 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyKnowledgeRAG (K^2RAG): An Enhanced RAG method for improved LLM question-answering capabilities
Jul 10, 2025Fine-tuning is an immensely resource-intensive process when retraining Large Language Models (LLMs) to incorporate a larger body of knowledge. Although many fine-tuning techniques have been developed to reduce the time and computational cost involved, the challenge persists as LLMs continue to grow in size and complexity. To address this, a new approach to knowledge expansion in LLMs is needed. Retrieval-Augmented Generation (RAG) offers one such alternative by storing external knowledge in a database and retrieving relevant chunks to support question answering. However, naive implementations of RAG face significant limitations in scalability and answer accuracy. This paper introduces KeyKnowledgeRAG (K2RAG), a novel framework designed to overcome these limitations. Inspired by the divide-and-conquer paradigm, K2RAG integrates dense and sparse vector search, knowledge graphs, and text summarization to improve retrieval quality and system efficiency. The framework also includes a preprocessing step that summarizes the training data, significantly reducing the training time. K2RAG was evaluated using the MultiHopRAG dataset, where the proposed pipeline was trained on the document corpus and tested on a separate evaluation set. Results demonstrated notable improvements over common naive RAG implementations. K2RAG achieved the highest mean answer similarity score of 0.57, and reached the highest third quartile (Q3) similarity of 0.82, indicating better alignment with ground-truth answers. In addition to improved accuracy, the framework proved highly efficient. The summarization step reduced the average training time of individual components by 93%, and execution speed was up to 40% faster than traditional knowledge graph-based RAG systems. K2RAG also demonstrated superior scalability, requiring three times less VRAM than several naive RAG implementations tested in this study.
