 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration and Exploitation in Federated Learning to Exclude Clients with Poisoned Data
Apr 29, 2022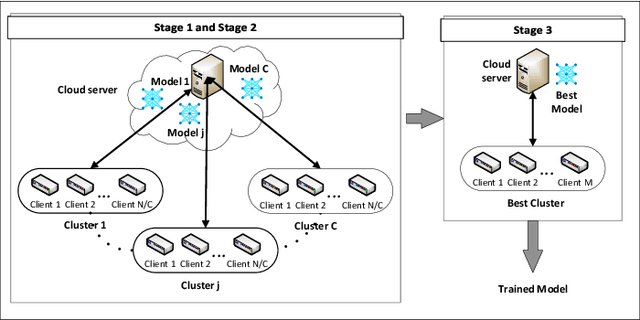
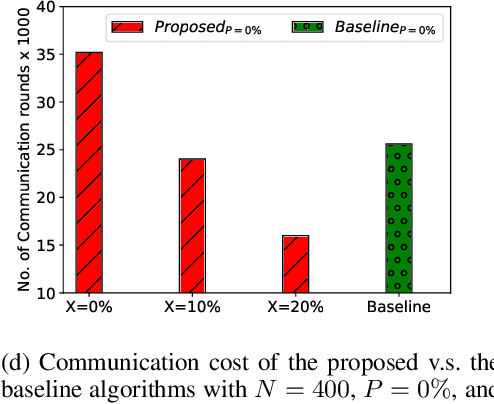
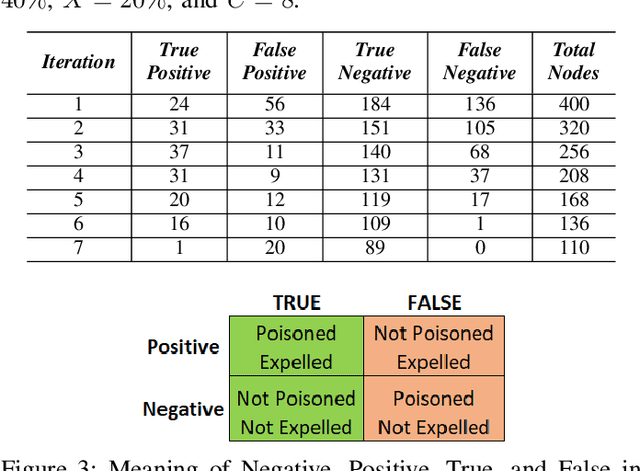
Federated Learning (FL) is one of the hot research topics, and it utilizes Machine Learning (ML) in a distributed manner without directly accessing private data on clients. However, FL faces many challenges, including the difficulty to obtain high accuracy, high communication cost between clients and the server, and security attacks related to adversarial ML. To tackle these three challenges, we propose an FL algorithm inspired by evolutionary techniques. The proposed algorithm groups clients randomly in many clusters, each with a model selected randomly to explore the performance of different models. The clusters are then trained in a repetitive process where the worst performing cluster is removed in each iteration until one cluster remains. In each iteration, some clients are expelled from clusters either due to using poisoned data or low performance. The surviving clients are exploited in the next iteration. The remaining cluster with surviving clients is then used for training the best FL model (i.e., remaining FL model). Communication cost is reduced since fewer clients are used in the final training of the FL model. To evaluate the performance of the proposed algorithm, we conduct a number of experiments using FEMNIST dataset and compare the result against the random FL algorithm. The experimental results show that the proposed algorithm outperforms the baseline algorithm in terms of accuracy, communication cost, and security.
