 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Intelligent Resource Reservation for Crowdsourced Live Video Streaming Applications in Geo-Distributed Cloud Environment
Jun 04, 2021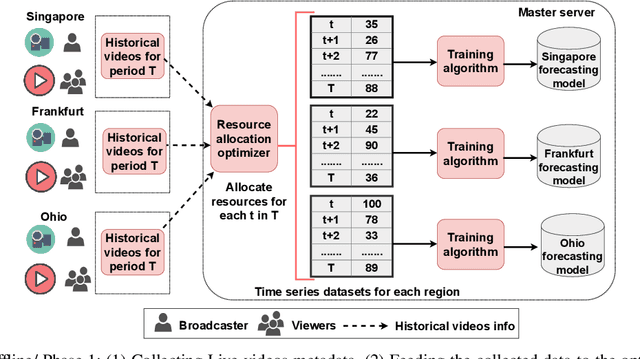
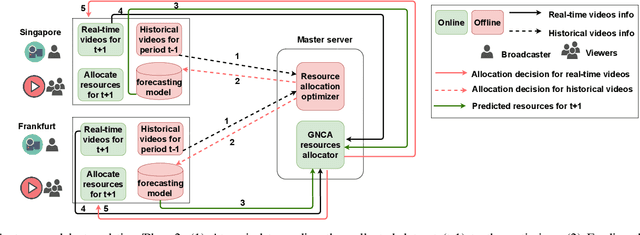
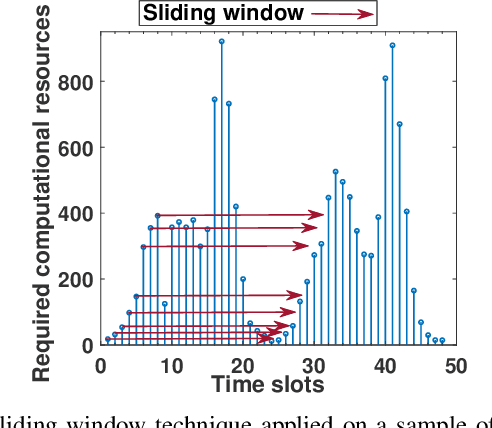
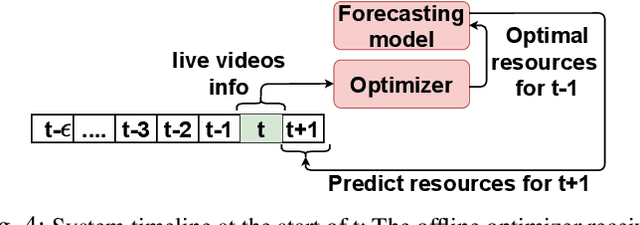
Crowdsourced live video streaming (livecast) services such as Facebook Live, YouNow, Douyu and Twitch are gaining more momentum recently. Allocating the limited resources in a cost-effective manner while maximizing the Quality of Service (QoS) through real-time delivery and the provision of the appropriate representations for all viewers is a challenging problem. In our paper, we introduce a machine-learning based predictive resource allocation framework for geo-distributed cloud sites, considering the delay and quality constraints to guarantee the maximum QoS for viewers and the minimum cost for content providers. First, we present an offline optimization that decides the required transcoding resources in distributed regions near the viewers with a trade-off between the QoS and the overall cost. Second, we use machine learning to build forecasting models that proactively predict the approximate transcoding resources to be reserved at each cloud site ahead of time. Finally, we develop a Greedy Nearest and Cheapest algorithm (GNCA) to perform the resource allocation of real-time broadcasted videos on the rented resources. Extensive simulations have shown that GNCA outperforms the state-of-the art resource allocation approaches for crowdsourced live streaming by achieving more than 20% gain in terms of system cost while serving the viewers with relatively lower latency.
