 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Enhanced Particle Swarm Optimization for Hyperparameter Tuning for Deep Learning Models
Apr 19, 2025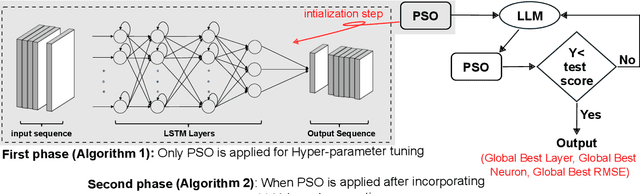
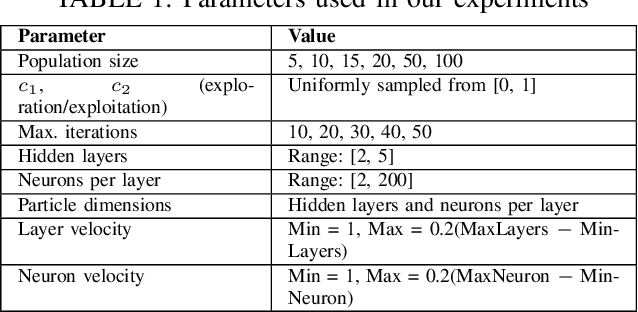
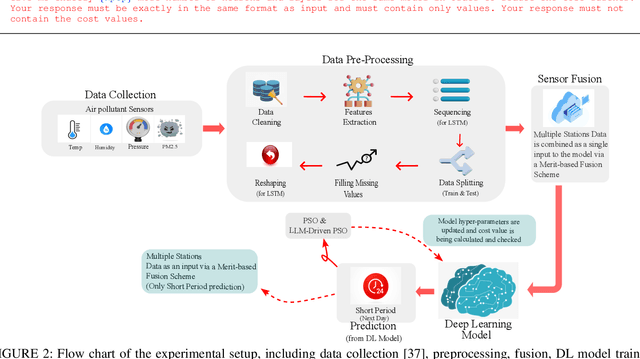

Determining the ideal architecture for deep learning models, such as the number of layers and neurons, is a difficult and resource-intensive process that frequently relies on human tuning or computationally costly optimization approaches. While Particle Swarm Optimization (PSO) and Large Language Models (LLMs) have been individually applied in optimization and deep learning, their combined use for enhancing convergence in numerical optimization tasks remains underexplored. Our work addresses this gap by integrating LLMs into PSO to reduce model evaluations and improve convergence for deep learning hyperparameter tuning. The proposed LLM-enhanced PSO method addresses the difficulties of efficiency and convergence by using LLMs (particularly ChatGPT-3.5 and Llama3) to improve PSO performance, allowing for faster achievement of target objectives. Our method speeds up search space exploration by substituting underperforming particle placements with best suggestions offered by LLMs. Comprehensive experiments across three scenarios -- (1) optimizing the Rastrigin function, (2) using Long Short-Term Memory (LSTM) networks for time series regression, and (3) using Convolutional Neural Networks (CNNs) for material classification -- show that the method significantly improves convergence rates and lowers computational costs. Depending on the application, computational complexity is lowered by 20% to 60% compared to traditional PSO methods. Llama3 achieved a 20% to 40% reduction in model calls for regression tasks, whereas ChatGPT-3.5 reduced model calls by 60% for both regression and classification tasks, all while preserving accuracy and error rates. This groundbreaking methodology offers a very efficient and effective solution for optimizing deep learning models, leading to substantial computational performance improvements across a wide range of applications.
A Survey of Social Cybersecurity: Techniques for Attack Detection, Evaluations, Challenges, and Future Prospects
Apr 06, 2025



In today's digital era, the Internet, especially social media platforms, plays a significant role in shaping public opinions, attitudes, and beliefs. Unfortunately, the credibility of scientific information sources is often undermined by the spread of misinformation through various means, including technology-driven tools like bots, cyborgs, trolls, sock-puppets, and deep fakes. This manipulation of public discourse serves antagonistic business agendas and compromises civil society. In response to this challenge, a new scientific discipline has emerged: social cybersecurity.
