 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Enhanced Particle Swarm Optimization for Hyperparameter Tuning for Deep Learning Models
Apr 19, 2025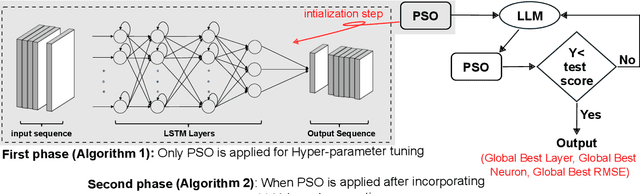
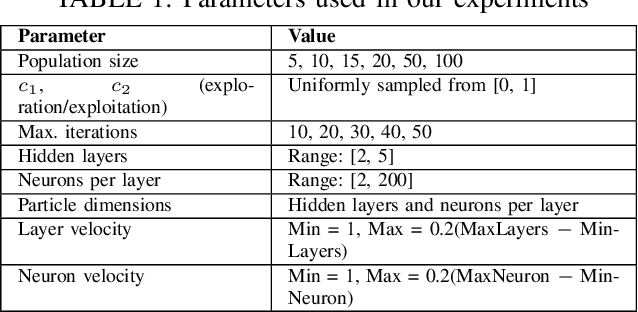
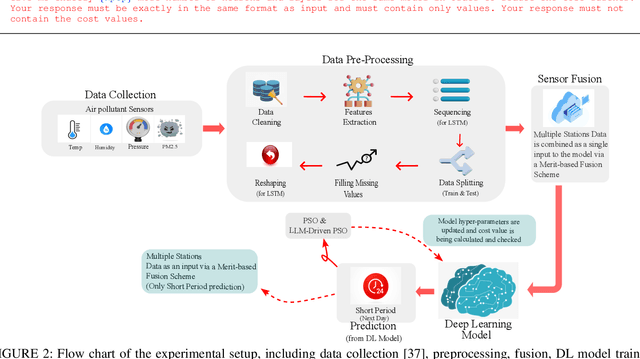

Determining the ideal architecture for deep learning models, such as the number of layers and neurons, is a difficult and resource-intensive process that frequently relies on human tuning or computationally costly optimization approaches. While Particle Swarm Optimization (PSO) and Large Language Models (LLMs) have been individually applied in optimization and deep learning, their combined use for enhancing convergence in numerical optimization tasks remains underexplored. Our work addresses this gap by integrating LLMs into PSO to reduce model evaluations and improve convergence for deep learning hyperparameter tuning. The proposed LLM-enhanced PSO method addresses the difficulties of efficiency and convergence by using LLMs (particularly ChatGPT-3.5 and Llama3) to improve PSO performance, allowing for faster achievement of target objectives. Our method speeds up search space exploration by substituting underperforming particle placements with best suggestions offered by LLMs. Comprehensive experiments across three scenarios -- (1) optimizing the Rastrigin function, (2) using Long Short-Term Memory (LSTM) networks for time series regression, and (3) using Convolutional Neural Networks (CNNs) for material classification -- show that the method significantly improves convergence rates and lowers computational costs. Depending on the application, computational complexity is lowered by 20% to 60% compared to traditional PSO methods. Llama3 achieved a 20% to 40% reduction in model calls for regression tasks, whereas ChatGPT-3.5 reduced model calls by 60% for both regression and classification tasks, all while preserving accuracy and error rates. This groundbreaking methodology offers a very efficient and effective solution for optimizing deep learning models, leading to substantial computational performance improvements across a wide range of applications.