Applying Machine Learning Techniques for Caching in Edge Networks: A Comprehensive Survey
Jun 21, 2020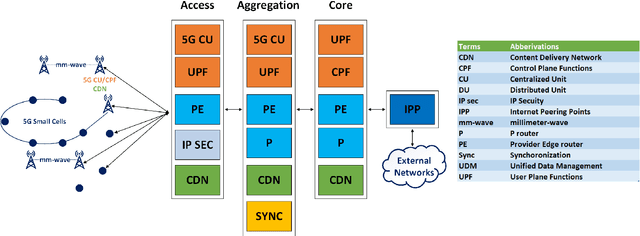
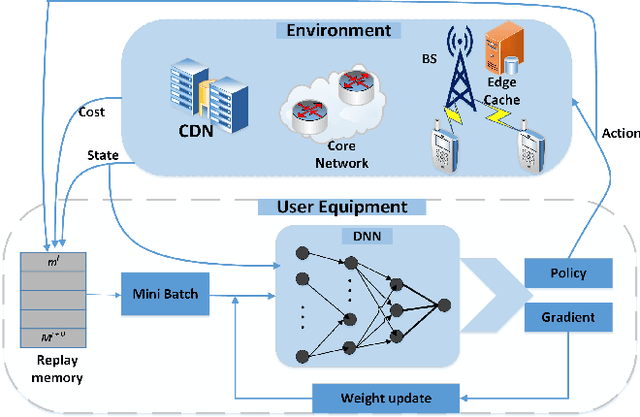
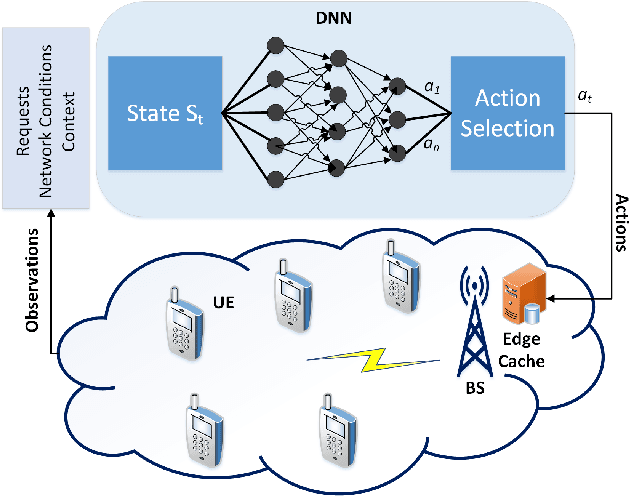
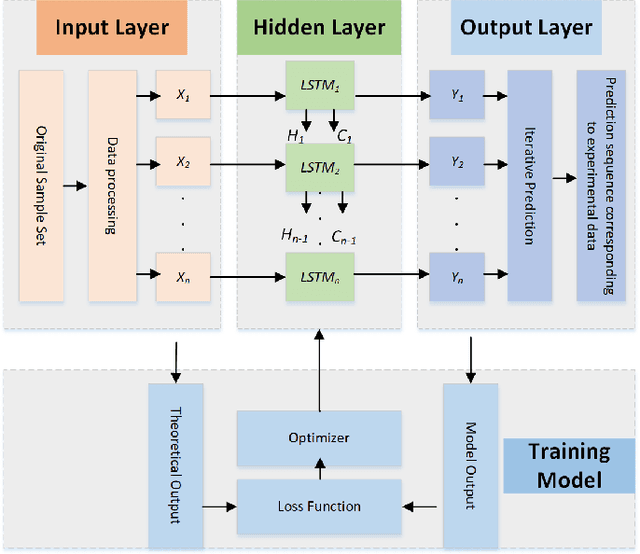
Edge networks provide access to a group of proximate users who may have similar content interests. Caching popular content at the edge networks leads to lower latencies while reducing the load on backhaul and core networks with the emergence of high-speed 5G networks. User mobility, preferences, and content popularity are the dominant dynamic features of the edge networks. Temporal and social features of content, such as the number of views and likes are applied to estimate the popularity of content from a global perspective. However, such estimates may not be mapped to an edge network with particular social and geographic characteristics. In edge networks, machine learning techniques can be applied to predict content popularity based on user preferences, user mobility based on user location history, cluster users based on similar content interests, and optimize cache placement strategies provided a set of constraints and predictions about the state of the network. These applications of machine learning can help identify relevant content for an edge network to lower latencies and increase cache hits. This article surveys the application of machine learning techniques for caching content in edge networks. We survey recent state-of-the-art literature and formulate a comprehensive taxonomy based on (a) machine learning technique, (b) caching strategy, and edge network. We further survey supporting concepts for optimal edge caching decisions that require the application of machine learning. These supporting concepts are social-awareness, popularity prediction, and community detection in edge networks. A comparative analysis of the state-of-the-art literature is presented with respect to the parameters identified in the taxonomy. Moreover, we debate research challenges and future directions for optimal caching decisions and the application of machine learning towards caching in edge networks.
