 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025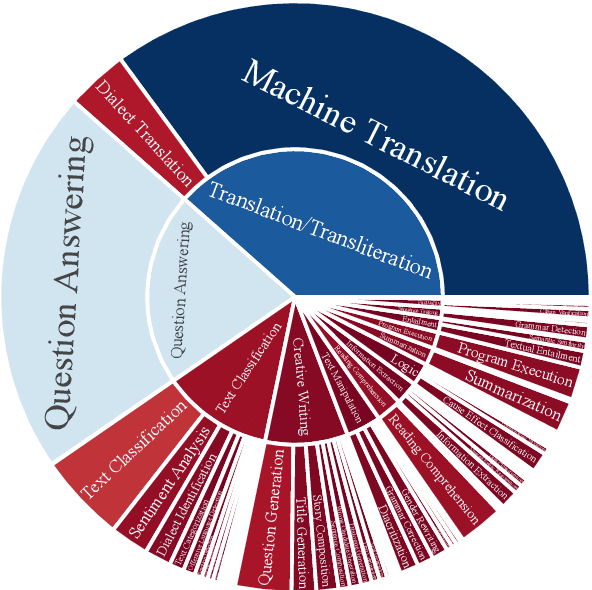



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
UKElectionNarratives: A Dataset of Misleading Narratives Surrounding Recent UK General Elections
May 08, 2025Misleading narratives play a crucial role in shaping public opinion during elections, as they can influence how voters perceive candidates and political parties. This entails the need to detect these narratives accurately. To address this, we introduce the first taxonomy of common misleading narratives that circulated during recent elections in Europe. Based on this taxonomy, we construct and analyse UKElectionNarratives: the first dataset of human-annotated misleading narratives which circulated during the UK General Elections in 2019 and 2024. We also benchmark Pre-trained and Large Language Models (focusing on GPT-4o), studying their effectiveness in detecting election-related misleading narratives. Finally, we discuss potential use cases and make recommendations for future research directions using the proposed codebook and dataset.
Detecting Stance of Authorities towards Rumors in Arabic Tweets: A Preliminary Study
Jan 14, 2023


A myriad of studies addressed the problem of rumor verification in Twitter by either utilizing evidence from the propagation networks or external evidence from the Web. However, none of these studies exploited evidence from trusted authorities. In this paper, we define the task of detecting the stance of authorities towards rumors in tweets, i.e., whether a tweet from an authority agrees, disagrees, or is unrelated to the rumor. We believe the task is useful to augment the sources of evidence utilized by existing rumor verification systems. We construct and release the first Authority STance towards Rumors (AuSTR) dataset, where evidence is retrieved from authority timelines in Arabic Twitter. Due to the relatively limited size of our dataset, we study the usefulness of existing datasets for stance detection in our task. We show that existing datasets are somewhat useful for the task; however, they are clearly insufficient, which motivates the need to augment them with annotated data constituting stance of authorities from Twitter.