Multi-Agent DRL for Queue-Aware Task Offloading in Hierarchical MEC-Enabled Air-Ground Networks
Mar 05, 2025



Mobile edge computing (MEC)-enabled air-ground networks are a key component of 6G, employing aerial base stations (ABSs) such as unmanned aerial vehicles (UAVs) and high-altitude platform stations (HAPS) to provide dynamic services to ground IoT devices (IoTDs). These IoTDs support real-time applications (e.g., multimedia and Metaverse services) that demand high computational resources and strict quality of service (QoS) guarantees in terms of latency and task queue management. Given their limited energy and processing capabilities, IoTDs rely on UAVs and HAPS to offload tasks for distributed processing, forming a multi-tier MEC system. This paper tackles the overall energy minimization problem in MEC-enabled air-ground integrated networks (MAGIN) by jointly optimizing UAV trajectories, computing resource allocation, and queue-aware task offloading decisions. The optimization is challenging due to the nonconvex, nonlinear nature of this hierarchical system, which renders traditional methods ineffective. We reformulate the problem as a multi-agent Markov decision process (MDP) with continuous action spaces and heterogeneous agents, and propose a novel variant of multi-agent proximal policy optimization with a Beta distribution (MAPPO-BD) to solve it. Extensive simulations show that MAPPO-BD outperforms baseline schemes, achieving superior energy savings and efficient resource management in MAGIN while meeting queue delay and edge computing constraints.
Distributed Traffic Control in Complex Dynamic Roadblocks: A Multi-Agent Deep RL Approach
Dec 31, 2024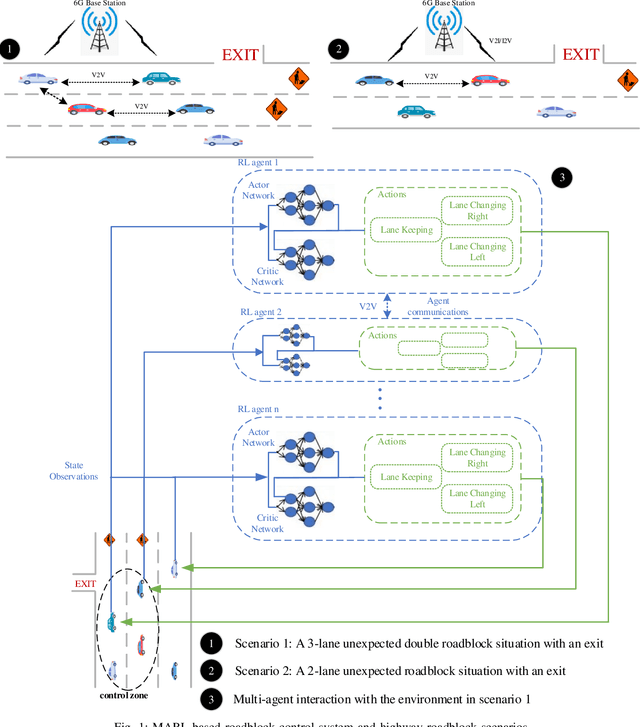



Autonomous Vehicles (AVs) represent a transformative advancement in the transportation industry. These vehicles have sophisticated sensors, advanced algorithms, and powerful computing systems that allow them to navigate and operate without direct human intervention. However, AVs' systems still get overwhelmed when they encounter a complex dynamic change in the environment resulting from an accident or a roadblock for maintenance. The advanced features of Sixth Generation (6G) technology are set to offer strong support to AVs, enabling real-time data exchange and management of complex driving maneuvers. This paper proposes a Multi-Agent Reinforcement Learning (MARL) framework to improve AVs' decision-making in dynamic and complex Intelligent Transportation Systems (ITS) utilizing 6G-V2X communication. The primary objective is to enable AVs to avoid roadblocks efficiently by changing lanes while maintaining optimal traffic flow and maximizing the mean harmonic speed. To ensure realistic operations, key constraints such as minimum vehicle speed, roadblock count, and lane change frequency are integrated. We train and test the proposed MARL model with two traffic simulation scenarios using the SUMO and TraCI interface. Through extensive simulations, we demonstrate that the proposed model adapts to various traffic conditions and achieves efficient and robust traffic flow management. The trained model effectively navigates dynamic roadblocks, promoting improved traffic efficiency in AV operations with more than 70% efficiency over other benchmark solutions.