Spatiotemporal Data Mining: A Survey on Challenges and Open Problems
Mar 31, 2021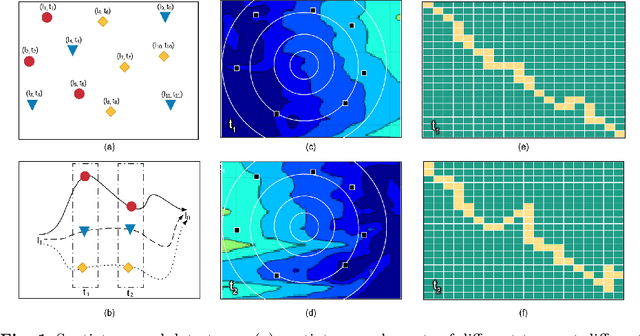
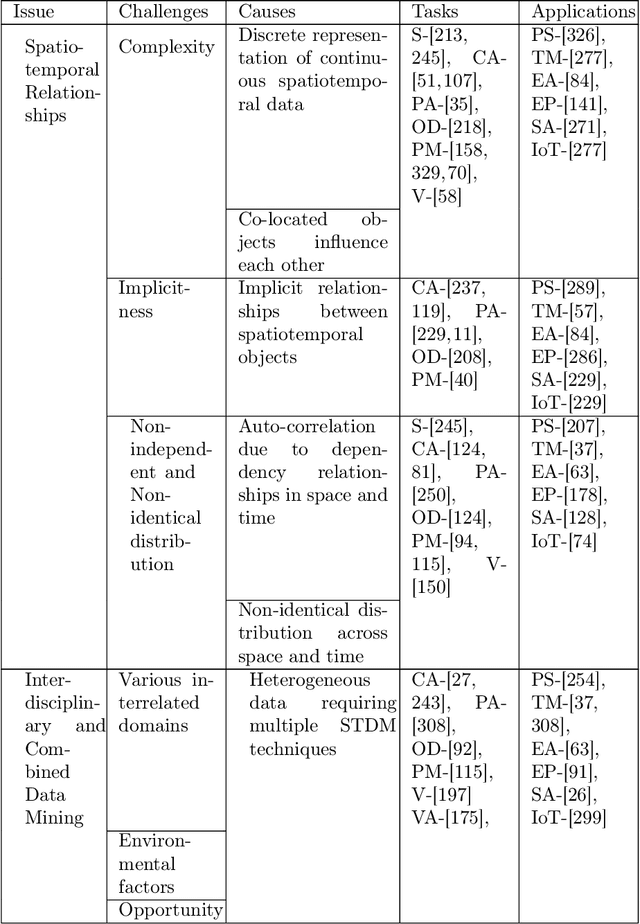
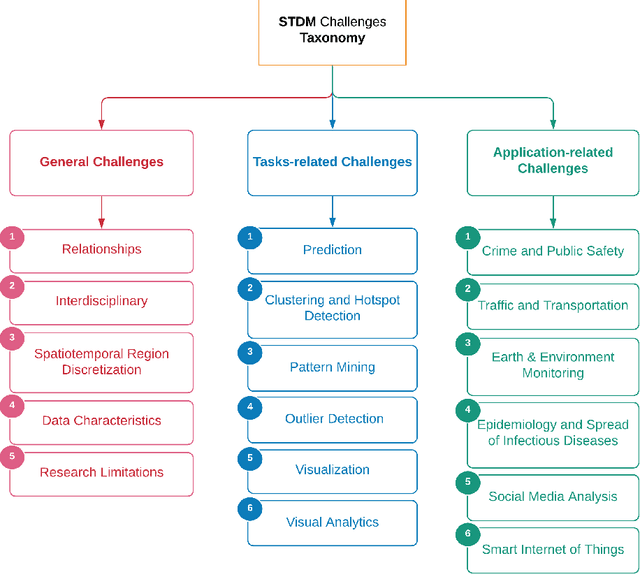
Spatiotemporal data mining (STDM) discovers useful patterns from the dynamic interplay between space and time. Several available surveys capture STDM advances and report a wealth of important progress in this field. However, STDM challenges and problems are not thoroughly discussed and presented in articles of their own. We attempt to fill this gap by providing a comprehensive literature survey on state-of-the-art advances in STDM. We describe the challenging issues and their causes and open gaps of multiple STDM directions and aspects. Specifically, we investigate the challenging issues in regards to spatiotemporal relationships, interdisciplinarity, discretisation, and data characteristics. Moreover, we discuss the limitations in the literature and open research problems related to spatiotemporal data representations, modelling and visualisation, and comprehensiveness of approaches. We explain issues related to STDM tasks of classification, clustering, hotspot detection, association and pattern mining, outlier detection, visualisation, visual analytics, and computer vision tasks. We also highlight STDM issues related to multiple applications including crime and public safety, traffic and transportation, earth and environment monitoring, epidemiology, social media, and Internet of Things.
Spatiotemporal Tensor Completion for Improved Urban Traffic Imputation
Mar 12, 2021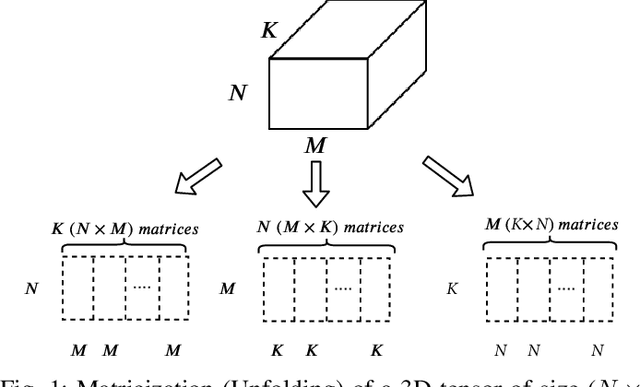
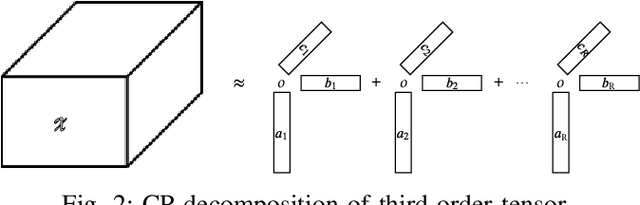

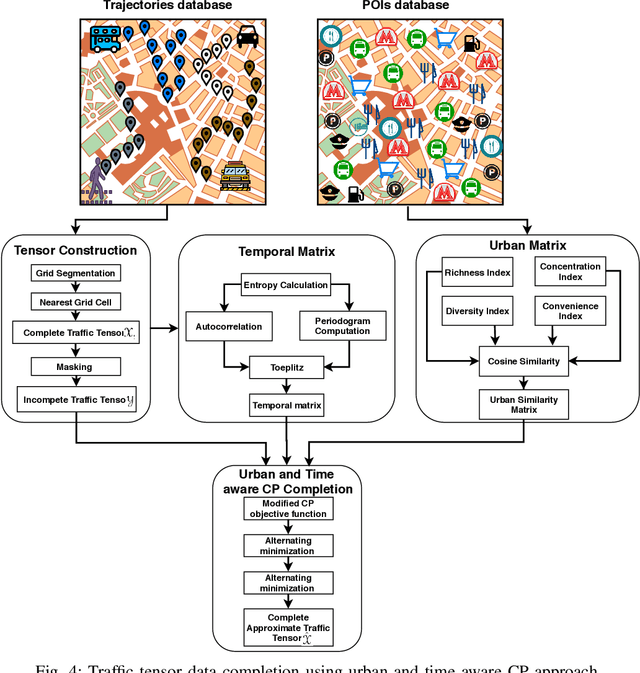