Safeguarding connected autonomous vehicle communication: Protocols, intra- and inter-vehicular attacks and defenses
Feb 06, 2025



The advancements in autonomous driving technology, coupled with the growing interest from automotive manufacturers and tech companies, suggest a rising adoption of Connected Autonomous Vehicles (CAVs) in the near future. Despite some evidence of higher accident rates in AVs, these incidents tend to result in less severe injuries compared to traditional vehicles due to cooperative safety measures. However, the increased complexity of CAV systems exposes them to significant security vulnerabilities, potentially compromising their performance and communication integrity. This paper contributes by presenting a detailed analysis of existing security frameworks and protocols, focusing on intra- and inter-vehicle communications. We systematically evaluate the effectiveness of these frameworks in addressing known vulnerabilities and propose a set of best practices for enhancing CAV communication security. The paper also provides a comprehensive taxonomy of attack vectors in CAV ecosystems and suggests future research directions for designing more robust security mechanisms. Our key contributions include the development of a new classification system for CAV security threats, the proposal of practical security protocols, and the introduction of use cases that demonstrate how these protocols can be integrated into real-world CAV applications. These insights are crucial for advancing secure CAV adoption and ensuring the safe integration of autonomous vehicles into intelligent transportation systems.
Weighted Sampled Split Learning (WSSL): Balancing Privacy, Robustness, and Fairness in Distributed Learning Environments
Oct 27, 2023This study presents Weighted Sampled Split Learning (WSSL), an innovative framework tailored to bolster privacy, robustness, and fairness in distributed machine learning systems. Unlike traditional approaches, WSSL disperses the learning process among multiple clients, thereby safeguarding data confidentiality. Central to WSSL's efficacy is its utilization of weighted sampling. This approach ensures equitable learning by tactically selecting influential clients based on their contributions. Our evaluation of WSSL spanned various client configurations and employed two distinct datasets: Human Gait Sensor and CIFAR-10. We observed three primary benefits: heightened model accuracy, enhanced robustness, and maintained fairness across diverse client compositions. Notably, our distributed frameworks consistently surpassed centralized counterparts, registering accuracy peaks of 82.63% and 75.51% for the Human Gait Sensor and CIFAR-10 datasets, respectively. These figures contrast with the top accuracies of 81.12% and 58.60% achieved by centralized systems. Collectively, our findings champion WSSL as a potent and scalable successor to conventional centralized learning, marking it as a pivotal stride forward in privacy-focused, resilient, and impartial distributed machine learning.
Motion Comfort Optimization for Autonomous Vehicles: Concepts, Methods, and Techniques
Jun 15, 2023



This article outlines the architecture of autonomous driving and related complementary frameworks from the perspective of human comfort. The technical elements for measuring Autonomous Vehicle (AV) user comfort and psychoanalysis are listed here. At the same time, this article introduces the technology related to the structure of automatic driving and the reaction time of automatic driving. We also discuss the technical details related to the automatic driving comfort system, the response time of the AV driver, the comfort level of the AV, motion sickness, and related optimization technologies. The function of the sensor is affected by various factors. Since the sensor of automatic driving mainly senses the environment around a vehicle, including "the weather" which introduces the challenges and limitations of second-hand sensors in autonomous vehicles under different weather conditions. The comfort and safety of autonomous driving are also factors that affect the development of autonomous driving technologies. This article further analyzes the impact of autonomous driving on the user's physical and psychological states and how the comfort factors of autonomous vehicles affect the automotive market. Also, part of our focus is on the benefits and shortcomings of autonomous driving. The goal is to present an exhaustive overview of the most relevant technical matters to help researchers and application developers comprehend the different comfort factors and systems of autonomous driving. Finally, we provide detailed automated driving comfort use cases to illustrate the comfort-related issues of autonomous driving. Then, we provide implications and insights for the future of autonomous driving.
Topic Modeling Based on Two-Step Flow Theory: Application to Tweets about Bitcoin
Mar 03, 2023Digital cryptocurrencies such as Bitcoin have exploded in recent years in both popularity and value. By their novelty, cryptocurrencies tend to be both volatile and highly speculative. The capricious nature of these coins is helped facilitated by social media networks such as Twitter. However, not everyone's opinion matters equally, with most posts garnering little to no attention. Additionally, the majority of tweets are retweeted from popular posts. We must determine whose opinion matters and the difference between influential and non-influential users. This study separates these two groups and analyzes the differences between them. It uses Hypertext-induced Topic Selection (HITS) algorithm, which segregates the dataset based on influence. Topic modeling is then employed to uncover differences in each group's speech types and what group may best represent the entire community. We found differences in language and interest between these two groups regarding Bitcoin and that the opinion leaders of Twitter are not aligned with the majority of users. There were 2559 opinion leaders (0.72% of users) who accounted for 80% of the authority and the majority (99.28%) users for the remaining 20% out of a total of 355,139 users.