NetOrchLLM: Mastering Wireless Network Orchestration with Large Language Models
Dec 13, 2024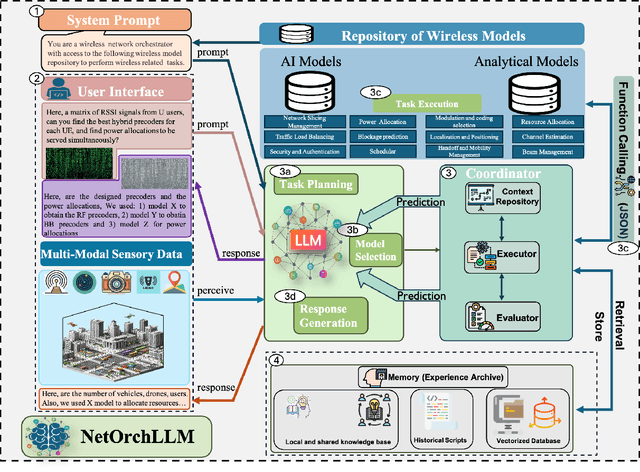
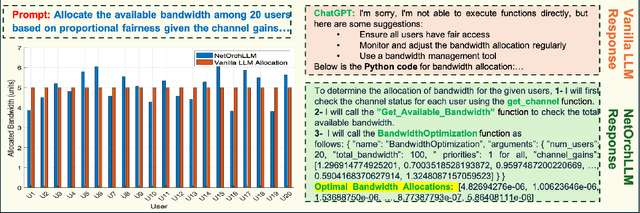
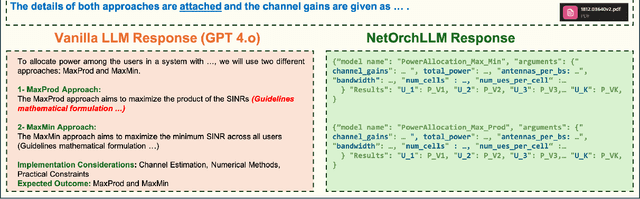

The transition to 6G networks promises unprecedented advancements in wireless communication, with increased data rates, ultra-low latency, and enhanced capacity. However, the complexity of managing and optimizing these next-generation networks presents significant challenges. The advent of large language models (LLMs) has revolutionized various domains by leveraging their sophisticated natural language understanding capabilities. However, the practical application of LLMs in wireless network orchestration and management remains largely unexplored. Existing literature predominantly offers visionary perspectives without concrete implementations, leaving a significant gap in the field. To address this gap, this paper presents NETORCHLLM, a wireless NETwork ORCHestrator LLM framework that uses LLMs to seamlessly orchestrate diverse wireless-specific models from wireless communication communities using their language understanding and generation capabilities. A comprehensive framework is introduced, demonstrating the practical viability of our approach and showcasing how LLMs can be effectively harnessed to optimize dense network operations, manage dynamic environments, and improve overall network performance. NETORCHLLM bridges the theoretical aspirations of prior research with practical, actionable solutions, paving the way for future advancements in integrating generative AI technologies within the wireless communications sector.
