 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUper Team at SemEval-2016 Task 3: Building a feature-rich system for community question answering
Sep 26, 2021
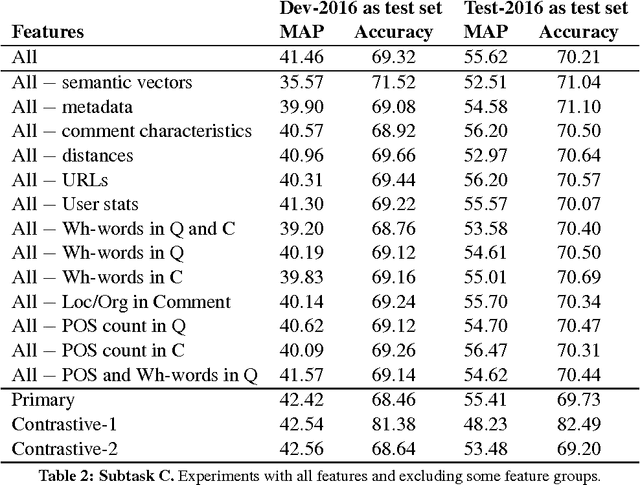
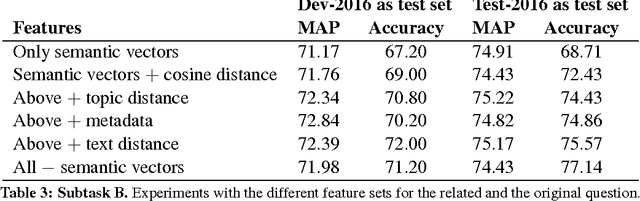
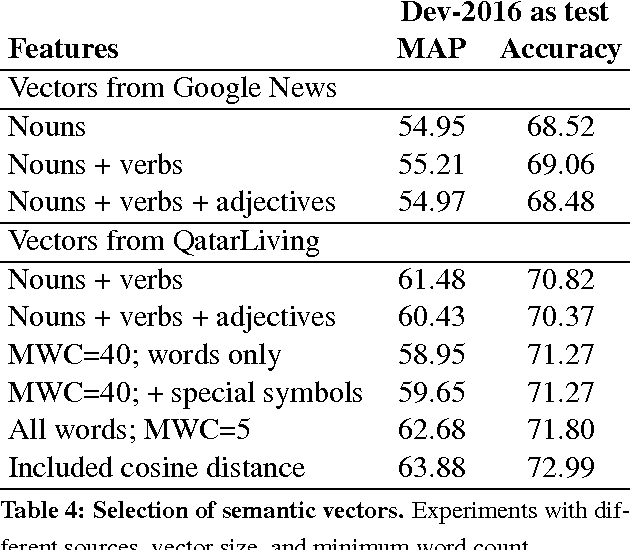
We present the system we built for participating in SemEval-2016 Task 3 on Community Question Answering. We achieved the best results on subtask C, and strong results on subtasks A and B, by combining a rich set of various types of features: semantic, lexical, metadata, and user-related. The most important group turned out to be the metadata for the question and for the comment, semantic vectors trained on QatarLiving data and similarities between the question and the comment for subtasks A and C, and between the original and the related question for Subtask B.
