 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUper Team at SemEval-2016 Task 3: Building a feature-rich system for community question answering
Sep 26, 2021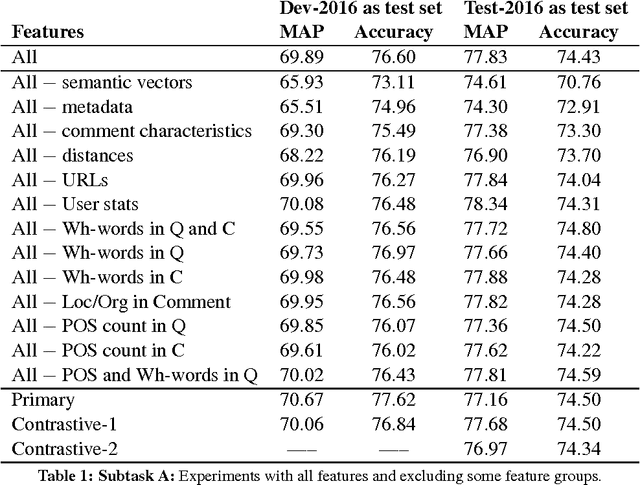
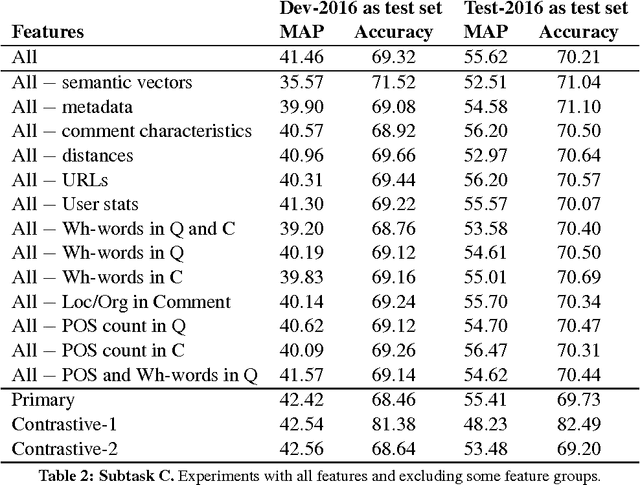
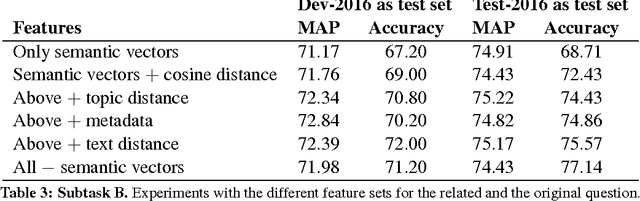
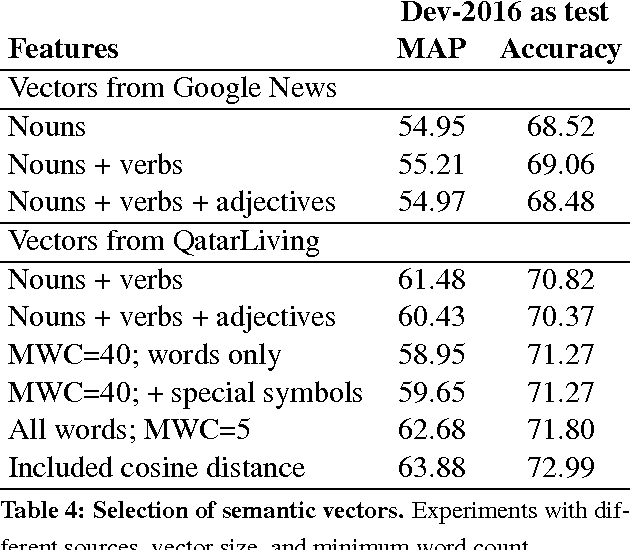
We present the system we built for participating in SemEval-2016 Task 3 on Community Question Answering. We achieved the best results on subtask C, and strong results on subtasks A and B, by combining a rich set of various types of features: semantic, lexical, metadata, and user-related. The most important group turned out to be the metadata for the question and for the comment, semantic vectors trained on QatarLiving data and similarities between the question and the comment for subtasks A and C, and between the original and the related question for Subtask B.
* community question answering, question-question similarity, question-comment similarity, answer reranking
Building Chatbots from Forum Data: Model Selection Using Question Answering Metrics
Oct 02, 2017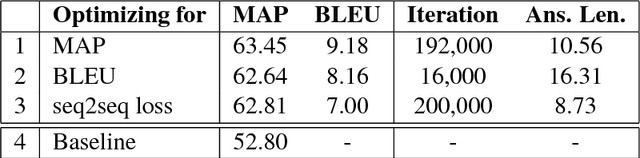

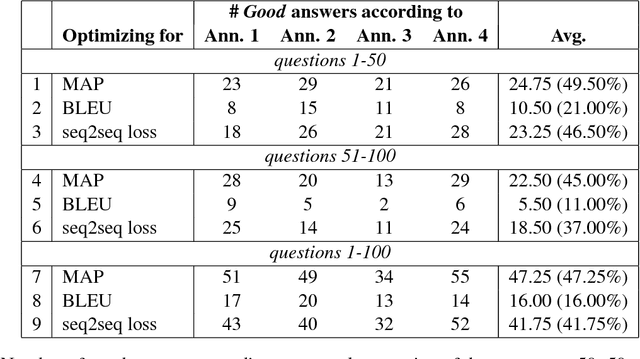

We propose to use question answering (QA) data from Web forums to train chatbots from scratch, i.e., without dialog training data. First, we extract pairs of question and answer sentences from the typically much longer texts of questions and answers in a forum. We then use these shorter texts to train seq2seq models in a more efficient way. We further improve the parameter optimization using a new model selection strategy based on QA measures. Finally, we propose to use extrinsic evaluation with respect to a QA task as an automatic evaluation method for chatbots. The evaluation shows that the model achieves a MAP of 63.5% on the extrinsic task. Moreover, it can answer correctly 49.5% of the questions when they are similar to questions asked in the forum, and 47.3% of the questions when they are more conversational in style.