Effective management of urban traffic is important for any smart city initiative. Therefore, the quality of the sensory traffic data is of paramount importance. However, like any sensory data, urban traffic data are prone to imperfections leading to missing measurements. In this paper, we focus on inter-region traffic data completion. We model the inter-region traffic as a spatiotemporal tensor that suffers from missing measurements. To recover the missing data, we propose an enhanced CANDECOMP/PARAFAC (CP) completion approach that considers the urban and temporal aspects of the traffic. To derive the urban characteristics, we divide the area of study into regions. Then, for each region, we compute urban feature vectors inspired from biodiversity which are used to compute the urban similarity matrix. To mine the temporal aspect, we first conduct an entropy analysis to determine the most regular time-series. Then, we conduct a joint Fourier and correlation analysis to compute its periodicity and construct the temporal matrix. Both urban and temporal matrices are fed into a modified CP-completion objective function. To solve this objective, we propose an alternating least square approach that operates on the vectorized version of the inputs. We conduct comprehensive comparative study with two evaluation scenarios. In the first one, we simulate random missing values. In the second scenario, we simulate missing values at a given area and time duration. Our results demonstrate that our approach provides effective recovering performance reaching 26% improvement compared to state-of-art CP approaches and 35% compared to state-of-art generative model-based approaches.
Predicting COVID-19 cases using Bidirectional LSTM on multivariate time series
Sep 10, 2020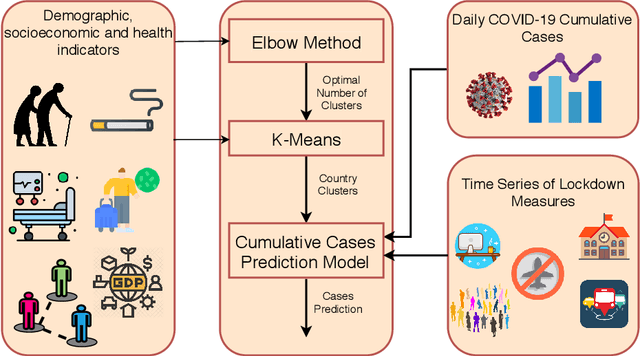
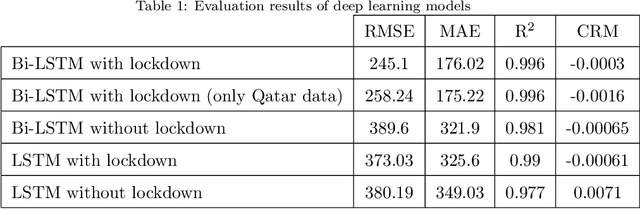
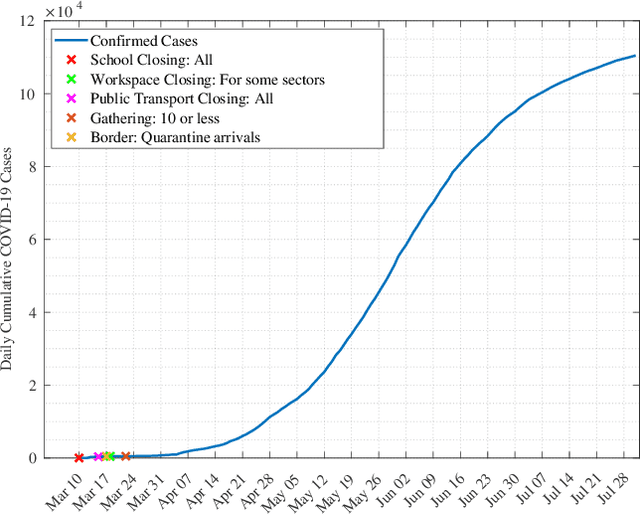
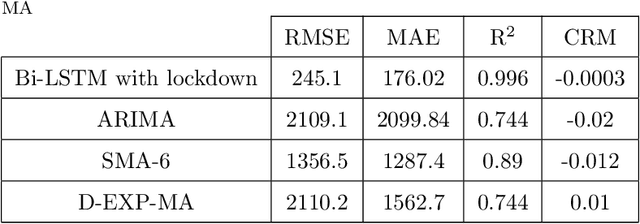