CovidMis20: COVID-19 Misinformation Detection System on Twitter Tweets using Deep Learning Models
Sep 13, 2022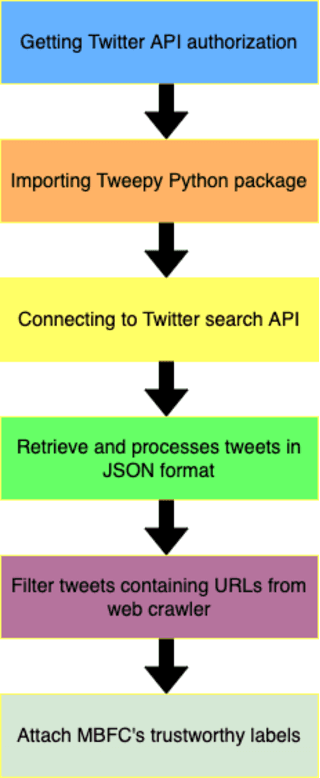
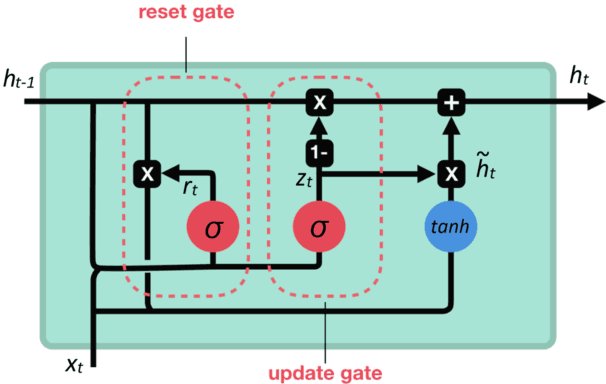
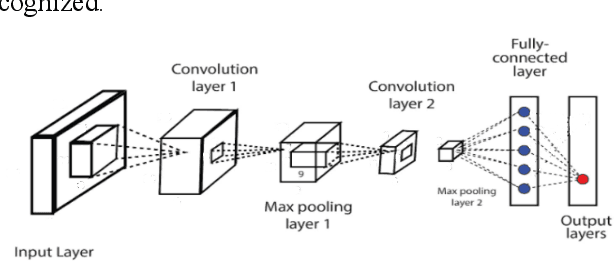
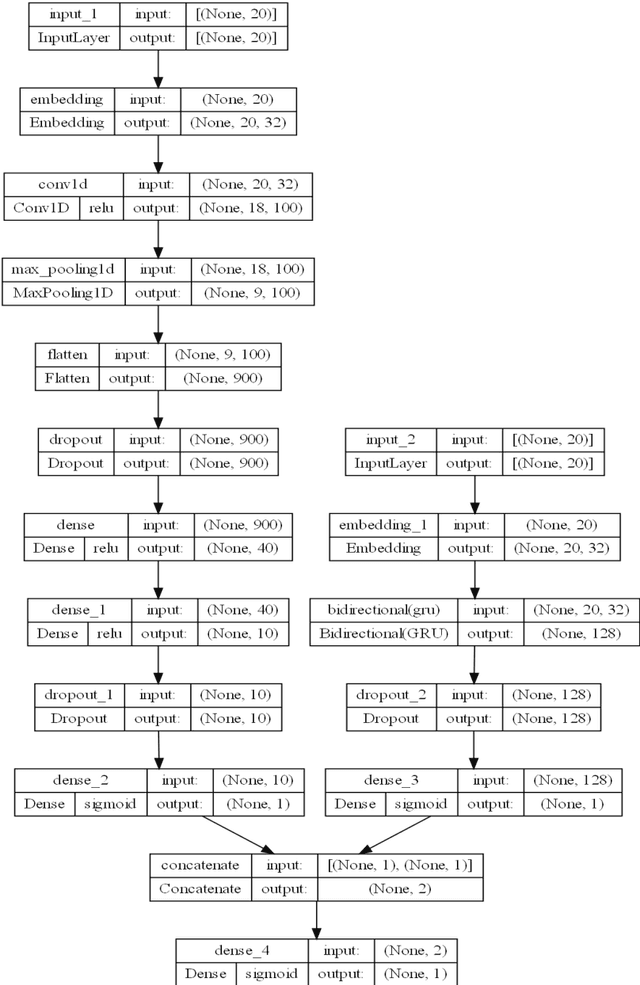
Online news and information sources are convenient and accessible ways to learn about current issues. For instance, more than 300 million people engage with posts on Twitter globally, which provides the possibility to disseminate misleading information. There are numerous cases where violent crimes have been committed due to fake news. This research presents the CovidMis20 dataset (COVID-19 Misinformation 2020 dataset), which consists of 1,375,592 tweets collected from February to July 2020. CovidMis20 can be automatically updated to fetch the latest news and is publicly available at: https://github.com/everythingguy/CovidMis20. This research was conducted using Bi-LSTM deep learning and an ensemble CNN+Bi-GRU for fake news detection. The results showed that, with testing accuracy of 92.23% and 90.56%, respectively, the ensemble CNN+Bi-GRU model consistently provided higher accuracy than the Bi-LSTM model.