Overview of the CLEF--2021 CheckThat! Lab on Detecting Check-Worthy Claims, Previously Fact-Checked Claims, and Fake News
Sep 23, 2021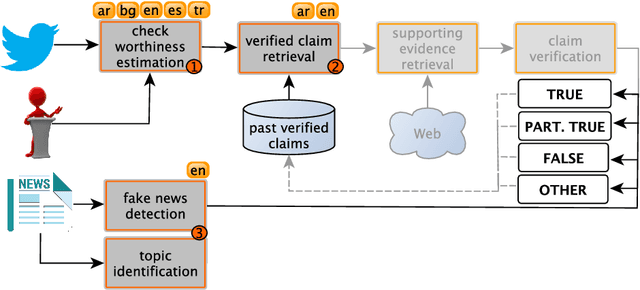
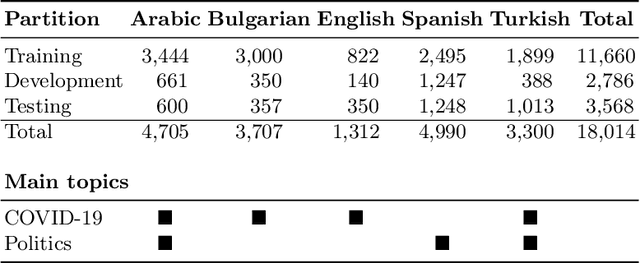
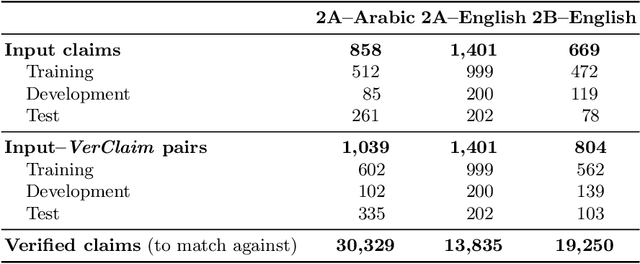
We describe the fourth edition of the CheckThat! Lab, part of the 2021 Conference and Labs of the Evaluation Forum (CLEF). The lab evaluates technology supporting tasks related to factuality, and covers Arabic, Bulgarian, English, Spanish, and Turkish. Task 1 asks to predict which posts in a Twitter stream are worth fact-checking, focusing on COVID-19 and politics (in all five languages). Task 2 asks to determine whether a claim in a tweet can be verified using a set of previously fact-checked claims (in Arabic and English). Task 3 asks to predict the veracity of a news article and its topical domain (in English). The evaluation is based on mean average precision or precision at rank k for the ranking tasks, and macro-F1 for the classification tasks. This was the most popular CLEF-2021 lab in terms of team registrations: 132 teams. Nearly one-third of them participated: 15, 5, and 25 teams submitted official runs for tasks 1, 2, and 3, respectively.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
An Intelligent Resource Reservation for Crowdsourced Live Video Streaming Applications in Geo-Distributed Cloud Environment
Jun 04, 2021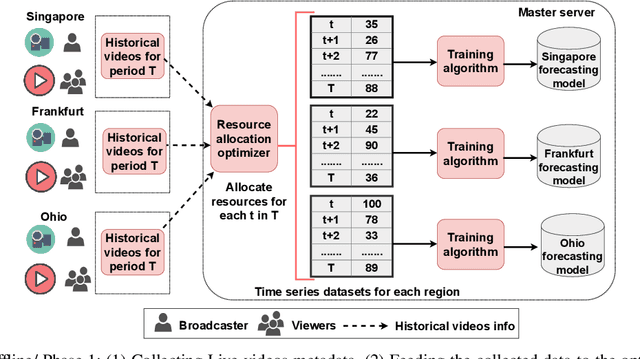
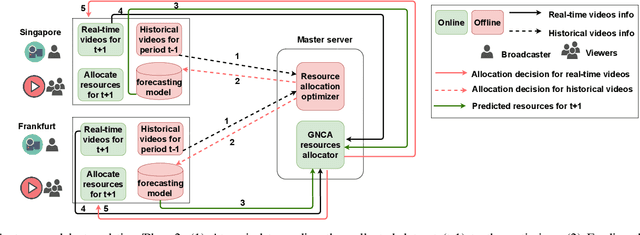
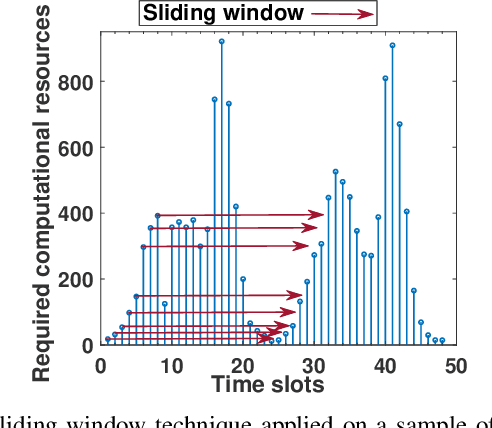
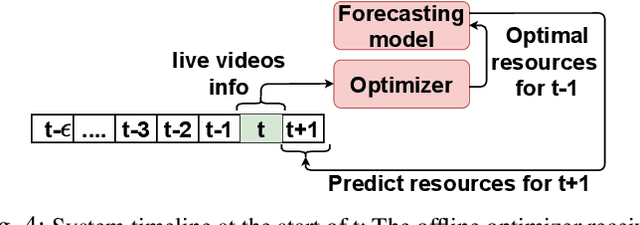