Background: To assist policy makers in taking adequate decisions to stop the spread of COVID-19 pandemic, accurate forecasting of the disease propagation is of paramount importance. Materials and Methods: This paper presents a deep learning approach to forecast the cumulative number of COVID-19 cases using Bidirectional Long Short-Term Memory (Bi-LSTM) network applied to multivariate time series. Unlike other forecasting techniques, our proposed approach first groups the countries having similar demographic and socioeconomic aspects and health sector indicators using K-Means clustering algorithm. The cumulative cases data for each clustered countries enriched with data related to the lockdown measures are fed to the Bidirectional LSTM to train the forecasting model. Results: We validate the effectiveness of the proposed approach by studying the disease outbreak in Qatar. Quantitative evaluation, using multiple evaluation metrics, shows that the proposed technique outperforms state-of-art forecasting approaches. Conclusion: Using data of multiple countries in addition to lockdown measures improve accuracy of the forecast of daily cumulative COVID-19 cases.
Deep-Gap: A deep learning framework for forecasting crowdsourcing supply-demand gap based on imaging time series and residual learning
Nov 02, 2019
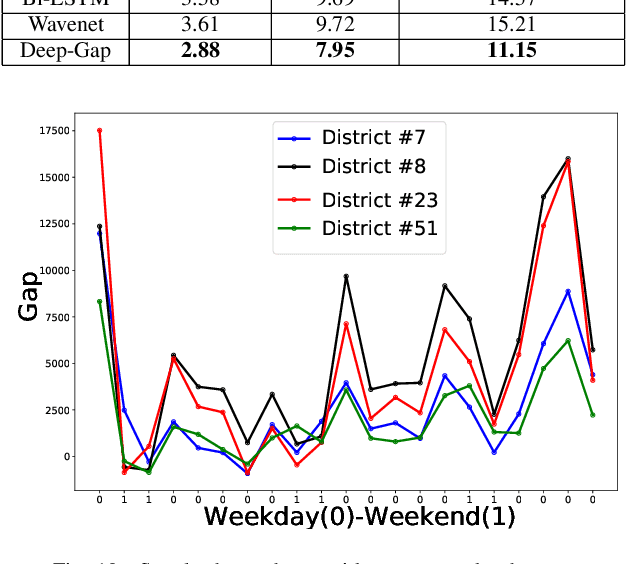
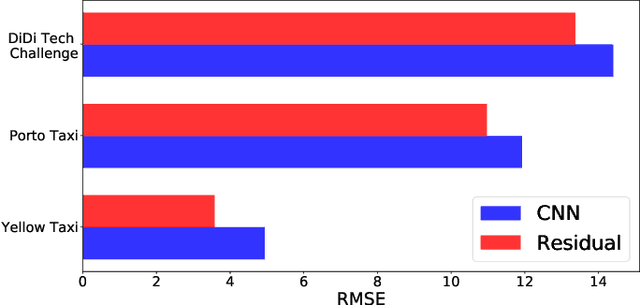
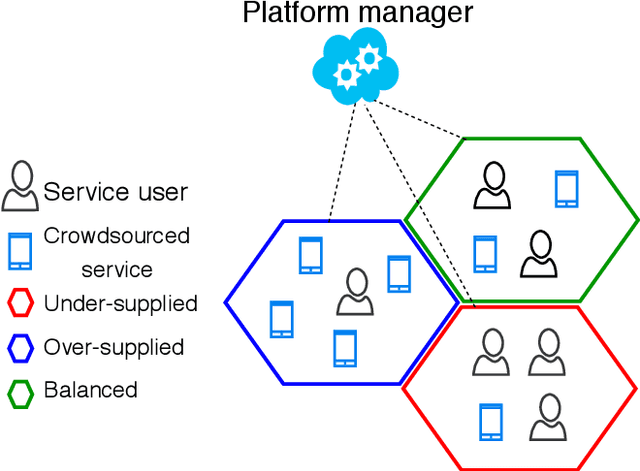
Mobile crowdsourcing has become easier thanks to the widespread of smartphones capable of seamlessly collecting and pushing the desired data to cloud services. However, the success of mobile crowdsourcing relies on balancing the supply and demand by first accurately forecasting spatially and temporally the supply-demand gap, and then providing efficient incentives to encourage participant movements to maintain the desired balance. In this paper, we propose Deep-Gap, a deep learning approach based on residual learning to predict the gap between mobile crowdsourced service supply and demand at a given time and space. The prediction can