Exploration and Exploitation in Federated Learning to Exclude Clients with Poisoned Data
Apr 29, 2022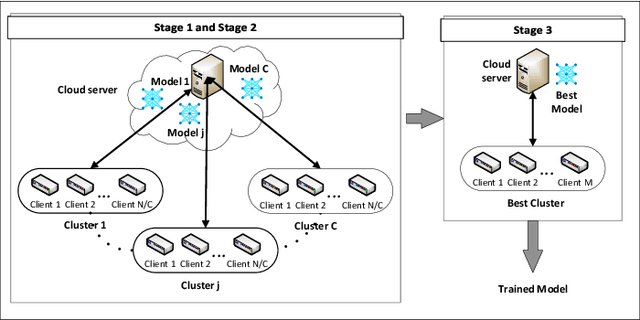
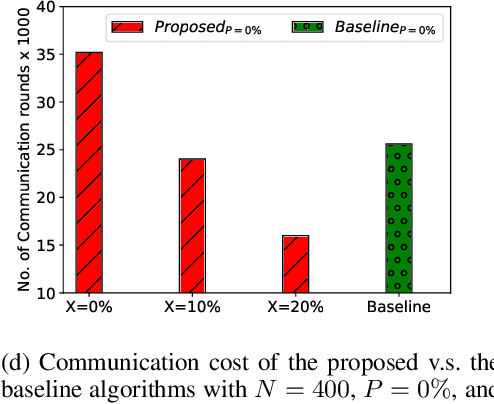
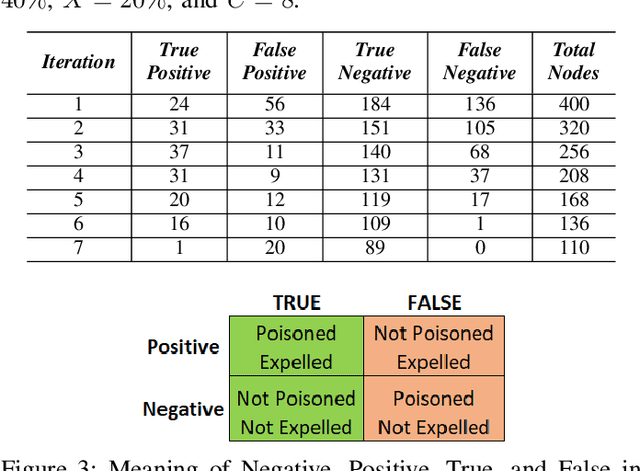
Federated Learning (FL) is one of the hot research topics, and it utilizes Machine Learning (ML) in a distributed manner without directly accessing private data on clients. However, FL faces many challenges, including the difficulty to obtain high accuracy, high communication cost between clients and the server, and security attacks related to adversarial ML. To tackle these three challenges, we propose an FL algorithm inspired by evolutionary techniques. The proposed algorithm groups clients randomly in many clusters, each with a model selected randomly to explore the performance of different models. The clusters are then trained in a repetitive process where the worst performing cluster is removed in each iteration until one cluster remains. In each iteration, some clients are expelled from clusters either due to using poisoned data or low performance. The surviving clients are exploited in the next iteration. The remaining cluster with surviving clients is then used for training the best FL model (i.e., remaining FL model). Communication cost is reduced since fewer clients are used in the final training of the FL model. To evaluate the performance of the proposed algorithm, we conduct a number of experiments using FEMNIST dataset and compare the result against the random FL algorithm. The experimental results show that the proposed algorithm outperforms the baseline algorithm in terms of accuracy, communication cost, and security.
