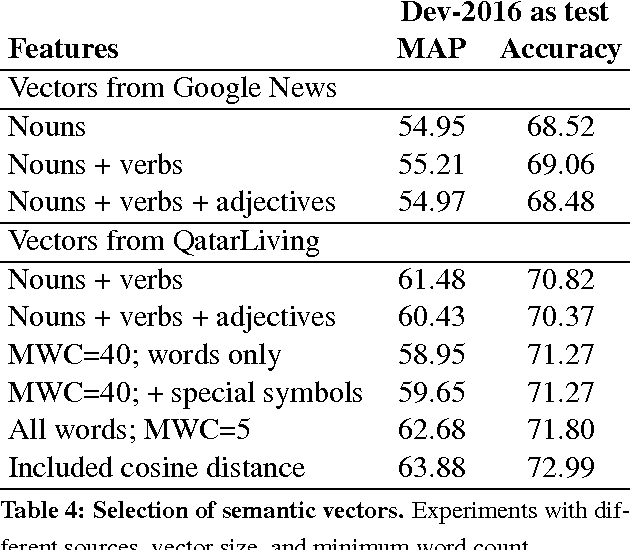
We present the system we built for participating in SemEval-2016 Task 3 on Community Question Answering. We achieved the best results on subtask C, and strong results on subtasks A and B, by combining a rich set of various types of features: semantic, lexical, metadata, and user-related. The most important group turned out to be the metadata for the question and for the comment, semantic vectors trained on QatarLiving data and similarities between the question and the comment for subtasks A and C, and between the original and the related question for Subtask B.
* community question answering, question-question similarity, question-comment similarity, answer reranking
Understanding the Mechanics of SPIGOT: Surrogate Gradients for Latent Structure Learning
Oct 05, 2020

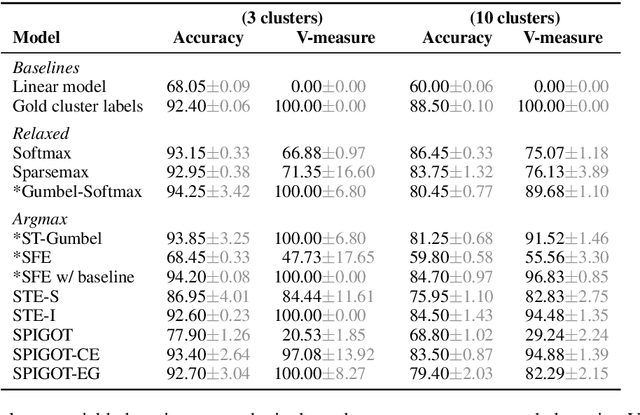
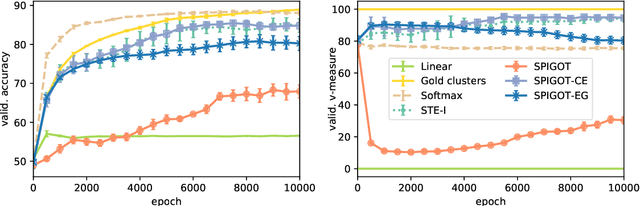
Latent structure models are a powerful tool for modeling language data: they can mitigate the error propagation and annotation bottleneck in pipeline systems, while simultaneously uncovering linguistic insights about the data. One challenge with end-to-end training of these models is the argmax operation, which has null gradient. In this paper, we focus on surrogate gradients, a popular strategy to deal with this problem. We explore latent structure learning through the angle of pulling back the downstream learning objective. In this paradigm, we discover a principled motivation for both the straight-through estimator (STE) as well as the recently-proposed SPIGOT - a variant of STE for structured models. Our perspective leads to new algorithms in the same family. We empirically compare the known and the novel pulled-back estimators against the popular alternatives, yielding new insight for practitioners and revealing intriguing failure cases.