A Periodicity-based Parallel Time Series Prediction Algorithm in Cloud Computing Environments
Oct 17, 2018



In the era of big data, practical applications in various domains continually generate large-scale time-series data. Among them, some data show significant or potential periodicity characteristics, such as meteorological and financial data. It is critical to efficiently identify the potential periodic patterns from massive time-series data and provide accurate predictions. In this paper, a Periodicity-based Parallel Time Series Prediction (PPTSP) algorithm for large-scale time-series data is proposed and implemented in the Apache Spark cloud computing environment. To effectively handle the massive historical datasets, a Time Series Data Compression and Abstraction (TSDCA) algorithm is presented, which can reduce the data scale as well as accurately extracting the characteristics. Based on this, we propose a Multi-layer Time Series Periodic Pattern Recognition (MTSPPR) algorithm using the Fourier Spectrum Analysis (FSA) method. In addition, a Periodicity-based Time Series Prediction (PTSP) algorithm is proposed. Data in the subsequent period are predicted based on all previous period models, in which a time attenuation factor is introduced to control the impact of different periods on the prediction results. Moreover, to improve the performance of the proposed algorithms, we propose a parallel solution on the Apache Spark platform, using the Streaming real-time computing module. To efficiently process the large-scale time-series datasets in distributed computing environments, Distributed Streams (DStreams) and Resilient Distributed Datasets (RDDs) are used to store and calculate these datasets. Extensive experimental results show that our PPTSP algorithm has significant advantages compared with other algorithms in terms of prediction accuracy and performance.
A Disease Diagnosis and Treatment Recommendation System Based on Big Data Mining and Cloud Computing
Oct 17, 2018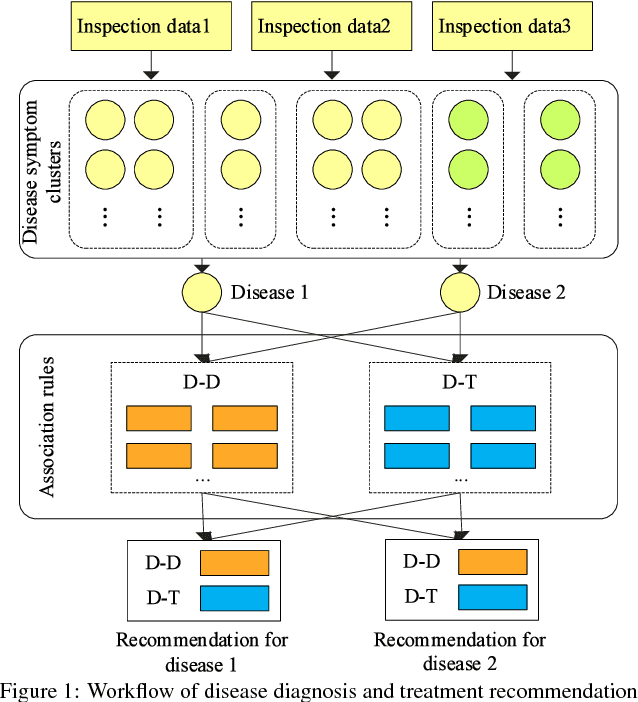
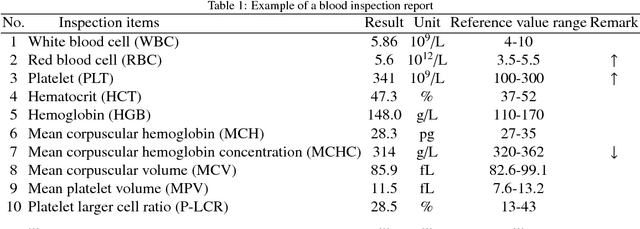

It is crucial to provide compatible treatment schemes for a disease according to various symptoms at different stages. However, most classification methods might be ineffective in accurately classifying a disease that holds the characteristics of multiple treatment stages, various symptoms, and multi-pathogenesis. Moreover, there are limited exchanges and cooperative actions in disease diagnoses and treatments between different departments and hospitals. Thus, when new diseases occur with atypical symptoms, inexperienced doctors might have difficulty in identifying them promptly and accurately. Therefore, to maximize the utilization of the advanced medical technology of developed hospitals and the rich medical knowledge of experienced doctors, a Disease Diagnosis