drive the incentive model to achieve a geographically balanced service coverage in order to avoid the case where some areas are over-supplied while other areas are under-supplied. This allows anticipating the supply-demand gap and redirecting crowdsourced service providers towards target areas. Deep-Gap relies on historical supply-demand time series data as well as available external data such as weather conditions and day type (e.g., weekday, weekend, holiday). First, we roll and encode the time series of supply-demand as images using the Gramian Angular Summation Field (GASF), Gramian Angular Difference Field (GADF) and the Recurrence Plot (REC). These images are then used to train deep Convolutional Neural Networks (CNN) to extract the low and high-level features and forecast the crowdsourced services gap. We conduct comprehensive comparative study by establishing two supply-demand gap forecasting scenarios: with and without external data. Compared to state-of-art approaches, Deep-Gap achieves the lowest forecasting errors in both scenarios.
A Deep Learning Spatiotemporal Prediction Framework for Mobile Crowdsourced Services
Sep 04, 2018

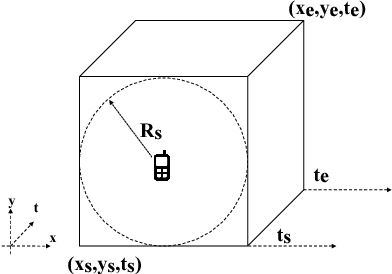
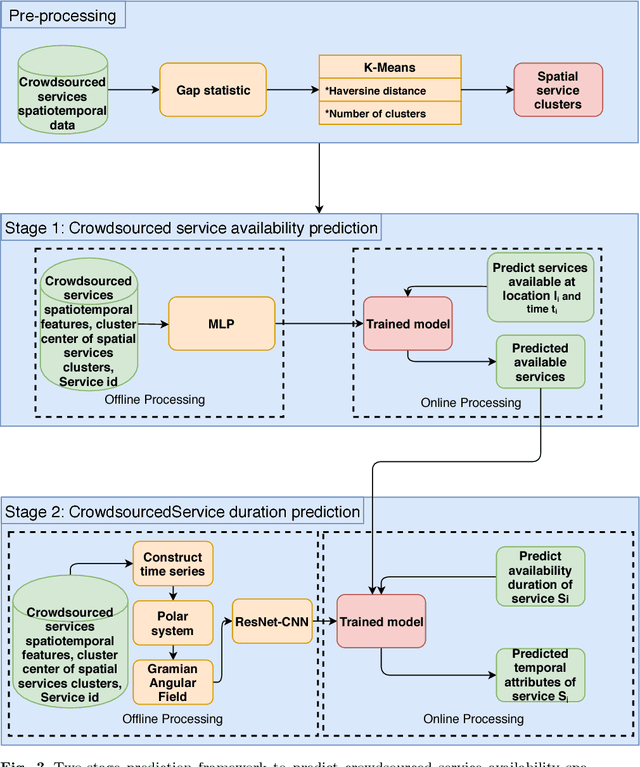
This papers presents a deep learning-based framework to predict crowdsourced service availability spatially and temporally. A novel two-stage prediction model is introduced based on historical spatio-temporal traces of mobile crowdsourced services. The prediction model first clusters mobile crowdsourced services into regions. The availability prediction of a mobile crowdsourced service at a certain location and time is then formulated as a classification problem. To determine the availability duration of predicted mobile crowdsourced services, we formulate a forecasting task of time series using the Gramian Angular Field. We validated the effectiveness of the proposed framework through multiple experiments.