Automatic Fact-Checking Using Context and Discourse Information
Aug 04, 2019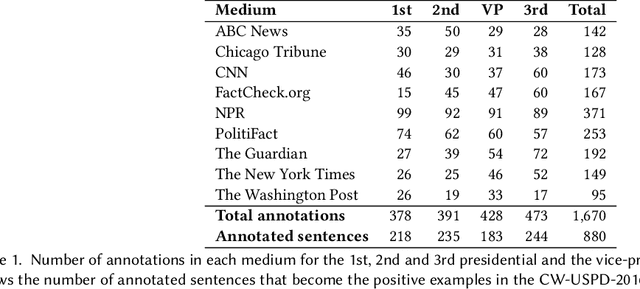
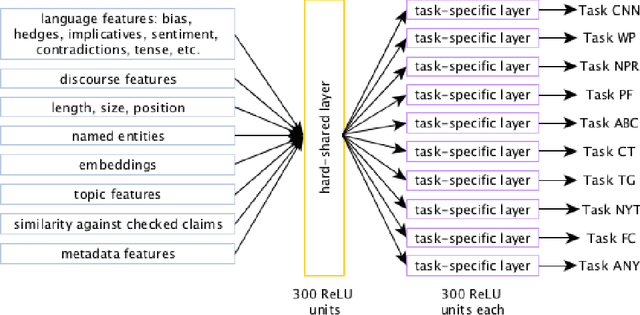

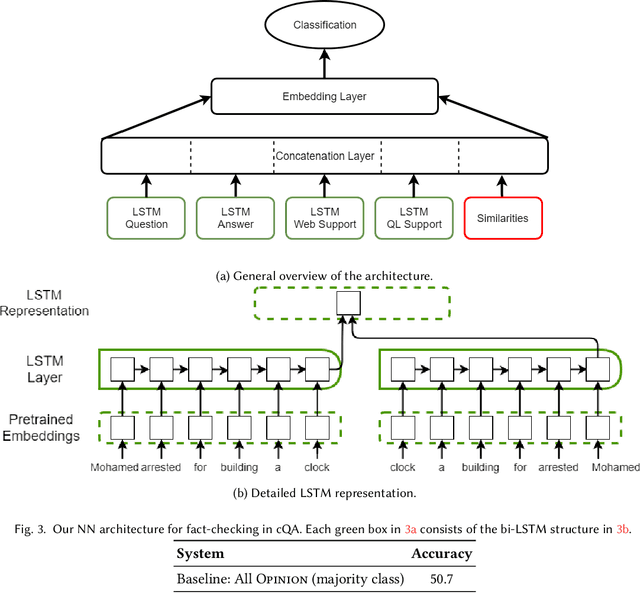
We study the problem of automatic fact-checking, paying special attention to the impact of contextual and discourse information. We address two related tasks: (i) detecting check-worthy claims, and (ii) fact-checking claims. We develop supervised systems based on neural networks, kernel-based support vector machines, and combinations thereof, which make use of rich input representations in terms of discourse cues and contextual features. For the check-worthiness estimation task, we focus on political debates, and we model the target claim in the context of the full intervention of a participant and the previous and the following turns in the debate, taking into account contextual meta information. For the fact-checking task, we focus on answer verification in a community forum, and we model the veracity of the answer with respect to the entire question--answer thread in which it occurs as well as with respect to other related posts from the entire forum. We develop annotated datasets for both tasks and we run extensive experimental evaluation, confirming that both types of information ---but especially contextual features--- play an important role.
