 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Blockchain-based Reliable Federated Meta-learning for Metaverse: A Dual Game Framework
Aug 07, 2024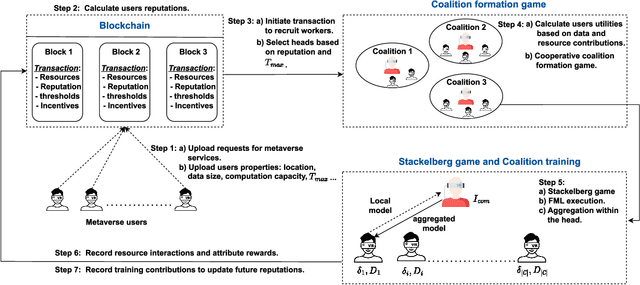
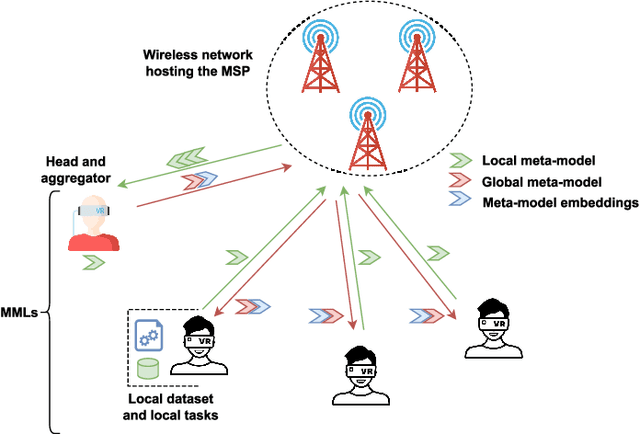
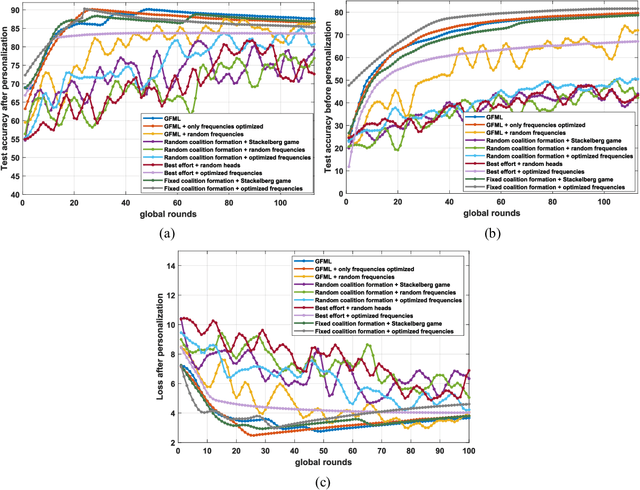
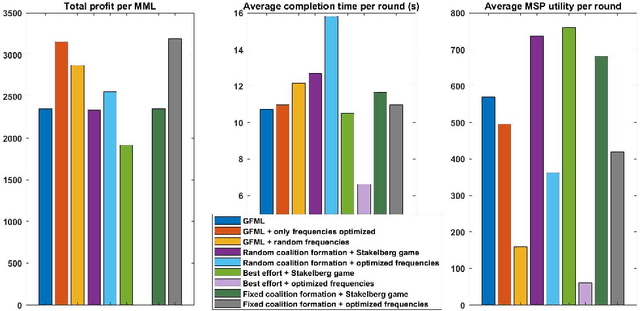
The metaverse, envisioned as the next digital frontier for avatar-based virtual interaction, involves high-performance models. In this dynamic environment, users' tasks frequently shift, requiring fast model personalization despite limited data. This evolution consumes extensive resources and requires vast data volumes. To address this, meta-learning emerges as an invaluable tool for metaverse users, with federated meta-learning (FML), offering even more tailored solutions owing to its adaptive capabilities. However, the metaverse is characterized by users heterogeneity with diverse data structures, varied tasks, and uneven sample sizes, potentially undermining global training outcomes due to statistical difference. Given this, an urgent need arises for smart coalition formation that accounts for these disparities. This paper introduces a dual game-theoretic framework for metaverse services involving meta-learners as workers to manage FML. A blockchain-based cooperative coalition formation game is crafted, grounded on a reputation metric, user similarity, and incentives. We also introduce a novel reputation system based on users' historical contributions and potential contributions to present tasks, leveraging correlations between past and new tasks. Finally, a Stackelberg game-based incentive mechanism is presented to attract reliable workers to participate in meta-learning, minimizing users' energy costs, increasing payoffs, boosting FML efficacy, and improving metaverse utility. Results show that our dual game framework outperforms best-effort, random, and non-uniform clustering schemes - improving training performance by up to 10%, cutting completion times by as much as 30%, enhancing metaverse utility by more than 25%, and offering up to 5% boost in training efficiency over non-blockchain systems, effectively countering misbehaving users.