Crowdsourced live video streaming (livecast) services such as Facebook Live, YouNow, Douyu and Twitch are gaining more momentum recently. Allocating the limited resources in a cost-effective manner while maximizing the Quality of Service (QoS) through real-time delivery and the provision of the appropriate representations for all viewers is a challenging problem. In our paper, we introduce a machine-learning based predictive resource allocation framework for geo-distributed cloud sites, considering the delay and quality constraints to guarantee the maximum QoS for viewers and the minimum cost for content providers. First, we present an offline optimization that decides the required transcoding resources in distributed regions near the viewers with a trade-off between the QoS and the overall cost. Second, we use machine learning to build forecasting models that proactively predict the approximate transcoding resources to be reserved at each cloud site ahead of time. Finally, we develop a Greedy Nearest and Cheapest algorithm (GNCA) to perform the resource allocation of real-time broadcasted videos on the rented resources. Extensive simulations have shown that GNCA outperforms the state-of-the art resource allocation approaches for crowdsourced live streaming by achieving more than 20% gain in terms of system cost while serving the viewers with relatively lower latency.
ArCOV19-Rumors: Arabic COVID-19 Twitter Dataset for Misinformation Detection
Oct 17, 2020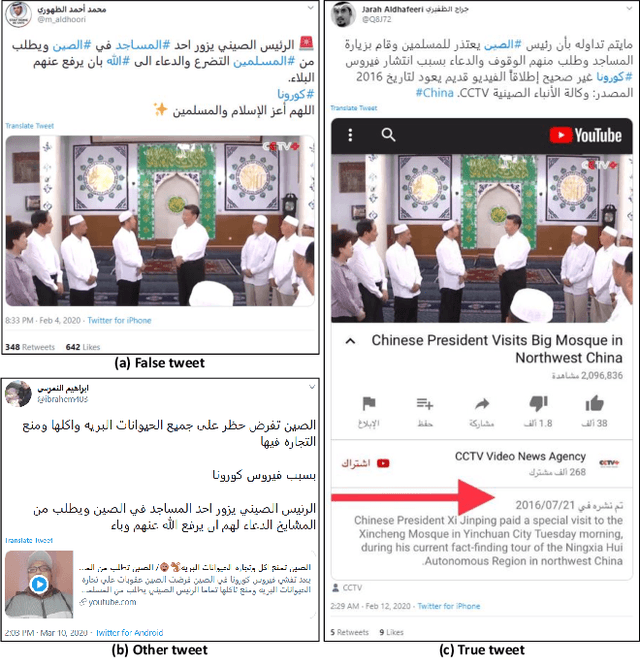
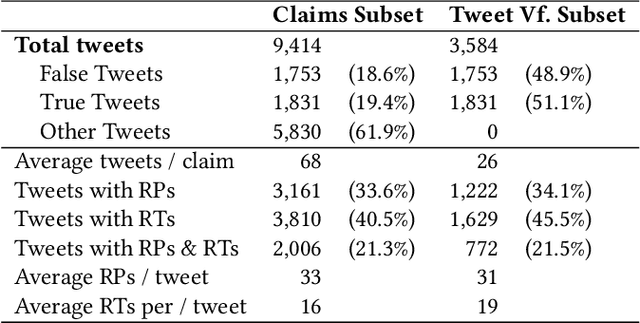
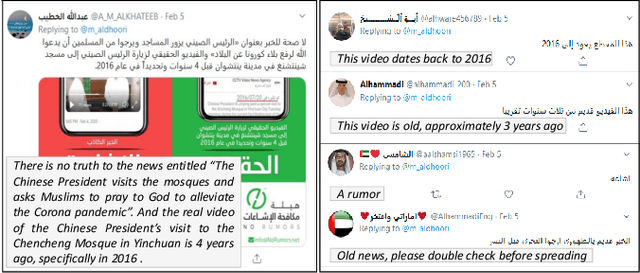