Empowering HWNs with Efficient Data Labeling: A Clustered Federated Semi-Supervised Learning Approach
Jan 19, 2024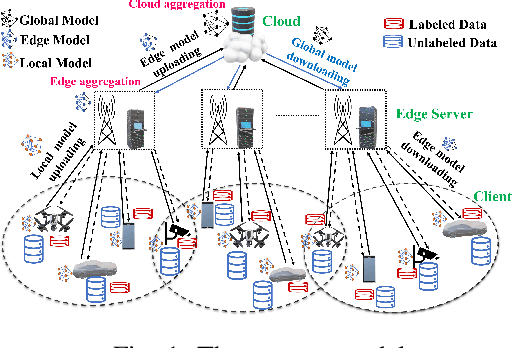
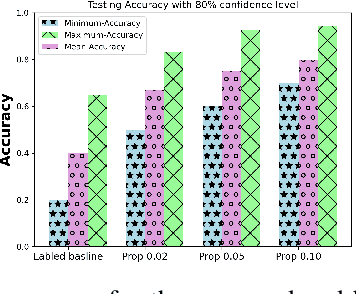
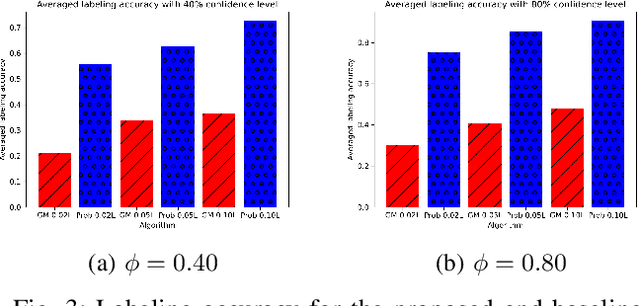
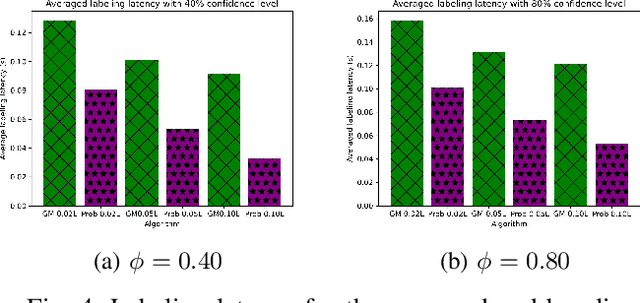
Clustered Federated Multitask Learning (CFL) has gained considerable attention as an effective strategy for overcoming statistical challenges, particularly when dealing with non independent and identically distributed (non IID) data across multiple users. However, much of the existing research on CFL operates under the unrealistic premise that devices have access to accurate ground truth labels. This assumption becomes especially problematic in hierarchical wireless networks (HWNs), where edge networks contain a large amount of unlabeled data, resulting in slower convergence rates and increased processing times, particularly when dealing with two layers of model aggregation. To address these issues, we introduce a novel framework, Clustered Federated Semi-Supervised Learning (CFSL), designed for more realistic HWN scenarios. Our approach leverages a best-performing specialized model algorithm, wherein each device is assigned a specialized model that is highly adept at generating accurate pseudo-labels for unlabeled data, even when the data stems from diverse environments. We validate the efficacy of CFSL through extensive experiments, comparing it with existing methods highlighted in recent literature. Our numerical results demonstrate that CFSL significantly improves upon key metrics such as testing accuracy, labeling accuracy, and labeling latency under varying proportions of labeled and unlabeled data while also accommodating the non-IID nature of the data and the unique characteristics of wireless edge networks.
The Role of Deep Learning in Advancing Proactive Cybersecurity Measures for Smart Grid Networks: A Survey
Jan 11, 2024



As smart grids (SG) increasingly rely on advanced technologies like sensors and communication systems for efficient energy generation, distribution, and consumption, they become enticing targets for sophisticated cyberattacks. These evolving threats demand robust security measures to maintain the stability and resilience of modern energy systems. While extensive research has been conducted, a comprehensive exploration of proactive cyber defense strategies utilizing Deep Learning (DL) in {SG} remains scarce in the literature. This survey bridges this gap, studying the latest DL techniques for proactive cyber defense. The survey begins with an overview of related works and our distinct contributions, followed by an examination of SG infrastructure. Next, we classify various cyber defense techniques into reactive and proactive categories. A significant focus is placed on DL-enabled proactive defenses, where we provide a comprehensive taxonomy of DL approaches, highlighting their roles and relevance in the proactive security of SG. Subsequently, we analyze the most significant DL-based methods currently in use. Further, we explore Moving Target Defense, a proactive defense strategy, and its interactions with DL methodologies. We then provide an overview of benchmark datasets used in this domain to substantiate the discourse.{ This is followed by a critical discussion on their practical implications and broader impact on cybersecurity in Smart Grids.} The survey finally lists the challenges associated with deploying DL-based security systems within SG, followed by an outlook on future developments in this key field.