* Accepted in IEEE Internet of Things Journal
Adaptive ResNet Architecture for Distributed Inference in Resource-Constrained IoT Systems
Jul 21, 2023



As deep neural networks continue to expand and become more complex, most edge devices are unable to handle their extensive processing requirements. Therefore, the concept of distributed inference is essential to distribute the neural network among a cluster of nodes. However, distribution may lead to additional energy consumption and dependency among devices that suffer from unstable transmission rates. Unstable transmission rates harm real-time performance of IoT devices causing low latency, high energy usage, and potential failures. Hence, for dynamic systems, it is necessary to have a resilient DNN with an adaptive architecture that can downsize as per the available resources. This paper presents an empirical study that identifies the connections in ResNet that can be dropped without significantly impacting the model's performance to enable distribution in case of resource shortage. Based on the results, a multi-objective optimization problem is formulated to minimize latency and maximize accuracy as per available resources. Our experiments demonstrate that an adaptive ResNet architecture can reduce shared data, energy consumption, and latency throughout the distribution while maintaining high accuracy.
Zero-touch realization of Pervasive Artificial Intelligence-as-a-service in 6G networks
Jul 21, 2023



The vision of the upcoming 6G technologies, characterized by ultra-dense network, low latency, and fast data rate is to support Pervasive AI (PAI) using zero-touch solutions enabling self-X (e.g., self-configuration, self-monitoring, and self-healing) services. However, the research on 6G is still in its infancy, and only the first steps have been taken to conceptualize its design, investigate its implementation, and plan for use cases. Toward this end, academia and industry communities have gradually shifted from theoretical studies of AI distribution to real-world deployment and standardization. Still, designing an end-to-end framework that systematizes the AI distribution by allowing easier access to the service using a third-party application assisted by a zero-touch service provisioning has not been well explored. In this context, we introduce a novel platform architecture to deploy a zero-touch PAI-as-a-Service (PAIaaS) in 6G networks supported by a blockchain-based smart system. This platform aims to standardize the pervasive AI at all levels of the architecture and unify the interfaces in order to facilitate the service deployment across application and infrastructure domains, relieve the users worries about cost, security, and resource allocation, and at the same time, respect the 6G stringent performance requirements. As a proof of concept, we present a Federated Learning-as-a-service use case where we evaluate the ability of our proposed system to self-optimize and self-adapt to the dynamics of 6G networks in addition to minimizing the users' perceived costs.
* IEEE Communications Magazine
Optimal Resource Management for Hierarchical Federated Learning over HetNets with Wireless Energy Transfer
May 03, 2023



Remote monitoring systems analyze the environment dynamics in different smart industrial applications, such as occupational health and safety, and environmental monitoring. Specifically, in industrial Internet of Things (IoT) systems, the huge number of devices and the expected performance put pressure on resources, such as computational, network, and device energy. Distributed training of Machine and Deep Learning (ML/DL) models for intelligent industrial IoT applications is very challenging for resource limited devices over heterogeneous wireless networks (HetNets). Hierarchical Federated Learning (HFL) performs training at multiple layers offloading the tasks to nearby Multi-Access Edge Computing (MEC) units. In this paper, we propose a novel energy-efficient HFL framework enabled by Wireless Energy Transfer (WET) and designed for heterogeneous networks with massive Multiple-Input Multiple-Output (MIMO) wireless backhaul. Our energy-efficiency approach is formulated as a Mixed-Integer Non-Linear Programming (MINLP) problem, where we optimize the HFL device association and manage the wireless transmitted energy. However due to its high complexity, we design a Heuristic Resource Management Algorithm, namely H2RMA, that respects energy, channel quality, and accuracy constraints, while presenting a low computational complexity. We also improve the energy consumption of the network using an efficient device scheduling scheme. Finally, we investigate device mobility and its impact on the HFL performance. Our extensive experiments confirm the high performance of the proposed resource management approach in HFL over HetNets, in terms of training loss and grid energy costs.
