 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Recommendation System for Enhanced Customer Experience: A Novel Image-to-Text Method
Nov 16, 2023Existing fashion recommendation systems encounter difficulties in using visual data for accurate and personalized recommendations. This research describes an innovative end-to-end pipeline that uses artificial intelligence to provide fine-grained visual interpretation for fashion recommendations. When customers upload images of desired products or outfits, the system automatically generates meaningful descriptions emphasizing stylistic elements. These captions guide retrieval from a global fashion product catalogue to offer similar alternatives that fit the visual characteristics of the original image. On a dataset of over 100,000 categorized fashion photos, the pipeline was trained and evaluated. The F1-score for the object detection model was 0.97, exhibiting exact fashion object recognition capabilities optimized for recommendation. This visually aware system represents a key advancement in customer engagement through personalized fashion recommendations
* 6 pages, 5 figures
Optimal Resource Management for Hierarchical Federated Learning over HetNets with Wireless Energy Transfer
May 03, 2023



Remote monitoring systems analyze the environment dynamics in different smart industrial applications, such as occupational health and safety, and environmental monitoring. Specifically, in industrial Internet of Things (IoT) systems, the huge number of devices and the expected performance put pressure on resources, such as computational, network, and device energy. Distributed training of Machine and Deep Learning (ML/DL) models for intelligent industrial IoT applications is very challenging for resource limited devices over heterogeneous wireless networks (HetNets). Hierarchical Federated Learning (HFL) performs training at multiple layers offloading the tasks to nearby Multi-Access Edge Computing (MEC) units. In this paper, we propose a novel energy-efficient HFL framework enabled by Wireless Energy Transfer (WET) and designed for heterogeneous networks with massive Multiple-Input Multiple-Output (MIMO) wireless backhaul. Our energy-efficiency approach is formulated as a Mixed-Integer Non-Linear Programming (MINLP) problem, where we optimize the HFL