In this paper we introduce ArCOV19-Rumors, an Arabic COVID-19 Twitter dataset for misinformation detection composed of tweets containing claims from 27th January till the end of April 2020. We collected 138 verified claims, mostly from popular fact-checking websites, and identified 9.4K relevant tweets to those claims. We then manually-annotated the tweets by veracity to support research on misinformation detection, which is one of the major problems faced during a pandemic. We aim to support two classes of misinformation detection problems over Twitter: verifying free-text claims (called claim-level verification) and verifying claims expressed in tweets (called tweet-level verification). Our dataset covers, in addition to health, claims related to other topical categories that were influenced by COVID-19, namely, social, politics, sports, entertainment, and religious.
Overview of CheckThat! 2020: Automatic Identification and Verification of Claims in Social Media
Jul 15, 2020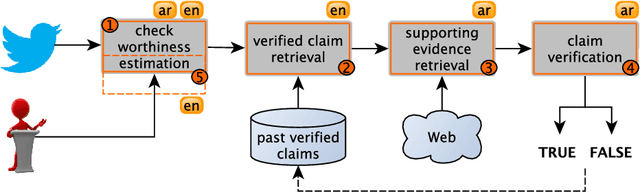
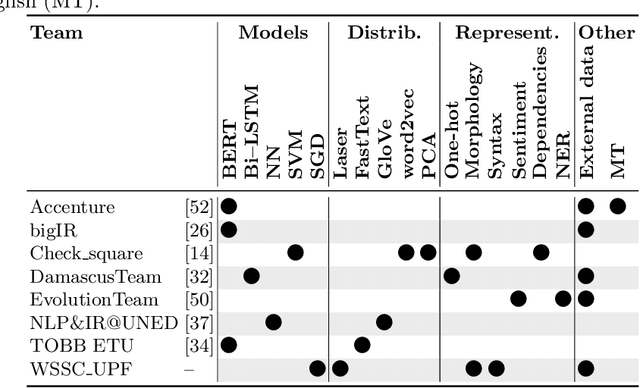
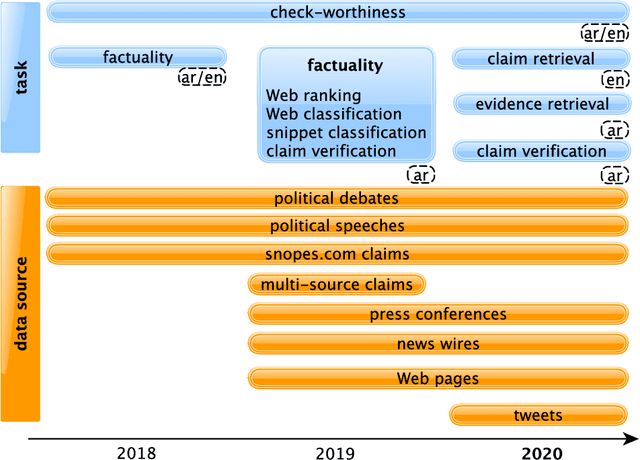
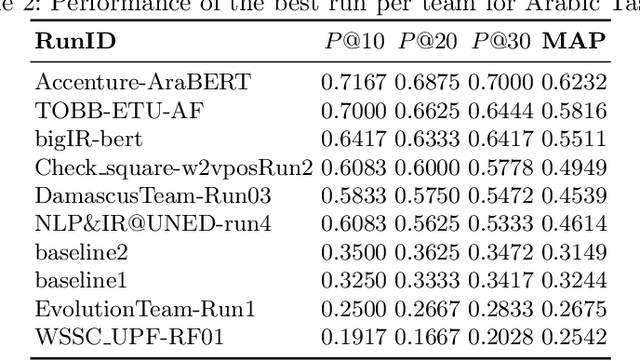
We present an overview of the third edition of the CheckThat! Lab at CLEF 2020. The lab featured five tasks in two different languages: English and Arabic. The first four tasks compose the full pipeline of claim verification in social media: Task 1 on check-worthiness estimation, Task 2 on retrieving previously fact-checked claims, Task 3 on evidence retrieval, and Task 4 on claim verification. The lab is completed with Task 5 on check-worthiness estimation in political debates and speeches. A total of 67 