Deep Reinforcement Learning for Trajectory Path Planning and Distributed Inference in Resource-Constrained UAV Swarms
Dec 21, 2022



The deployment flexibility and maneuverability of Unmanned Aerial Vehicles (UAVs) increased their adoption in various applications, such as wildfire tracking, border monitoring, etc. In many critical applications, UAVs capture images and other sensory data and then send the captured data to remote servers for inference and data processing tasks. However, this approach is not always practical in real-time applications due to the connection instability, limited bandwidth, and end-to-end latency. One promising solution is to divide the inference requests into multiple parts (layers or segments), with each part being executed in a different UAV based on the available resources. Furthermore, some applications require the UAVs to traverse certain areas and capture incidents; thus, planning their paths becomes critical particularly, to reduce the latency of making the collaborative inference process. Specifically, planning the UAVs trajectory can reduce the data transmission latency by communicating with devices in the same proximity while mitigating the transmission interference. This work aims to design a model for distributed collaborative inference requests and path planning in a UAV swarm while respecting the resource constraints due to the computational load and memory usage of the inference requests. The model is formulated as an optimization problem and aims to minimize latency. The formulated problem is NP-hard so finding the optimal solution is quite complex; thus, this paper introduces a real-time and dynamic solution for online applications using deep reinforcement learning. We conduct extensive simulations and compare our results to the-state-of-the-art studies demonstrating that our model outperforms the competing models.
RL-DistPrivacy: Privacy-Aware Distributed Deep Inference for low latency IoT systems
Aug 27, 2022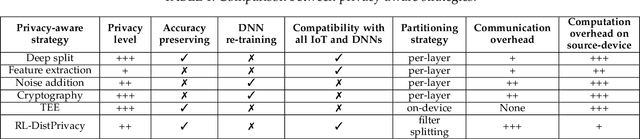
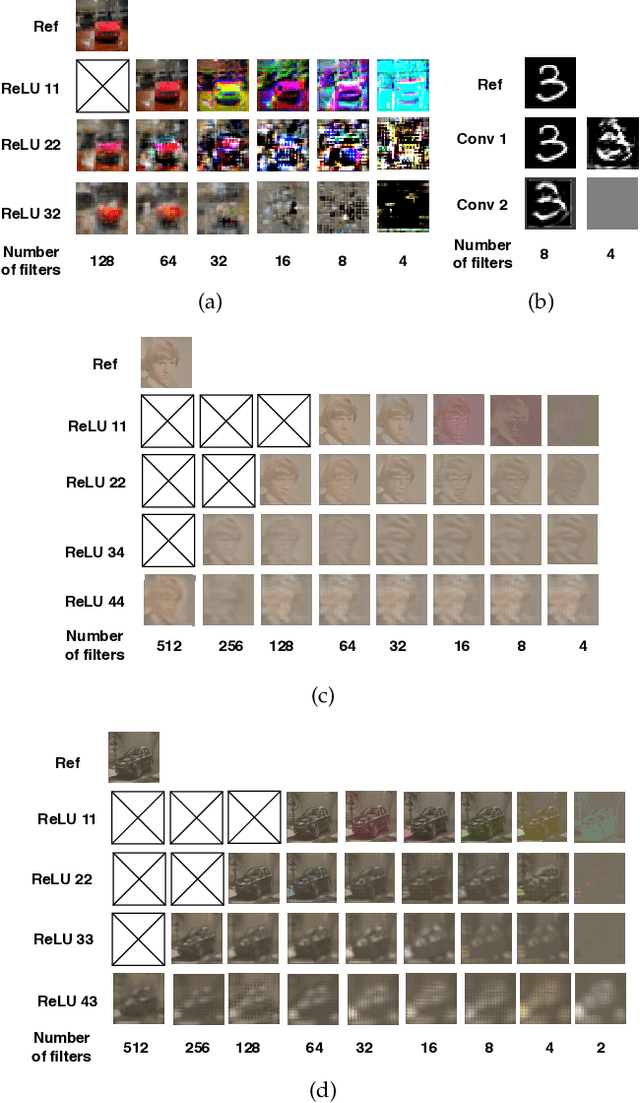
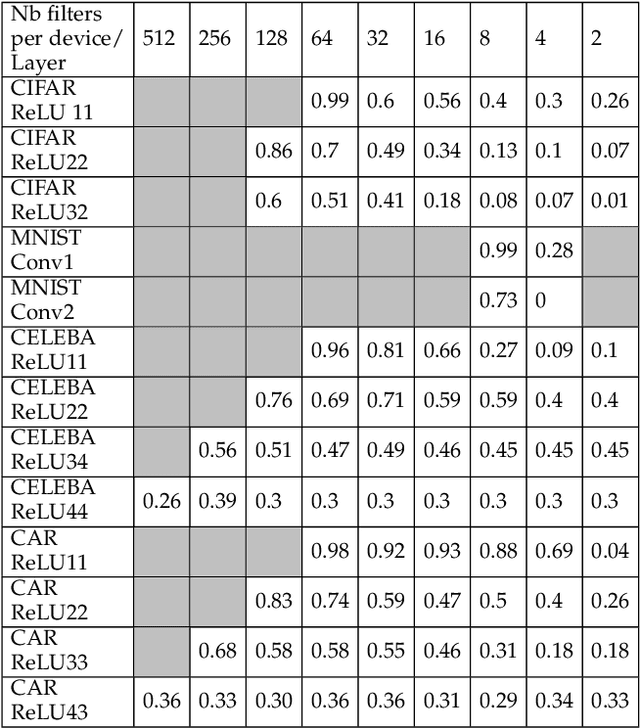