* JDIQ,Special Issue on Combating Digital Misinformation and Disinformation
Scheduled Sampling for Transformers
Jun 18, 2019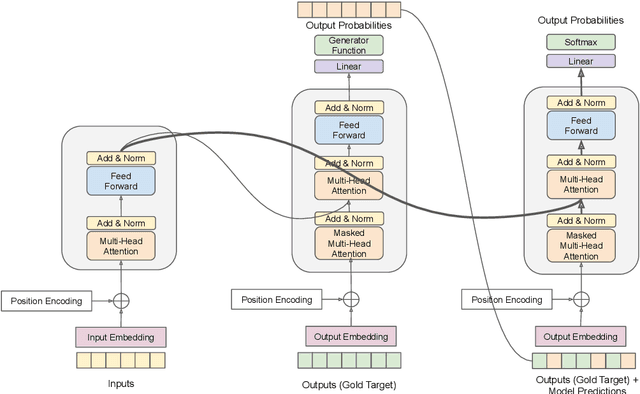

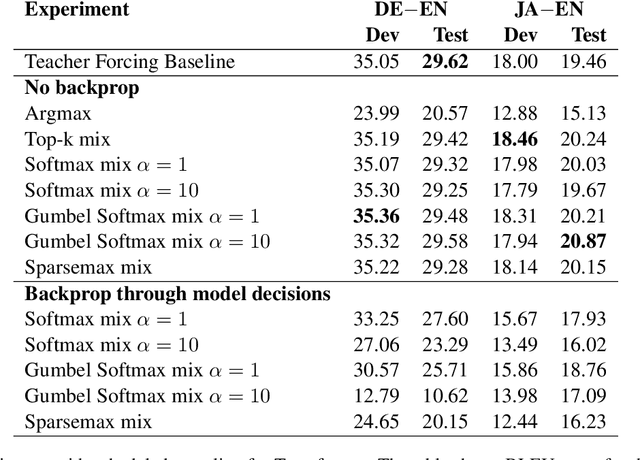
Scheduled sampling is a technique for avoiding one of the known problems in sequence-to-sequence generation: exposure bias. It consists of feeding the model a mix of the teacher forced embeddings and the model predictions from the previous step in training time. The technique has been used for improving the model performance with recurrent neural networks (RNN). In the Transformer model, unlike the RNN, the generation of a new word attends to the full sentence generated so far, not only to the last word, and it is not straightforward to apply the scheduled sampling technique. We propose some structural changes to allow scheduled sampling to be applied to Transformer architecture, via a two-pass decoding strategy. Experiments on two language pairs achieve performance close to a teacher-forcing baseline and show that this technique is promising for further exploration.
SemEval-2019 Task 8: Fact Checking in Community Question Answering Forums
May 25, 2019
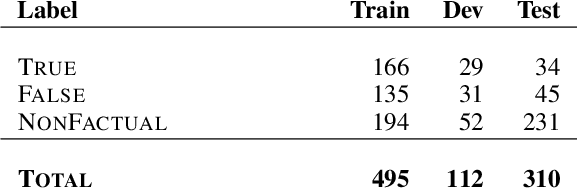
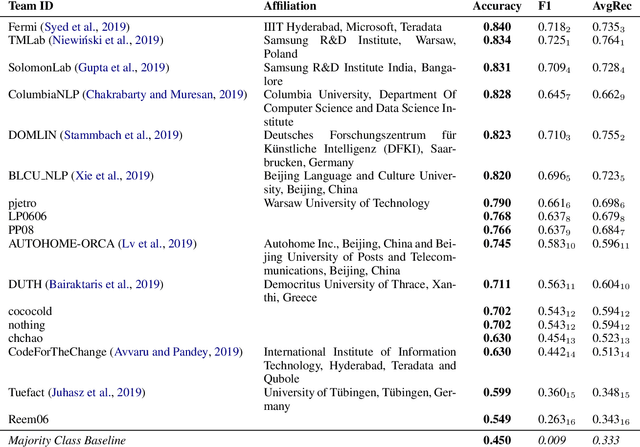
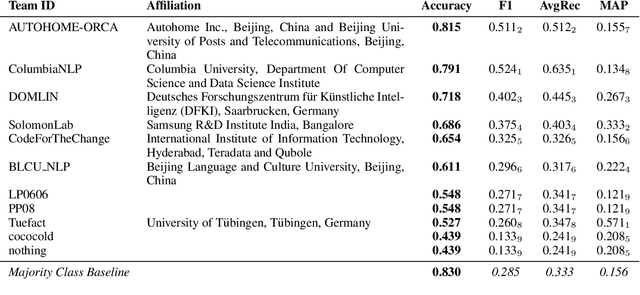
We present SemEval-2019 Task 8 on Fact Checking in Community Question Answering Forums, which features two subtasks. Subtask A is about deciding whether a question asks for factual information vs. an opinion/advice vs. just socializing. Subtask B asks to predict whether an answer to a factual question is true, false or not a proper answer. We received 17 official submissions for subtask A and 11 official submissions for Subtask B. For subtask A, all systems improved over the majority class baseline. For Subtask B, all systems were below a majority class baseline, but several systems were very close to it. The leaderboard and the data from the competition can be found at http://competitions.codalab.org/competitions/20022