device association and manage the wireless transmitted energy. However due to its high complexity, we design a Heuristic Resource Management Algorithm, namely H2RMA, that respects energy, channel quality, and accuracy constraints, while presenting a low computational complexity. We also improve the energy consumption of the network using an efficient device scheduling scheme. Finally, we investigate device mobility and its impact on the HFL performance. Our extensive experiments confirm the high performance of the proposed resource management approach in HFL over HetNets, in terms of training loss and grid energy costs.
Spatiotemporal Tensor Completion for Improved Urban Traffic Imputation
Mar 12, 2021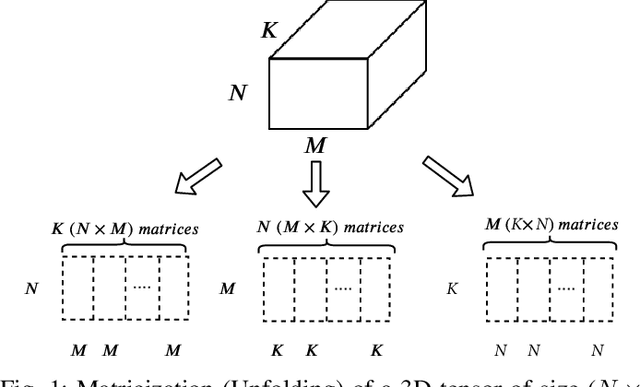
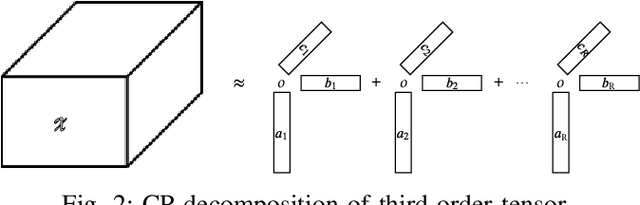

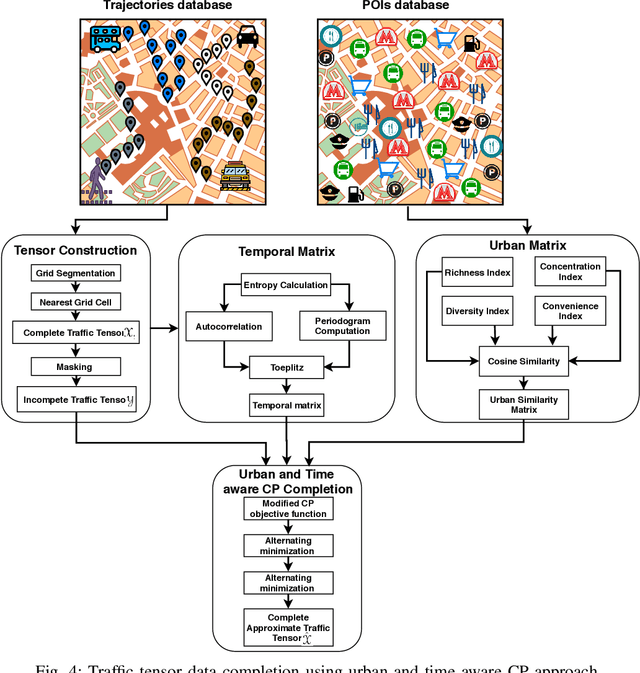
Effective management of urban traffic is important for any smart city initiative. Therefore, the quality of the sensory traffic data is of paramount importance. However, like any sensory data, urban traffic data are prone to imperfections leading to missing measurements. In this paper, we focus on inter-region traffic data completion. We model the inter-region traffic as a spatiotemporal tensor that suffers from missing measurements. To recover the missing data, we propose an enhanced CANDECOMP/PARAFAC (CP) completion approach that considers the urban and temporal aspects of the traffic. To derive the urban characteristics, we divide the area of study into regions. Then, for each region, we compute urban feature vectors inspired from biodiversity which are used to compute the urban similarity matrix. To mine the temporal aspect, we first conduct an entropy analysis to determine the most regular time-series. Then, we conduct a joint Fourier and correlation analysis to compute its periodicity and construct the temporal matrix. Both urban and temporal matrices are fed into a modified CP-completion objective function. To solve this objective, we propose an alternating least square approach that operates on the vectorized version of the inputs. We conduct comprehensive comparative study with two evaluation scenarios. In the first one, we simulate random missing values. In the second scenario, we simulate missing values at a given area and time duration. Our results demonstrate that our approach provides effective recovering performance reaching 26% improvement compared to state-of-art CP approaches and 35% compared to state-of-art generative model-based approaches.