Although Deep Neural Networks (DNN) have become the backbone technology of several ubiquitous applications, their deployment in resource-constrained machines, e.g., Internet of Things (IoT) devices, is still challenging. To satisfy the resource requirements of such a paradigm, collaborative deep inference with IoT synergy was introduced. However, the distribution of DNN networks suffers from severe data leakage. Various threats have been presented, including black-box attacks, where malicious participants can recover arbitrary inputs fed into their devices. Although many countermeasures were designed to achieve privacy-preserving DNN, most of them result in additional computation and lower accuracy. In this paper, we present an approach that targets the security of collaborative deep inference via re-thinking the distribution strategy, without sacrificing the model performance. Particularly, we examine different DNN partitions that make the model susceptible to black-box threats and we derive the amount of data that should be allocated per device to hide proprieties of the original input. We formulate this methodology, as an optimization, where we establish a trade-off between the latency of co-inference and the privacy-level of data. Next, to relax the optimal solution, we shape our approach as a Reinforcement Learning (RL) design that supports heterogeneous devices as well as multiple DNNs/datasets.
* Published in IEEE Transactions on Network Science and Engineering
LoRa-RL: Deep Reinforcement Learning for Resource Management in Hybrid Energy LoRa Wireless Networks
Sep 06, 2021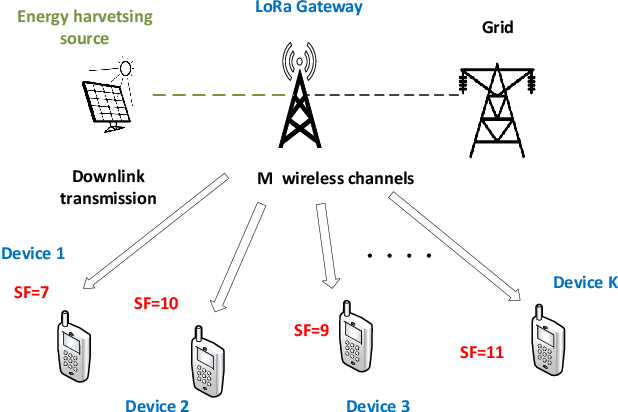
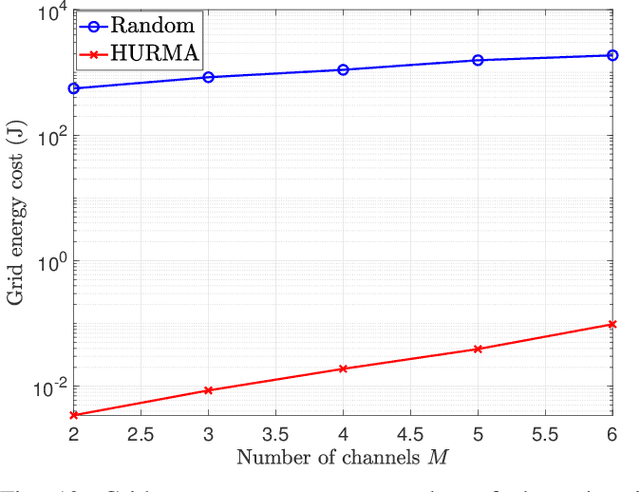

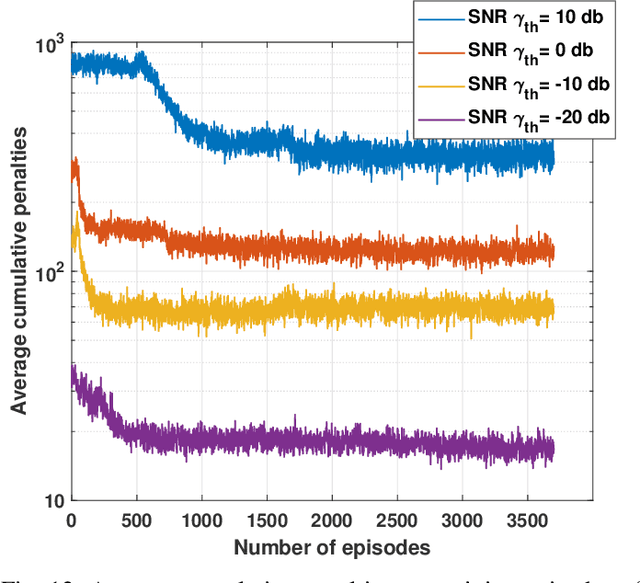
LoRa wireless networks are considered as a key enabling technology for next generation internet of things (IoT) systems. New IoT deployments (e.g., smart city scenarios) can have thousands of devices per square kilometer leading to huge amount of power consumption to provide connectivity. In this paper, we investigate green LoRa wireless networks powered by a hybrid of the grid and renewable energy sources, which can benefit from harvested energy while dealing with the intermittent supply. This paper proposes resource management schemes of the limited number of channels and spreading factors (SFs) with the objective of improving the LoRa gateway energy efficiency. First, the problem of grid power consumption minimization while satisfying the system's quality of service demands is formulated. Specifically, both scenarios the uncorrelated and time-correlated channels are investigated. The optimal resource management problem is solved by decoupling the formulated problem into two sub-problems: channel and SF assignment problem and energy management problem. Since the optimal solution is obtained with high complexity, online resource management heuristic algorithms that minimize the grid energy consumption are proposed. Finally, taking into account the channel and energy correlation, adaptable resource management schemes based on Reinforcement Learning (RL), are developed. Simulations results show that the proposed resource management schemes offer efficient use of renewable energy in LoRa wireless networks.
Emotion Recognition for Healthcare Surveillance Systems Using Neural Networks: A Survey
Jul 13, 2021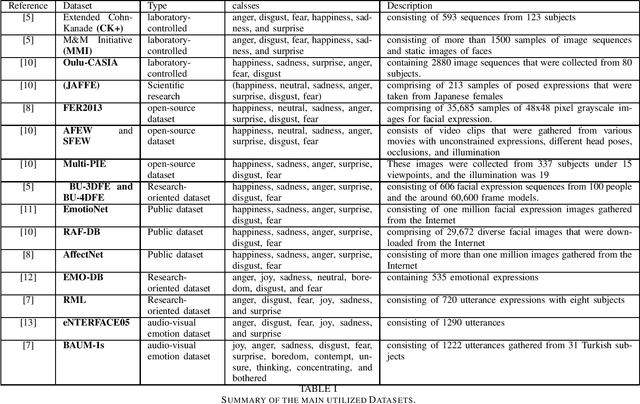

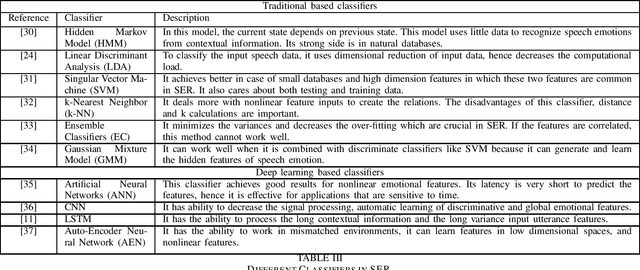

Recognizing the patient's emotions using deep learning techniques has attracted significant attention recently due to technological advancements. Automatically identifying the emotions can help build smart healthcare centers that can detect depression and stress among the patients in order to start the medication early. Using advanced technology to identify emotions is one of the most exciting topics as it defines the relationships between humans and machines. Machines learned how to predict emotions by adopting various methods. In this survey, we present recent research in the field of using neural networks to recognize emotions. We focus on studying emotions' recognition from speech, facial expressions, and audio-visual input and show the different techniques of deploying these algorithms in the real world. These three emotion recognition techniques can be used as a surveillance system in healthcare centers to monitor patients. We conclude the survey with a presentation of the challenges and the related future work to provide an insight into the applications of using emotion recognition.