Intelligent Building Control Systems for Thermal Comfort and Energy-Efficiency: A Systematic Review of Artificial Intelligence-Assisted Techniques
Apr 06, 2021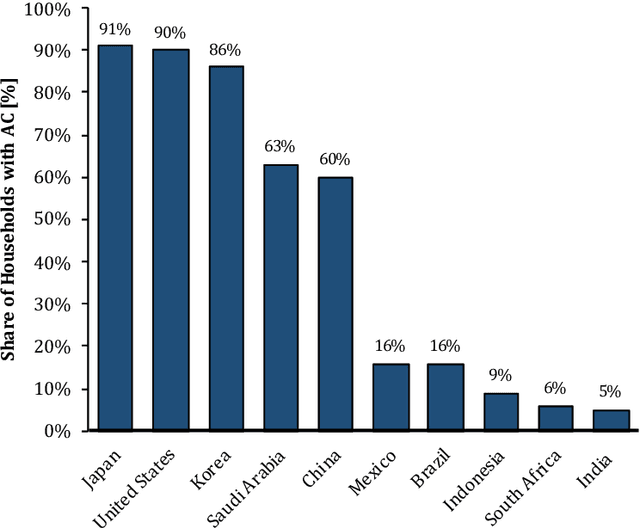

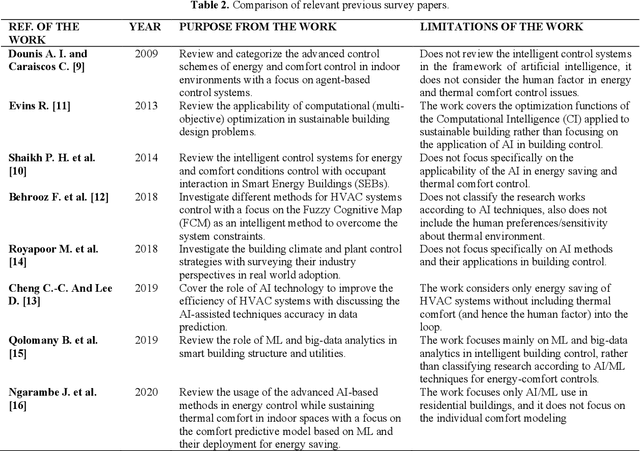
Building operations represent a significant percentage of the total primary energy consumed in most countries due to the proliferation of Heating, Ventilation and Air-Conditioning (HVAC) installations in response to the growing demand for improved thermal comfort. Reducing the associated energy consumption while maintaining comfortable conditions in buildings are conflicting objectives and represent a typical optimization problem that requires intelligent system design. Over the last decade, different methodologies based on the Artificial Intelligence (AI) techniques have been deployed to find the sweet spot between energy use in HVAC systems and suitable indoor comfort levels to the occupants. This paper performs a comprehensive and an in-depth systematic review of AI-based techniques used for building control systems by assessing the outputs of these techniques, and their implementations in the reviewed works, as well as investigating their abilities to improve the energy-efficiency, while maintaining thermal comfort conditions. This enables a holistic view of (1) the complexities of delivering thermal comfort to users inside buildings in an energy-efficient way, and (2) the associated bibliographic material to assist researchers and experts in the field in tackling such a challenge. Among the 20 AI tools developed for both energy consumption and comfort control, functions such as identification and recognition patterns, optimization, predictive control. Based on the findings of this work, the application of AI technology in building control is a promising area of research and still an ongoing, i.e., the performance of AI-based control is not yet completely satisfactory. This is mainly due in part to the fact that these algorithms usually need a large amount of high-quality real-world data, which is lacking in the building or, more precisely, the energy sector.