Predicting COVID-19 cases using Bidirectional LSTM on multivariate time series
Sep 10, 2020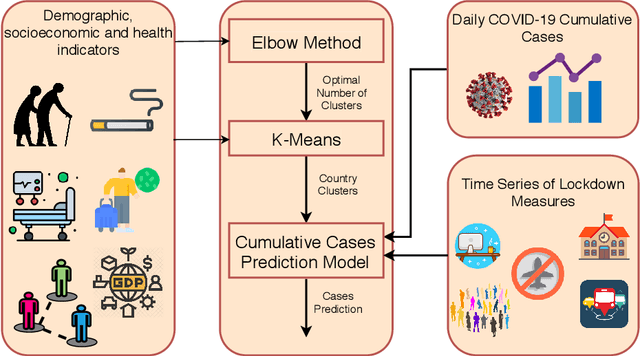
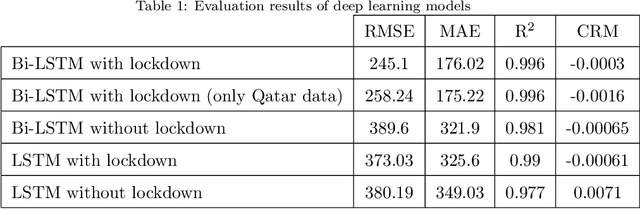
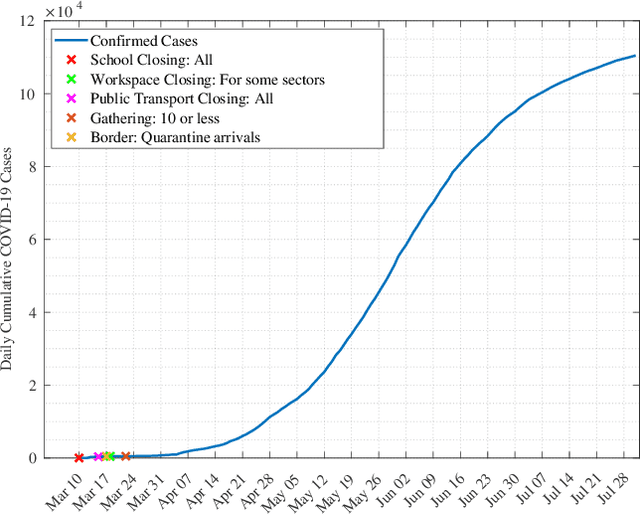
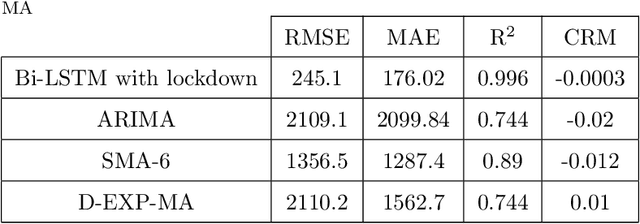
Background: To assist policy makers in taking adequate decisions to stop the spread of COVID-19 pandemic, accurate forecasting of the disease propagation is of paramount importance. Materials and Methods: This paper presents a deep learning approach to forecast the cumulative number of COVID-19 cases using Bidirectional Long Short-Term Memory (Bi-LSTM) network applied to multivariate time series. Unlike other forecasting techniques, our proposed approach first groups the countries having similar demographic and socioeconomic aspects and health sector indicators using K-Means clustering algorithm. The cumulative cases data for each clustered countries enriched with data related to the lockdown measures are fed to the Bidirectional LSTM to train the forecasting model. Results: We validate the effectiveness of the proposed approach by studying the disease outbreak in Qatar. Quantitative evaluation, using multiple evaluation metrics, shows that the proposed technique outperforms state-of-art forecasting approaches. Conclusion: Using data of multiple countries in addition to lockdown measures improve accuracy of the forecast of daily cumulative COVID-19 cases.
Deep-Gap: A deep learning framework for forecasting crowdsourcing supply-demand gap based on imaging time series and residual learning
Nov 02, 2019
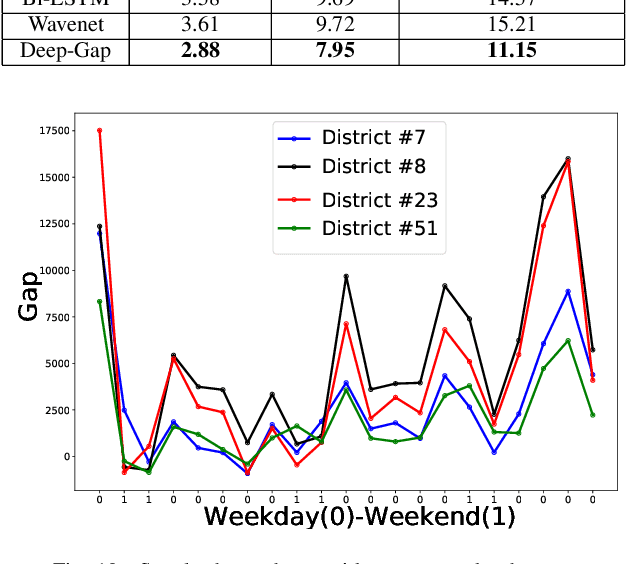
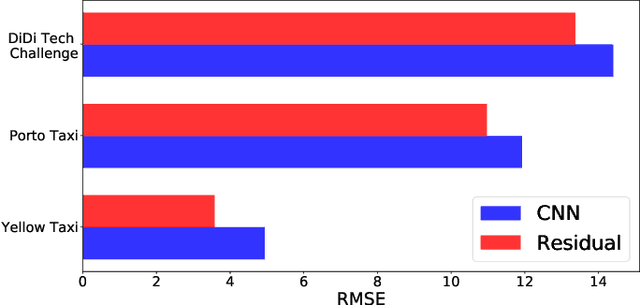
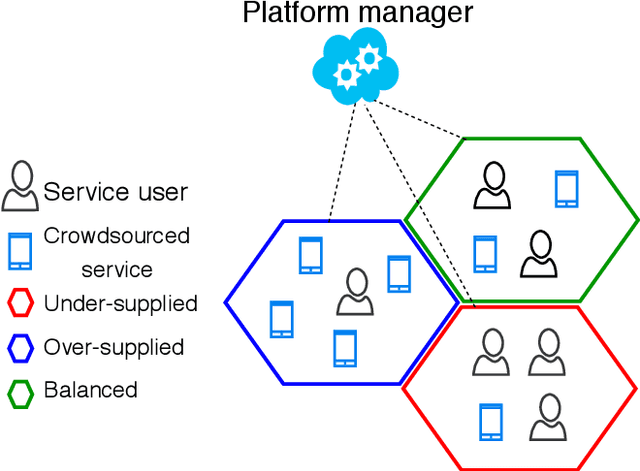
Mobile crowdsourcing has become easier thanks to the widespread of smartphones capable of seamlessly collecting and pushing the desired data to cloud services. However, the success of mobile crowdsourcing relies on balancing the supply and demand by first accurately forecasting spatially and temporally the supply-demand gap, and then providing efficient incentives to encourage participant movements to maintain the desired balance. In this paper, we