teams registered to participate in the lab (up from 47 at CLEF 2019), and 23 of them actually submitted runs (compared to 14 at CLEF 2019). Most teams used deep neural networks based on BERT, LSTMs, or CNNs, and achieved sizable improvements over the baselines on all tasks. Here we describe the tasks setup, the evaluation results, and a summary of the approaches used by the participants, and we discuss some lessons learned. Last but not least, we release to the research community all datasets from the lab as well as the evaluation scripts, which should enable further research in the important tasks of check-worthiness estimation and automatic claim verification.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
ArCOV-19: The First Arabic COVID-19 Twitter Dataset with Propagation Networks
Apr 18, 2020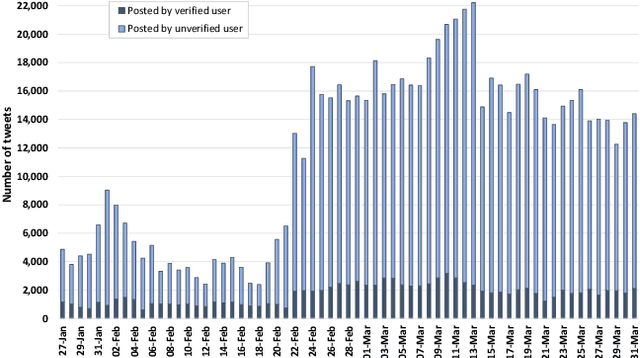
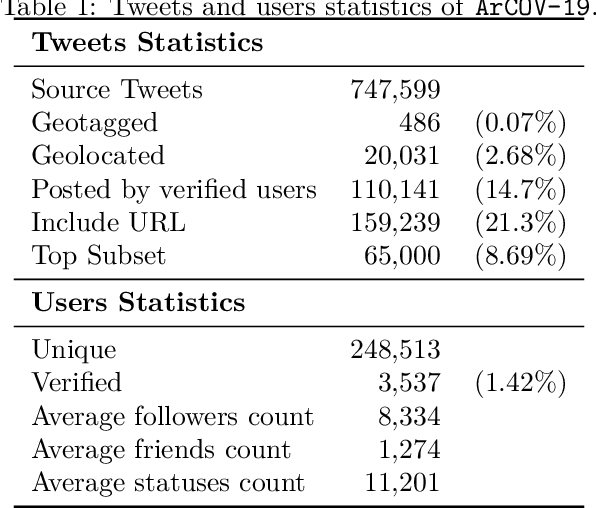
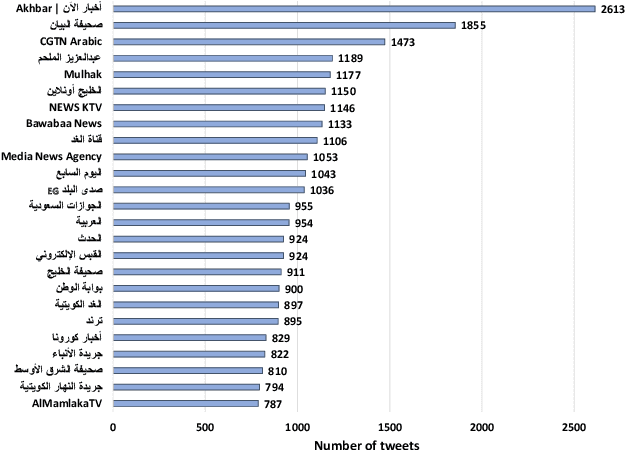
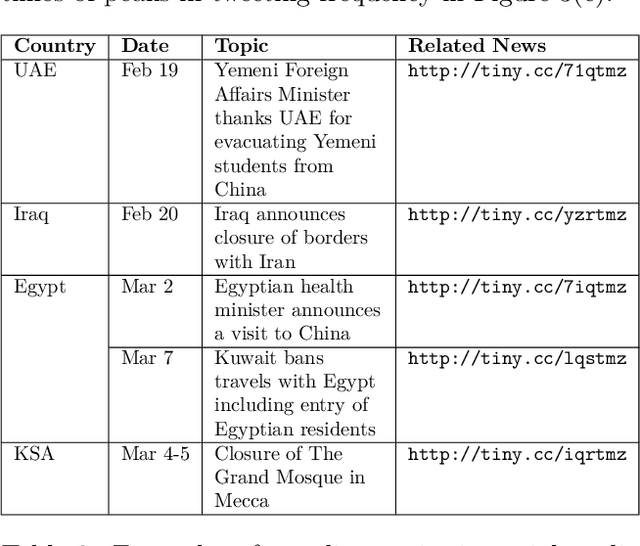
In this paper, we present ArCOV-19, an Arabic COVID-19 Twitter dataset that covers the period from 27th of January till 31st of March 2020. ArCOV-19 is the first publicly-available Arabic Twitter dataset covering COVID-19 pandemic that includes around 748k popular tweets (according to Twitter search criterion) alongside the propagation networks of the most-popular subset of them. The propagation networks include both retweets and conversational threads (i.e., threads of replies). ArCOV-19 is designed to enable research under several domains including natural language processing, information retrieval, and social computing, among