* community question answering, question-question similarity, question-comment similarity, answer reranking
The Case for Being Average: A Mediocrity Approach to Style Masking and Author Obfuscation
Jul 28, 2017
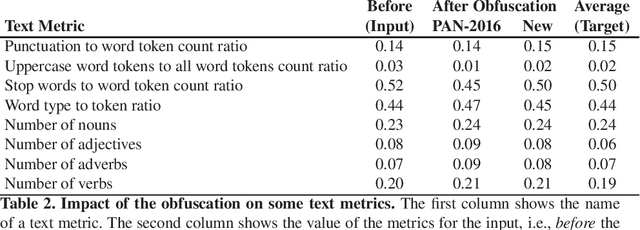
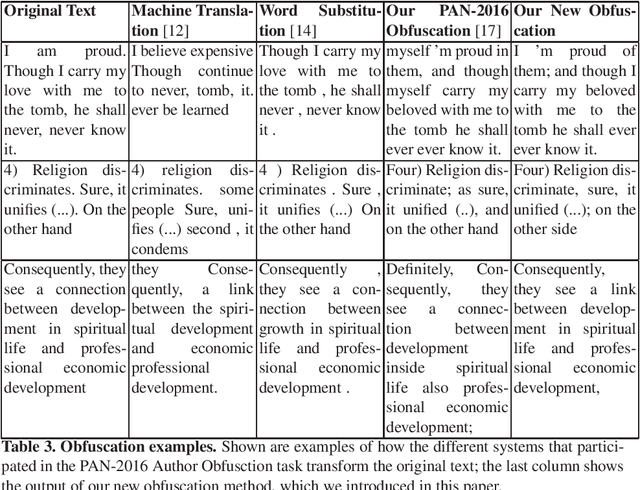
Users posting online expect to remain anonymous unless they have logged in, which is often needed for them to be able to discuss freely on various topics. Preserving the anonymity of a text's writer can be also important in some other contexts, e.g., in the case of witness protection or anonymity programs. However, each person has his/her own style of writing, which can be analyzed using stylometry, and as a result, the true identity of the author of a piece of text can be revealed even if s/he has tried to hide it. Thus, it could be helpful to design automatic tools that can help a person obfuscate his/her identity when writing text. In particular, here we propose an approach that changes the text, so that it is pushed towards average values for some general stylometric characteristics, thus making the use of these characteristics less discriminative. The approach consists of three main steps: first, we calculate the values for some popular stylometric metrics that can indicate authorship; then we apply various transformations to the text, so that these metrics are adjusted towards the average level, while preserving the semantics and the soundness of the text; and finally, we add random noise. This approach turned out to be very efficient, and yielded the best performance on the Author Obfuscation task at the PAN-2016 competition.
Large-Scale Goodness Polarity Lexicons for Community Question Answering
Jul 20, 2017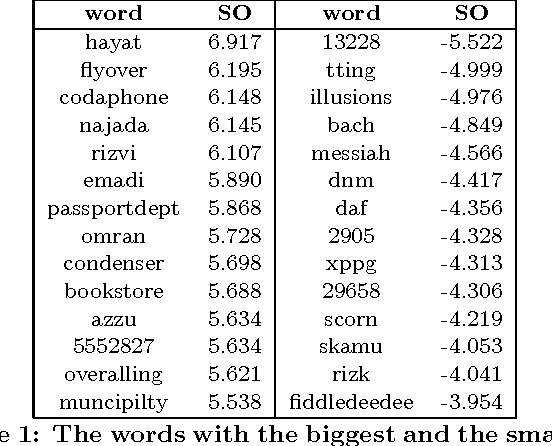
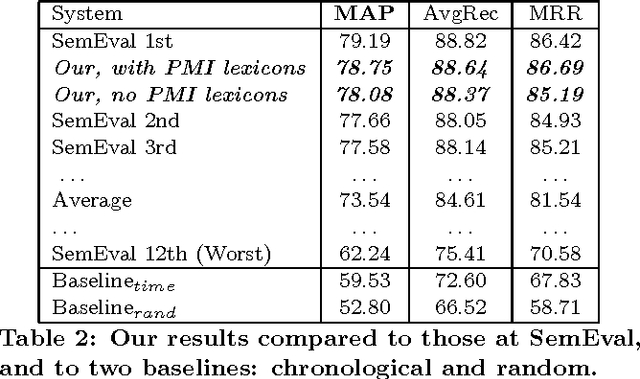
We transfer a key idea from the field of sentiment analysis to a new domain: community question answering (cQA). The cQA task we are interested in is the following: given a question and a thread of comments, we want to re-rank the comments so that the ones that are good answers to the question would be ranked higher than the bad ones. We notice that good vs. bad comments use specific vocabulary and that one can often predict the goodness/badness of a comment even ignoring the question, based on the comment contents only. This leads us to the idea to build a good/bad polarity lexicon as an analogy to the positive/negative sentiment polarity lexicons, commonly used in sentiment analysis. In particular, we use pointwise mutual information in order to build large-scale goodness polarity lexicons in a semi-supervised manner starting with a small number of initial seeds. The evaluation results show an improvement of 0.7 MAP points absolute over a very strong baseline and state-of-the art performance on SemEval-2016 Task 3.