Budgeted Online Selection of Candidate IoT Clients to Participate in Federated Learning
Nov 16, 2020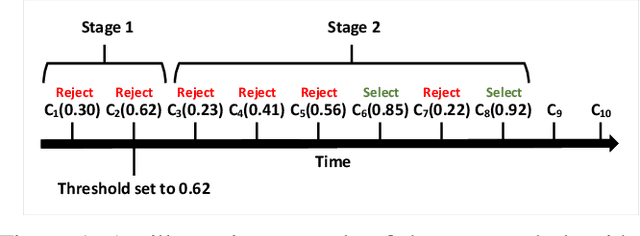
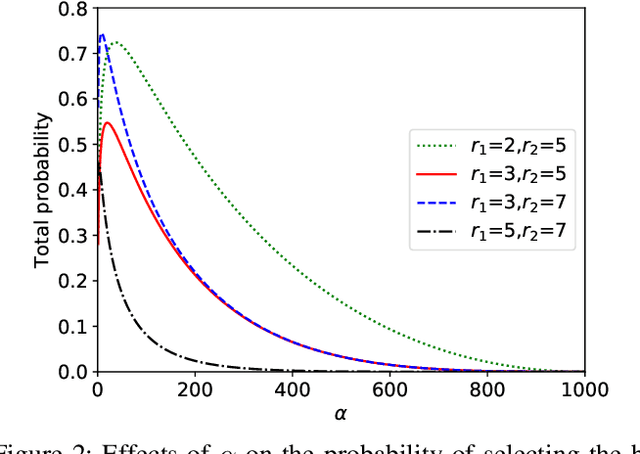
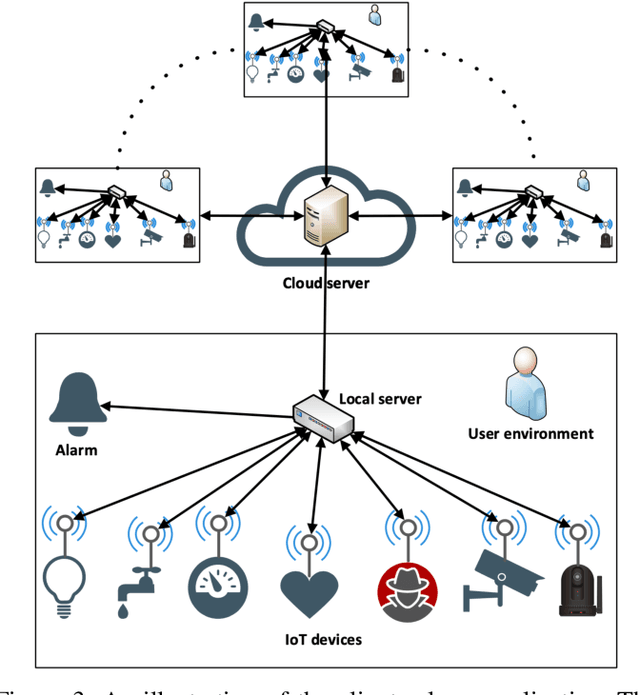

Machine Learning (ML), and Deep Learning (DL) in particular, play a vital role in providing smart services to the industry. These techniques however suffer from privacy and security concerns since data is collected from clients and then stored and processed at a central location. Federated Learning (FL), an architecture in which model parameters are exchanged instead of client data, has been proposed as a solution to these concerns. Nevertheless, FL trains a global model by communicating with clients over communication rounds, which introduces more traffic on the network and increases the convergence time to the target accuracy. In this work, we solve the problem of optimizing accuracy in stateful FL with a budgeted number of candidate clients by selecting the best candidate clients in terms of test accuracy to participate in the training process. Next, we propose an online stateful FL heuristic to find the best candidate clients. Additionally, we propose an IoT client alarm application that utilizes the proposed heuristic in training a stateful FL global model based on IoT device type classification to alert clients about unauthorized IoT devices in their environment. To test the efficiency of the proposed online heuristic, we conduct several experiments using a real dataset and compare the results against state-of-the-art algorithms. Our results indicate that the proposed heuristic outperforms the online random algorithm with up to 27% gain in accuracy. Additionally, the performance of the proposed online heuristic is comparable to the performance of the best offline algorithm.
Trust-Based Cloud Machine Learning Model Selection For Industrial IoT and Smart City Services
Aug 11, 2020With Machine Learning (ML) services now used in a number of mission-critical human-facing domains, ensuring the integrity and trustworthiness of ML models becomes all-important. In this work, we consider the paradigm where cloud service providers collect big data from resource-constrained devices for building ML-based prediction models that are then sent back to be run locally on the intermittently-connected resource-constrained devices. Our proposed solution comprises an intelligent polynomial-time heuristic that maximizes the level of trust of ML models by selecting and switching between a subset of the ML models from a superset of models in order to maximize the trustworthiness while respecting the given reconfiguration budget/rate and reducing the cloud communication overhead. We evaluate the performance of our proposed heuristic using two case studies. First, we consider Industrial IoT (IIoT) services, and as a proxy for this setting, we use the turbofan engine degradation simulation dataset to predict the remaining useful life of an engine. Our results in this setting show that the trust level of the selected models is 0.49% to 3.17% less compared to the results obtained using Integer Linear Programming (ILP). Second, we consider Smart Cities services, and as a proxy of this setting, we use an experimental transportation dataset to predict the number of cars. Our results show that the selected model's trust level is 0.7% to 2.53% less compared to the results obtained using ILP. We also show that our proposed heuristic achieves an optimal competitive ratio in a polynomial-time approximation scheme for the problem.