Efficient Real-Time Image Recognition Using Collaborative Swarm of UAVs and Convolutional Networks
Jul 09, 2021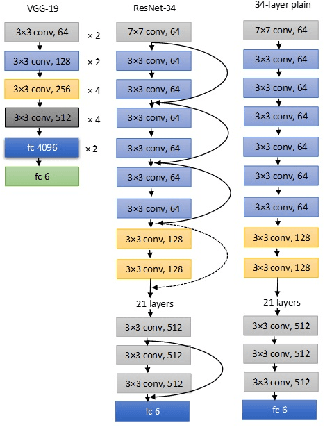
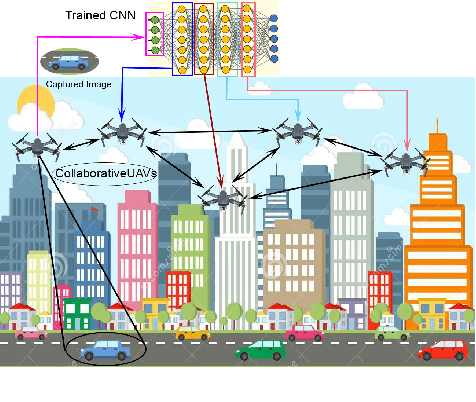
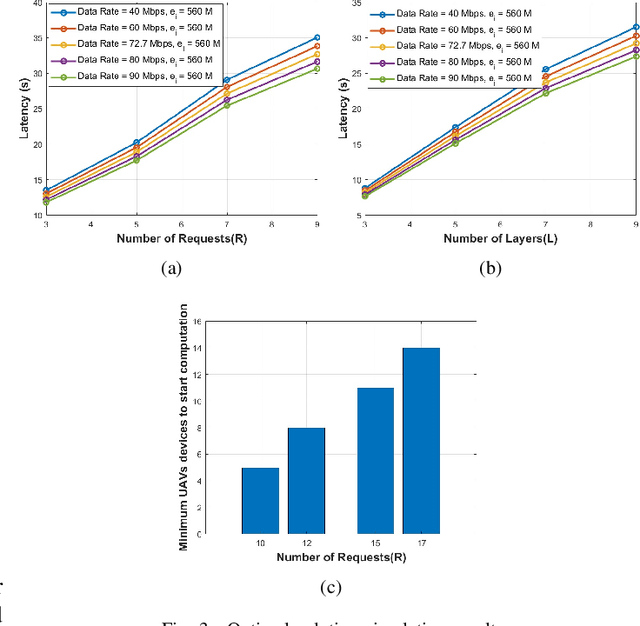
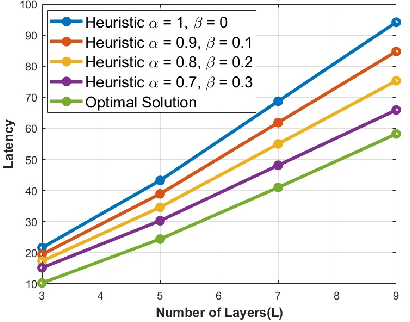
Unmanned Aerial Vehicles (UAVs) have recently attracted significant attention due to their outstanding ability to be used in different sectors and serve in difficult and dangerous areas. Moreover, the advancements in computer vision and artificial intelligence have increased the use of UAVs in various applications and solutions, such as forest fires detection and borders monitoring. However, using deep neural networks (DNNs) with UAVs introduces several challenges of processing deeper networks and complex models, which restricts their on-board computation. In this work, we present a strategy aiming at distributing inference requests to a swarm of resource-constrained UAVs that classifies captured images on-board and finds the minimum decision-making latency. We formulate the model as an optimization problem that minimizes the latency between acquiring images and making the final decisions. The formulated optimization solution is an NP-hard problem. Hence it is not adequate for online resource allocation. Therefore, we introduce an online heuristic solution, namely DistInference, to find the layers placement strategy that gives the best latency among the available UAVs. The proposed approach is general enough to be used for different low decision-latency applications as well as for all CNN types organized into the pipeline of layers (e.g., VGG) or based on residual blocks (e.g., ResNet).