Adversarial Machine Learning for Social Good: Reframing the Adversary as an Ally
Oct 05, 2023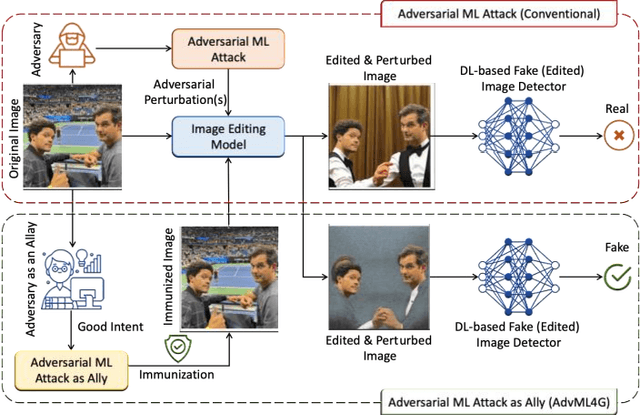
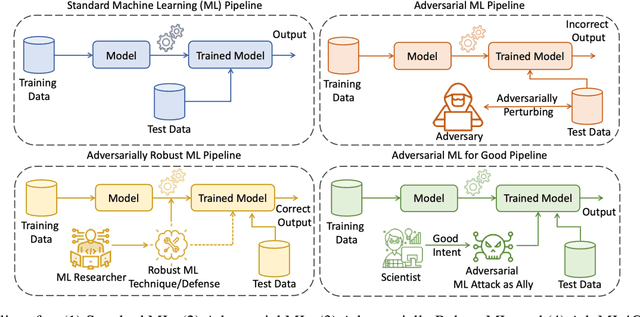
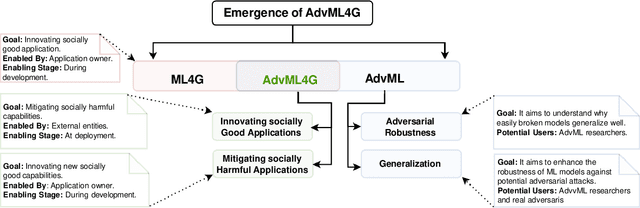
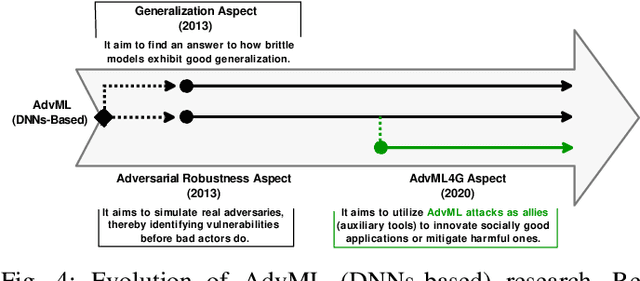
Deep Neural Networks (DNNs) have been the driving force behind many of the recent advances in machine learning. However, research has shown that DNNs are vulnerable to adversarial examples -- input samples that have been perturbed to force DNN-based models to make errors. As a result, Adversarial Machine Learning (AdvML) has gained a lot of attention, and researchers have investigated these vulnerabilities in various settings and modalities. In addition, DNNs have also been found to incorporate embedded bias and often produce unexplainable predictions, which can result in anti-social AI applications. The emergence of new AI technologies that leverage Large Language Models (LLMs), such as ChatGPT and GPT-4, increases the risk of producing anti-social applications at scale. AdvML for Social Good (AdvML4G) is an emerging field that repurposes the AdvML bug to invent pro-social applications. Regulators, practitioners, and researchers should collaborate to encourage the development of pro-social applications and hinder the development of anti-social ones. In this work, we provide the first comprehensive review of the emerging field of AdvML4G. This paper encompasses a taxonomy that highlights the emergence of AdvML4G, a discussion of the differences and similarities between AdvML4G and AdvML, a taxonomy covering social good-related concepts and aspects, an exploration of the motivations behind the emergence of AdvML4G at the intersection of ML4G and AdvML, and an extensive summary of the works that utilize AdvML4G as an auxiliary tool for innovating pro-social applications. Finally, we elaborate upon various challenges and open research issues that require significant attention from the research community.