others. Preliminary analysis shows that ArCOV-19 captures rising discussions associated with the first reported cases of the disease as they appeared in the Arab world. In addition to the source tweets and the propagation networks, we also release the search queries and the language-independent crawler used to collect the tweets to encourage the curation of similar datasets.
CheckThat! at CLEF 2020: Enabling the Automatic Identification and Verification of Claims in Social Media
Jan 21, 2020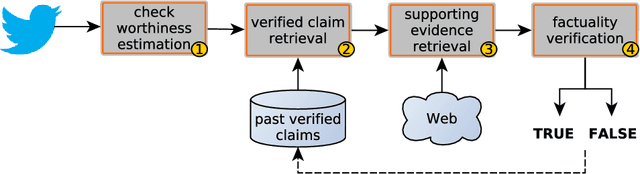
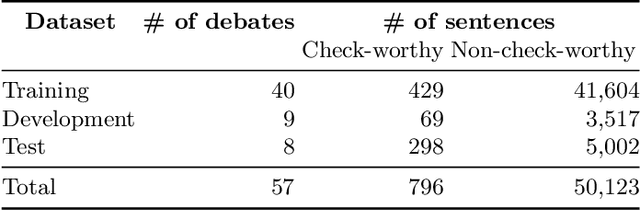
We describe the third edition of the CheckThat! Lab, which is part of the 2020 Cross-Language Evaluation Forum (CLEF). CheckThat! proposes four complementary tasks and a related task from previous lab editions, offered in English, Arabic, and Spanish. Task 1 asks to predict which tweets in a Twitter stream are worth fact-checking. Task 2 asks to determine whether a claim posted in a tweet can be verified using a set of previously fact-checked claims. Task 3 asks to retrieve text snippets from a given set of Web pages that would be useful for verifying a target tweet's claim. Task 4 asks to predict the veracity of a target tweet's claim using a set of Web pages and potentially useful snippets in them. Finally, the lab offers a fifth task that asks to predict the check-worthiness of the claims made in English political debates and speeches. CheckThat! features a full evaluation framework. The evaluation is carried out using mean average precision or precision at rank k for ranking tasks, and F1 for classification tasks.