propose Deep-Gap, a deep learning approach based on residual learning to predict the gap between mobile crowdsourced service supply and demand at a given time and space. The prediction can drive the incentive model to achieve a geographically balanced service coverage in order to avoid the case where some areas are over-supplied while other areas are under-supplied. This allows anticipating the supply-demand gap and redirecting crowdsourced service providers towards target areas. Deep-Gap relies on historical supply-demand time series data as well as available external data such as weather conditions and day type (e.g., weekday, weekend, holiday). First, we roll and encode the time series of supply-demand as images using the Gramian Angular Summation Field (GASF), Gramian Angular Difference Field (GADF) and the Recurrence Plot (REC). These images are then used to train deep Convolutional Neural Networks (CNN) to extract the low and high-level features and forecast the crowdsourced services gap. We conduct comprehensive comparative study by establishing two supply-demand gap forecasting scenarios: with and without external data. Compared to state-of-art approaches, Deep-Gap achieves the lowest forecasting errors in both scenarios.
Cluster validity index based on Jeffrey divergence
Dec 20, 2018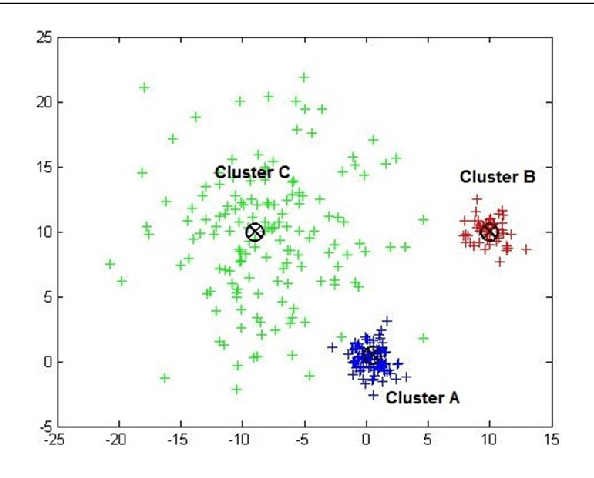
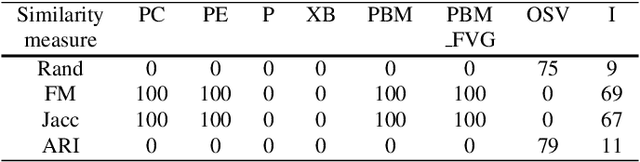
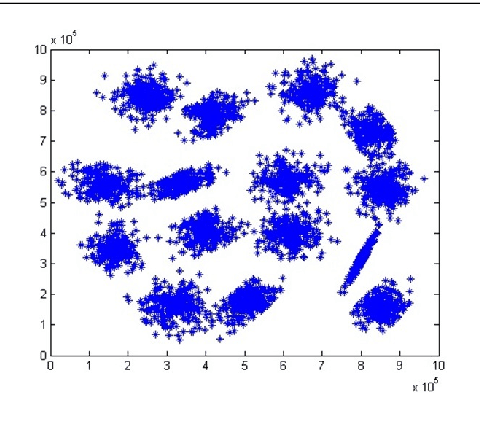
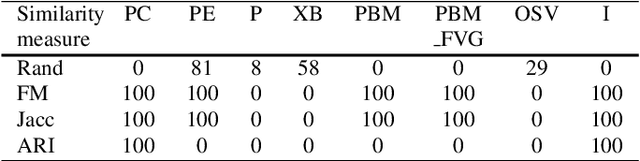
Cluster validity indexes are very important tools designed for two purposes: comparing the performance of clustering algorithms and determining the number of clusters that best fits the data. These indexes are in general constructed by combining a measure of compactness and a measure of separation. A classical measure of compactness is the variance. As for separation, the distance between cluster centers is used. However, such a distance does not always reflect the quality of the partition between clusters and sometimes gives misleading results. In this paper, we propose a new cluster validity index for which Jeffrey divergence is used to measure separation between clusters. Experimental results are conducted using different types of data and comparison with widely used cluster validity indexes demonstrates the outperformance of the proposed index.