Continual Conscious Active Fine-Tuning to Robustify Online Machine Learning Models Against Data Distribution Shifts
Nov 02, 2022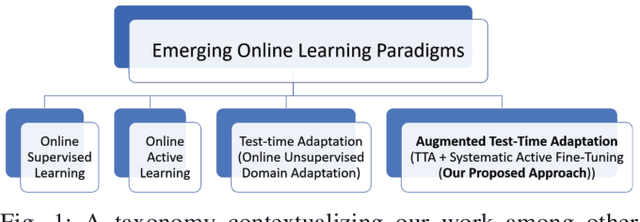
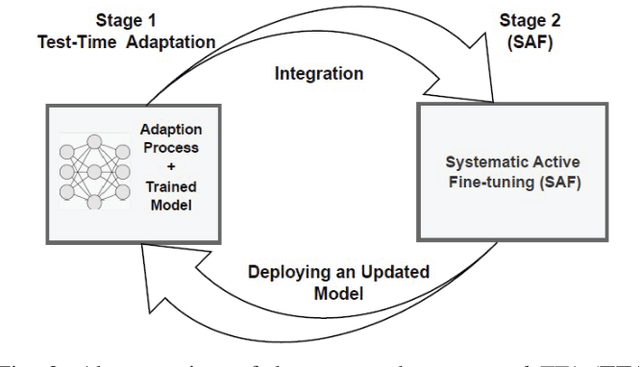
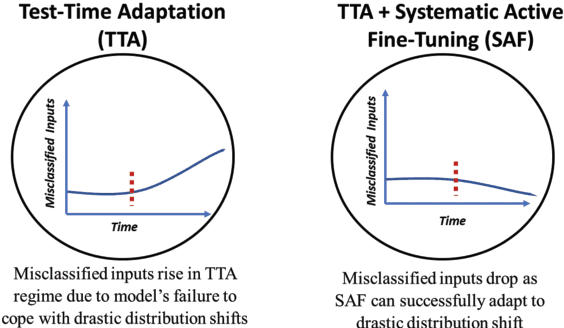
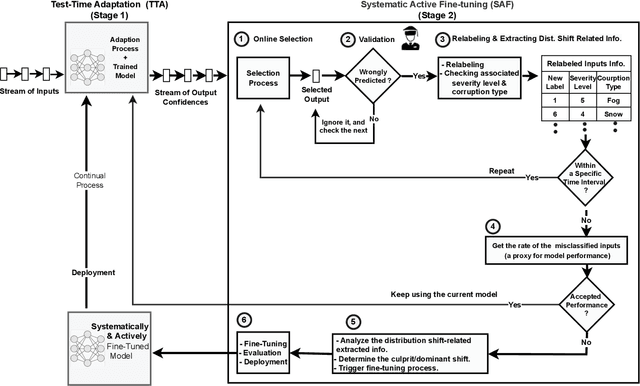
Unlike their offline traditional counterpart, online machine learning models are capable of handling data distribution shifts while serving at the test time. However, they have limitations in addressing this phenomenon. They are either expensive or unreliable. We propose augmenting an online learning approach called test-time adaptation with a continual conscious active fine-tuning layer to develop an enhanced variation that can handle drastic data distribution shifts reliably and cost-effectively. The proposed augmentation incorporates the following aspects: a continual aspect to confront the ever-ending data distribution shifts, a conscious aspect to imply that fine-tuning is a distribution-shift-aware process that occurs at the appropriate time to address the recently detected data distribution shifts, and an active aspect to indicate employing human-machine collaboration for the relabeling to be cost-effective and practical for diverse applications. Our empirical results show that the enhanced test-time adaptation variation outperforms the traditional variation by a factor of two.