and Treatment Recommendation System (DDTRS) is proposed in this paper. First, to effectively identify disease symptoms more accurately, a Density-Peaked Clustering Analysis (DPCA) algorithm is introduced for disease-symptom clustering. In addition, association analyses on Disease-Diagnosis (D-D) rules and Disease-Treatment (D-T) rules are conducted by the Apriori algorithm separately. The appropriate diagnosis and treatment schemes are recommended for patients and inexperienced doctors, even if they are in a limited therapeutic environment. Moreover, to reach the goals of high performance and low latency response, we implement a parallel solution for DDTRS using the Apache Spark cloud platform. Extensive experimental results demonstrate that the proposed DDTRS realizes disease-symptom clustering effectively and derives disease treatment recommendations intelligently and accurately.
A Bi-layered Parallel Training Architecture for Large-scale Convolutional Neural Networks
Oct 17, 2018


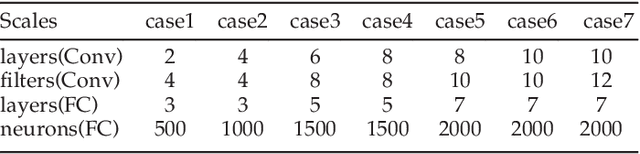
Benefitting from large-scale training datasets and the complex training network, Convolutional Neural Networks (CNNs) are widely applied in various fields with high accuracy. However, the training process of CNNs is very time-consuming, where large amounts of training samples and iterative operations are required to obtain high-quality weight parameters. In this paper, we focus on the time-consuming training process of large-scale CNNs and propose a Bi-layered Parallel Training (BPT-CNN) architecture in distributed computing environments. BPT-CNN consists of two main components: (a) an outer-layer parallel training for multiple CNN subnetworks on separate data subsets, and (b) an inner-layer parallel training for each subnetwork. In the outer-layer parallelism, we address critical issues of distributed and parallel computing, including data communication, synchronization, and workload balance. A heterogeneous-aware Incremental Data Partitioning and Allocation (IDPA) strategy is proposed, where large-scale training datasets are partitioned and allocated to the computing nodes in batches according to their computing power. To minimize the synchronization waiting during the global weight update process, an Asynchronous Global Weight Update (AGWU) strategy is proposed. In the inner-layer parallelism, we further accelerate the training process for each CNN subnetwork on each computer, where computation steps of convolutional layer and the local weight training are parallelized based on task-parallelism. We introduce task decomposition and scheduling strategies with the objectives of thread-level load balancing and minimum waiting time for critical paths. Extensive experimental results indicate that the proposed BPT-CNN effectively improves the training performance of CNNs while maintaining the accuracy.