A Deep Learning Spatiotemporal Prediction Framework for Mobile Crowdsourced Services
Sep 04, 2018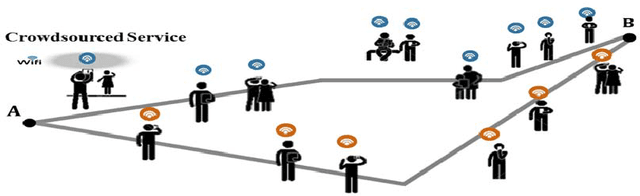

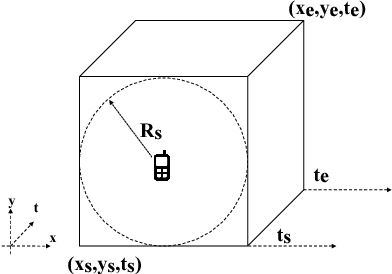
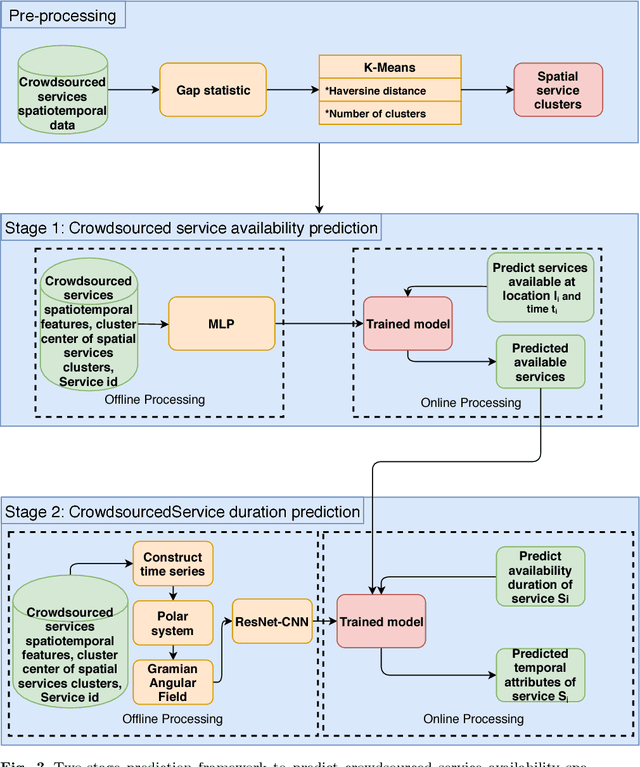
This papers presents a deep learning-based framework to predict crowdsourced service availability spatially and temporally. A novel two-stage prediction model is introduced based on historical spatio-temporal traces of mobile crowdsourced services. The prediction model first clusters mobile crowdsourced services into regions. The availability prediction of a mobile crowdsourced service at a certain location and time is then formulated as a classification problem. To determine the availability duration of predicted mobile crowdsourced services, we formulate a forecasting task of time series using the Gramian Angular Field. We validated the effectiveness of the proposed framework through multiple experiments.