Exploration and Exploitation in Federated Learning to Exclude Clients with Poisoned Data
Apr 29, 2022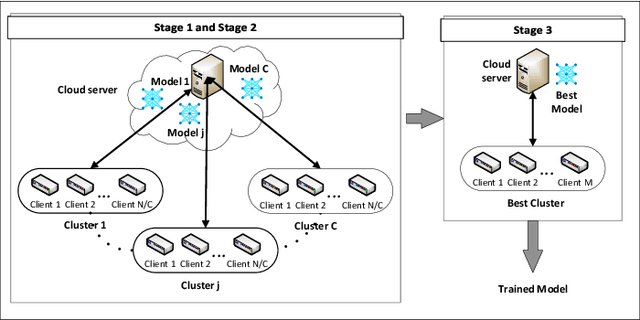
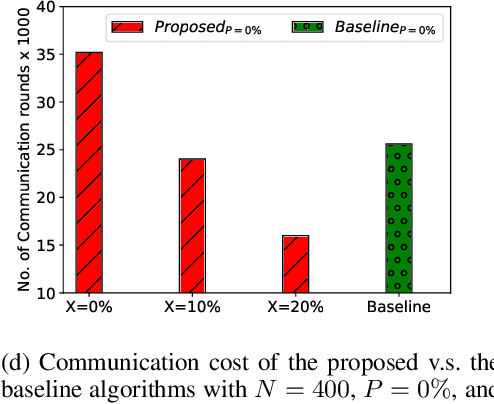
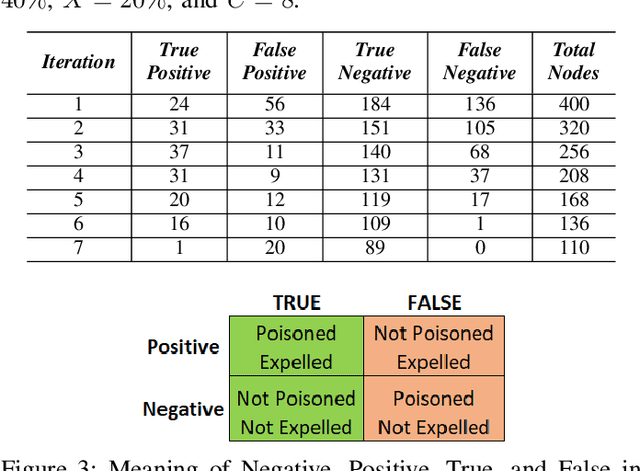
Federated Learning (FL) is one of the hot research topics, and it utilizes Machine Learning (ML) in a distributed manner without directly accessing private data on clients. However, FL faces many challenges, including the difficulty to obtain high accuracy, high communication cost between clients and the server, and security attacks related to adversarial ML. To tackle these three challenges, we propose an FL algorithm inspired by evolutionary techniques. The proposed algorithm groups clients randomly in many clusters, each with a model selected randomly to explore the performance of different models. The clusters are then trained in a repetitive process where the worst performing cluster is removed in each iteration until one cluster remains. In each iteration, some clients are expelled from clusters either due to using poisoned data or low performance. The surviving clients are exploited in the next iteration. The remaining cluster with surviving clients is then used for training the best FL model (i.e., remaining FL model). Communication cost is reduced since fewer clients are used in the final training of the FL model. To evaluate the performance of the proposed algorithm, we conduct a number of experiments using FEMNIST dataset and compare the result against the random FL algorithm. The experimental results show that the proposed algorithm outperforms the baseline algorithm in terms of accuracy, communication cost, and security.