* Computational journalism, Check-worthiness, Fact-checking, Veracity, CLEF-2020 CheckThat! Lab
QoE-Aware Resource Allocation for Crowdsourced Live Streaming: A Machine Learning Approach
Jun 20, 2019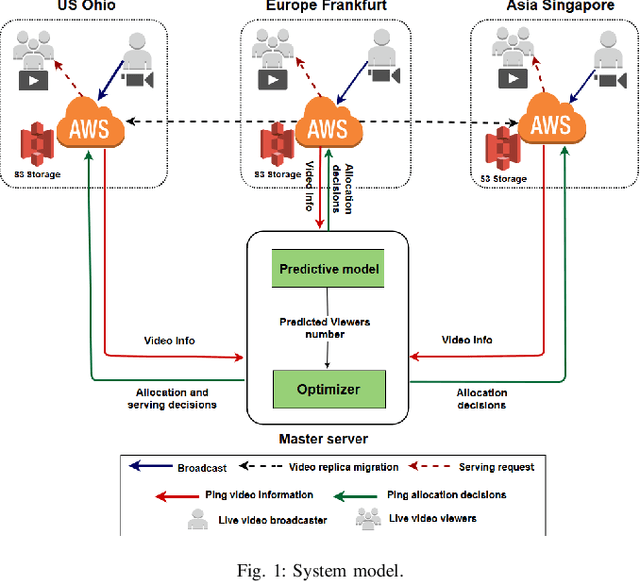
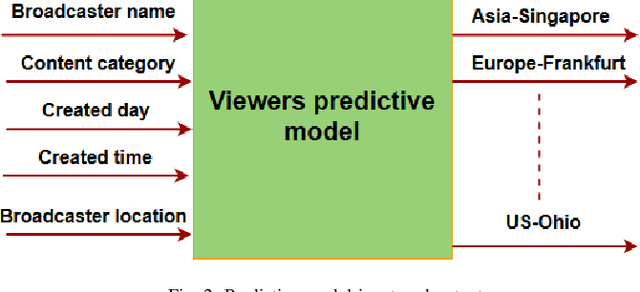

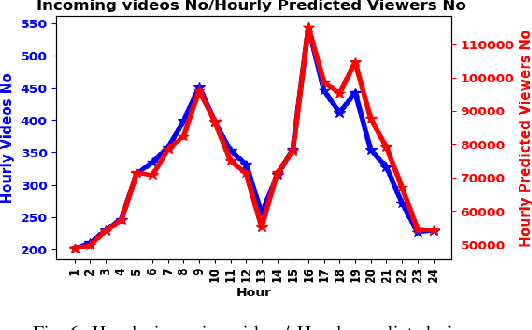
Driven by the tremendous technological advancement of personal devices and the prevalence of wireless mobile network accesses, the world has witnessed an explosion in crowdsourced live streaming. Ensuring a better viewers quality of experience (QoE) is the key to maximize the audiences number and increase streaming providers' profits. This can be achieved by advocating a geo-distributed cloud infrastructure to allocate the multimedia resources as close as possible to viewers, in order to minimize the access delay and video stalls. Moreover, allocating the exact needed resources beforehand avoids over-provisioning, which may lead to significant costs by the service providers. In the contrary, under-provisioning might cause significant delays to the viewers. In this paper, we introduce a prediction driven resource allocation framework, to maximize the QoE of viewers and minimize the resource allocation cost. First, by exploiting the viewers locations available in our unique dataset, we implement a machine learning model to predict the viewers number near each geo-distributed cloud site. Second, based on the predicted results that showed to be close to the actual values, we formulate an optimization problem to proactively allocate resources at the viewers proximity. Additionally, we will present a trade-off between the video access delay and the cost of resource allocation.