An Intelligent Resource Reservation for Crowdsourced Live Video Streaming Applications in Geo-Distributed Cloud Environment
Jun 04, 2021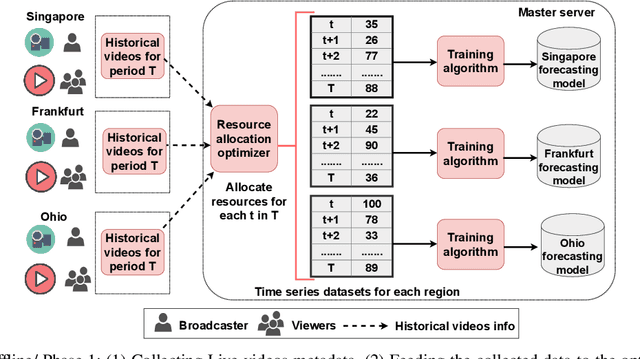
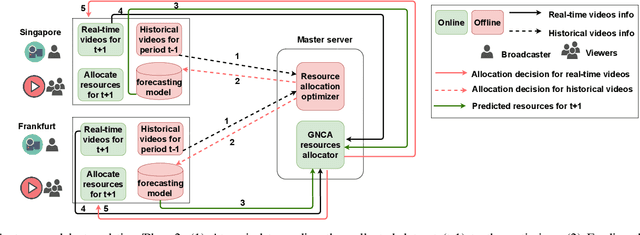
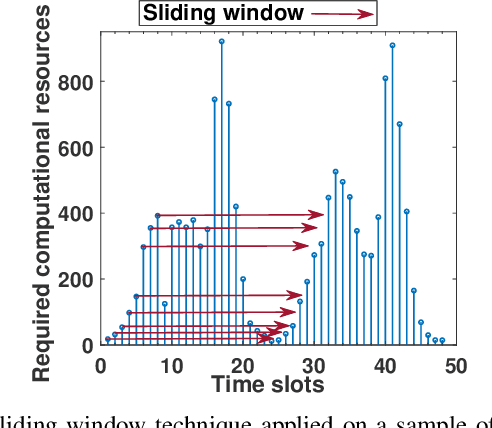
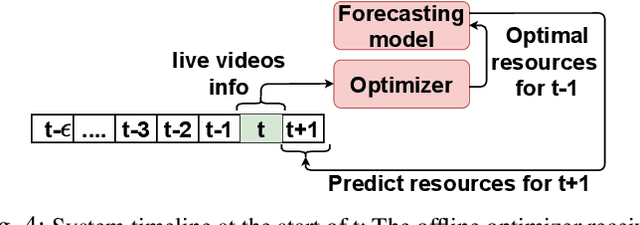
Crowdsourced live video streaming (livecast) services such as Facebook Live, YouNow, Douyu and Twitch are gaining more momentum recently. Allocating the limited resources in a cost-effective manner while maximizing the Quality of Service (QoS) through real-time delivery and the provision of the appropriate representations for all viewers is a challenging problem. In our paper, we introduce a machine-learning based predictive resource allocation framework for geo-distributed cloud sites, considering the delay and quality constraints to guarantee the maximum QoS for viewers and the minimum cost for content providers. First, we present an offline optimization that decides the required transcoding resources in distributed regions near the viewers with a trade-off between the QoS and the overall cost. Second, we use machine learning to build forecasting models that proactively predict the approximate transcoding resources to be reserved at each cloud site ahead of time. Finally, we develop a Greedy Nearest and Cheapest algorithm (GNCA) to perform the resource allocation of real-time broadcasted videos on the rented resources. Extensive simulations have shown that GNCA outperforms the state-of-the art resource allocation approaches for crowdsourced live streaming by achieving more than 20% gain in terms of system cost while serving the viewers with relatively lower latency.