Hierarchical Multi-Agent DRL-Based Framework for Joint Multi-RAT Assignment and Dynamic Resource Allocation in Next-Generation HetNets
Feb 28, 2022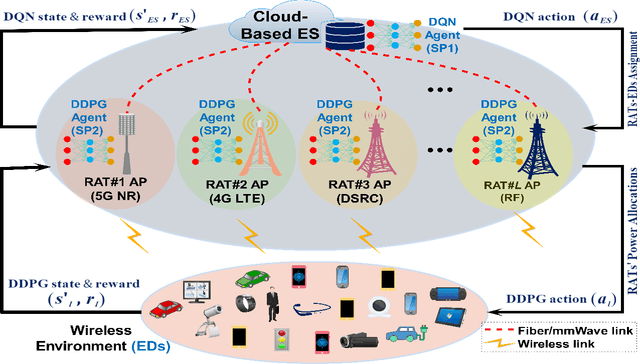
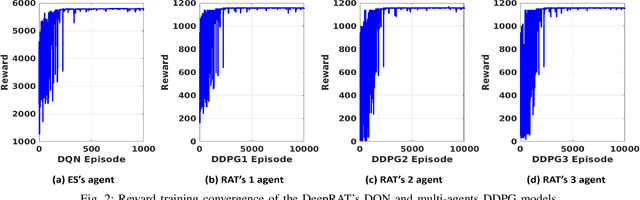
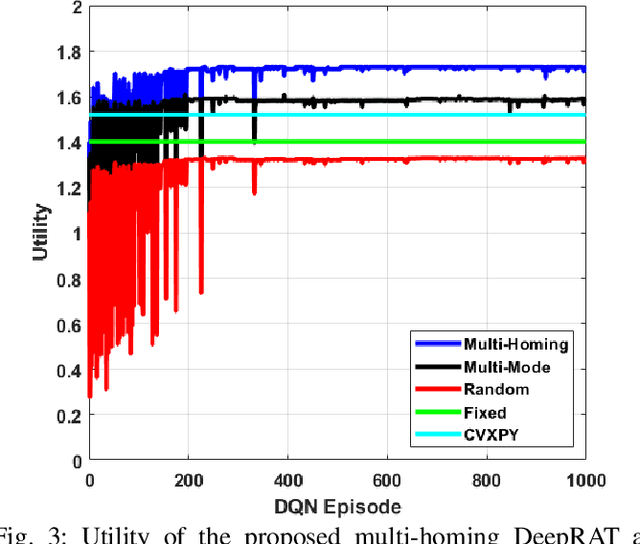
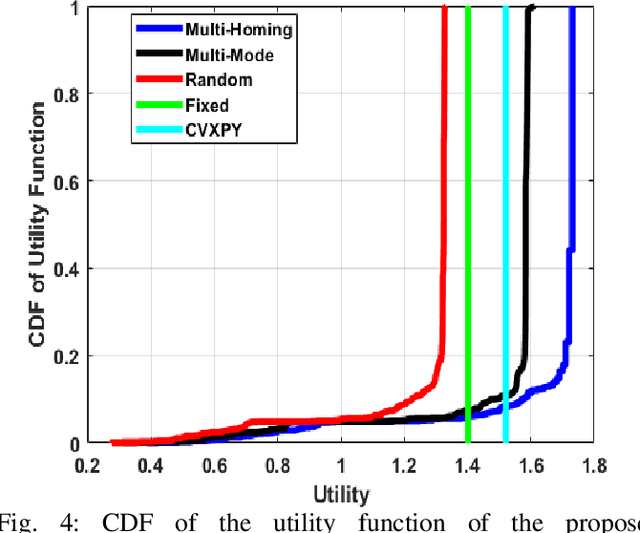
This paper considers the problem of cost-aware downlink sum-rate maximization via joint optimal radio access technologies (RATs) assignment and power allocation in next-generation heterogeneous wireless networks (HetNets). We consider a future HetNet comprised of multi-RATs and serving multi-connectivity edge devices (EDs), and we formulate the problem as mixed-integer non-linear programming (MINP) problem. Due to the high complexity and combinatorial nature of this problem and the difficulty to solve it using conventional methods, we propose a hierarchical multi-agent deep reinforcement learning (DRL)-based framework, called DeepRAT, to solve it efficiently and learn system dynamics. In particular, the DeepRAT framework decomposes the problem into two main stages; the RATs-EDs assignment stage, which implements a single-agent Deep Q Network (DQN) algorithm, and the power allocation stage, which utilizes a multi-agent Deep Deterministic Policy Gradient (DDPG) algorithm. Using simulations, we demonstrate how the various DRL agents efficiently interact to learn system dynamics and derive the global optimal policy. Furthermore, our simulation results show that the proposed DeepRAT algorithm outperforms existing state-of-the-art heuristic approaches in terms of network utility. Finally, we quantitatively show the ability of the DeepRAT model to quickly and dynamically adapt to abrupt changes in network dynamics, such as EDs mobility.