Sentiment Analysis of Users' Reviews on COVID-19 Contact Tracing Apps with a Benchmark Dataset
Mar 01, 2021
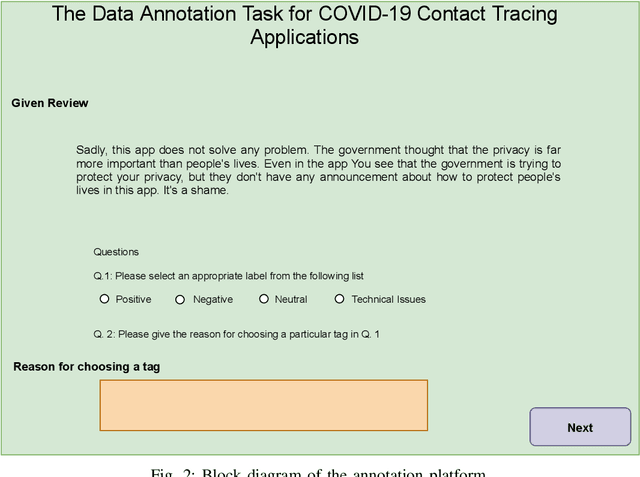
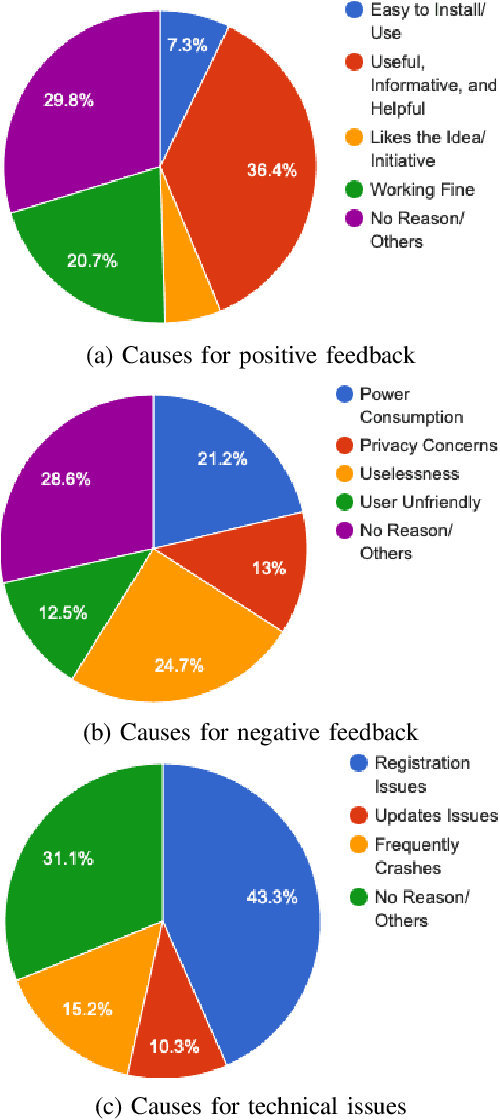
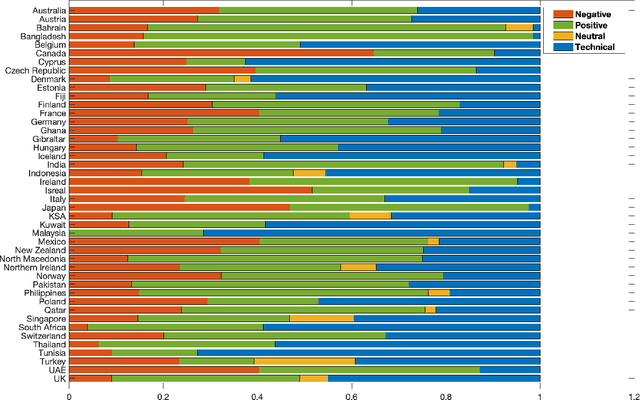
Contact tracing has been globally adopted in the fight to control the infection rate of COVID-19. Thanks to digital technologies, such as smartphones and wearable devices, contacts of COVID-19 patients can be easily traced and informed about their potential exposure to the virus. To this aim, several interesting mobile applications have been developed. However, there are ever-growing concerns over the working mechanism and performance of these applications. The literature already provides some interesting exploratory studies on the community's response to the applications by analyzing information from different sources, such as news and users' reviews of the applications. However, to the best of our knowledge, there is no existing solution that automatically analyzes users' reviews and extracts the evoked sentiments. In this work, we propose a pipeline starting from manual annotation via a crowd-sourcing study and concluding on the development and training of AI models for automatic sentiment analysis of users' reviews. In total, we employ eight different methods achieving up to an average F1-Scores 94.8% indicating the feasibility of automatic sentiment analysis of users' reviews on the COVID-19 contact tracing applications. We also highlight the key advantages, drawbacks, and users' concerns over the applications. Moreover, we also collect and annotate a large-scale dataset composed of 34,534 reviews manually annotated from the contract tracing applications of 46 distinct countries. The presented analysis and the dataset are expected to provide a baseline/benchmark for future research in the domain.