Multimodal deep learning approach for joint EEG-EMG data compression and classification
Mar 27, 2017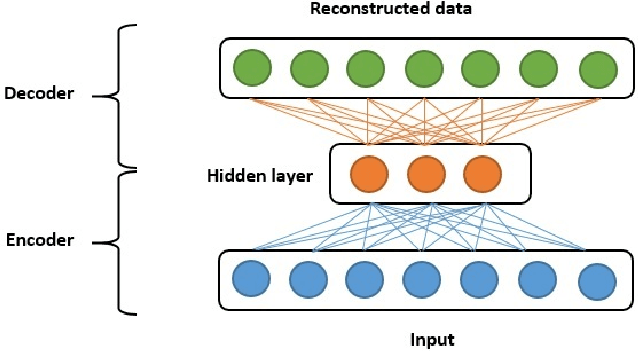

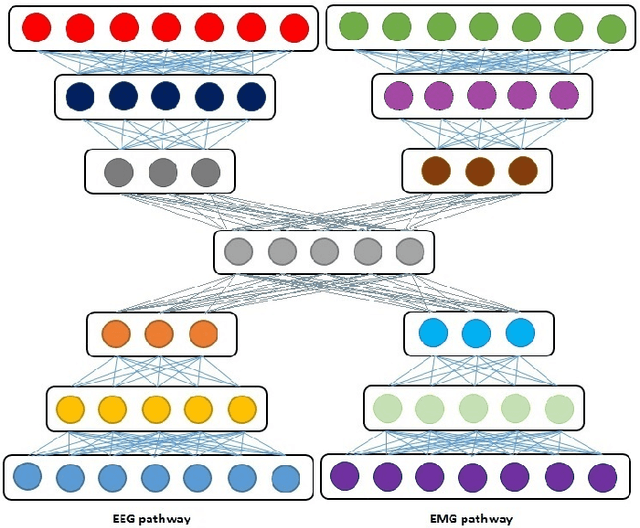
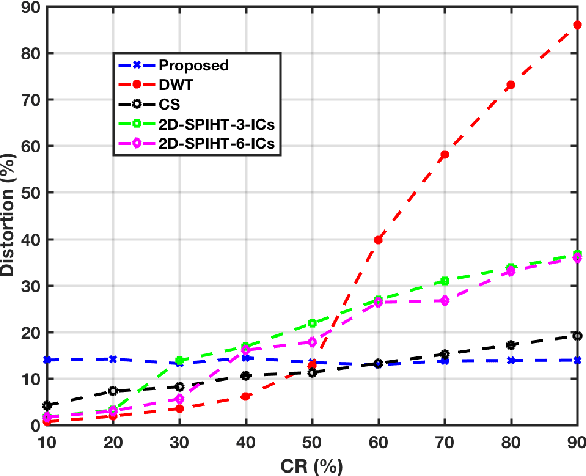
In this paper, we present a joint compression and classification approach of EEG and EMG signals using a deep learning approach. Specifically, we build our system based on the deep autoencoder architecture which is designed not only to extract discriminant features in the multimodal data representation but also to reconstruct the data from the latent representation using encoder-decoder layers. Since autoencoder can be seen as a compression approach, we extend it to handle multimodal data at the encoder layer, reconstructed and retrieved at the decoder layer. We show through experimental results, that exploiting both multimodal data intercorellation and intracorellation 1) Significantly reduces signal distortion particularly for high compression levels 2) Achieves better accuracy in classifying EEG and EMG signals recorded and labeled according to the sentiments of the volunteer.
Multispectral image denoising with optimized vector non-local mean filter
Oct 21, 2016


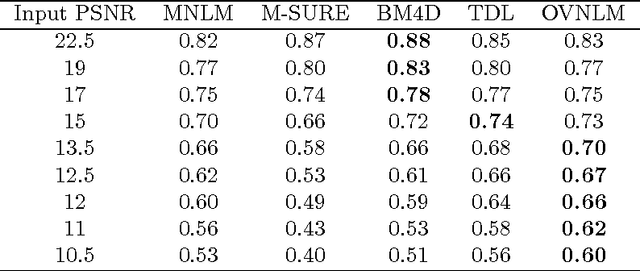
Nowadays, many applications rely on images of high quality to ensure good performance in conducting their tasks. However, noise goes against this objective as it is an unavoidable issue in most applications. Therefore, it is essential to develop techniques to attenuate the impact of noise, while maintaining the integrity of relevant information in images. We propose in this work to extend the application of the Non-Local Means filter (NLM) to the vector case and apply it for denoising multispectral images. The objective is to benefit from the additional information brought by multispectral imaging systems. The NLM filter exploits the redundancy of information in an image to remove noise. A restored pixel is a weighted average of all pixels in the image. In our contribution, we propose an optimization framework where we dynamically fine tune the NLM filter parameters and attenuate its computational complexity by considering only pixels which are most similar to each other in computing a restored pixel. Filter parameters are optimized using Stein's Unbiased Risk Estimator (SURE) rather than using ad hoc means. Experiments have been conducted on multispectral images corrupted with additive white Gaussian noise and PSNR and similarity comparison with other approaches are provided to illustrate the efficiency of our approach in terms of both denoising performance and computation complexity.