 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloods Relevancy and Identification of Location from Twitter Posts using NLP Techniques
Jan 01, 2023

This paper presents our solutions for the MediaEval 2022 task on DisasterMM. The task is composed of two subtasks, namely (i) Relevance Classification of Twitter Posts (RCTP), and (ii) Location Extraction from Twitter Texts (LETT). The RCTP subtask aims at differentiating flood-related and non-relevant social posts while LETT is a Named Entity Recognition (NER) task and aims at the extraction of location information from the text. For RCTP, we proposed four different solutions based on BERT, RoBERTa, Distil BERT, and ALBERT obtaining an F1-score of 0.7934, 0.7970, 0.7613, and 0.7924, respectively. For LETT, we used three models namely BERT, RoBERTa, and Distil BERTA obtaining an F1-score of 0.6256, 0.6744, and 0.6723, respectively.
Sentiment Analysis of Users' Reviews on COVID-19 Contact Tracing Apps with a Benchmark Dataset
Mar 01, 2021
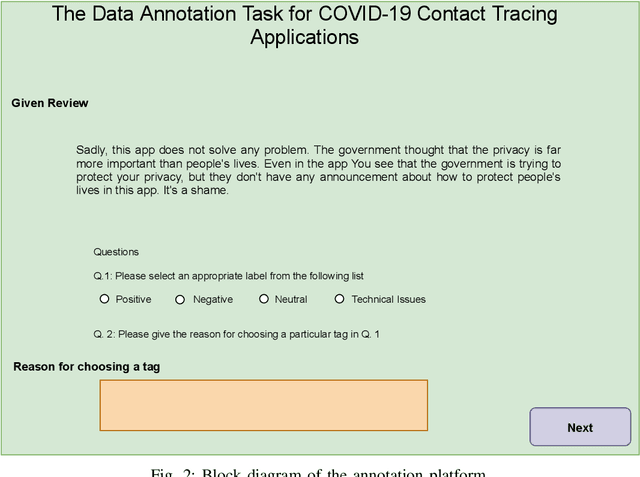
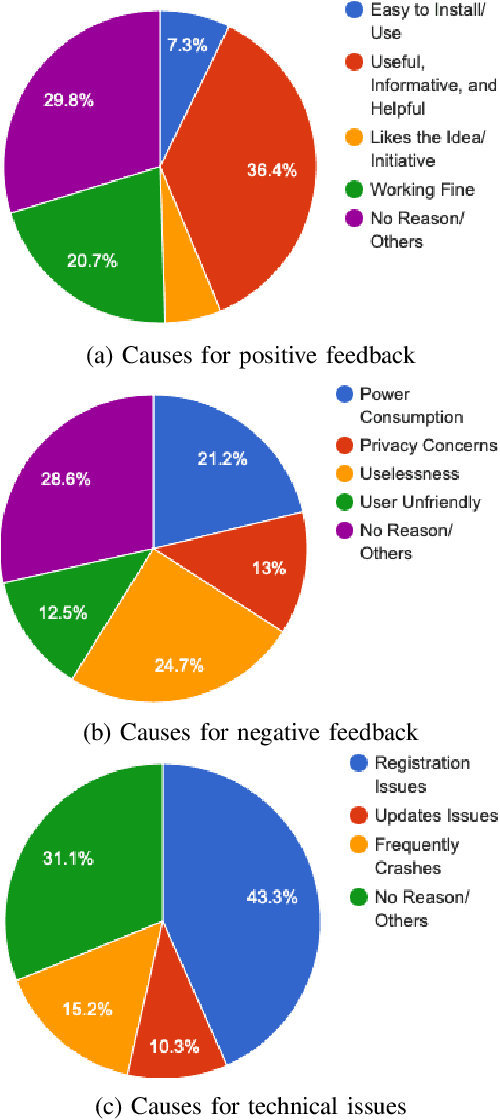
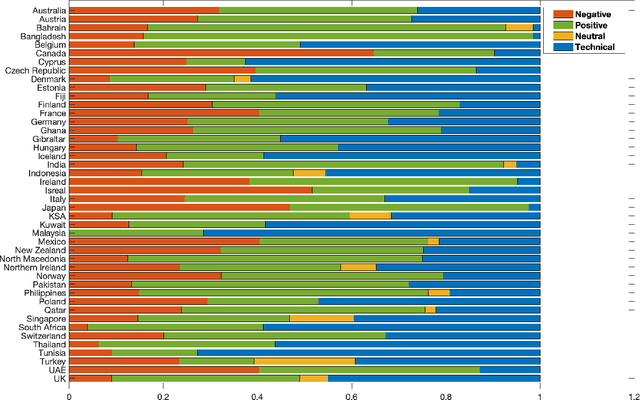
Contact tracing has been globally adopted in the fight to control the infection rate of COVID-19. Thanks to digital technologies, such as smartphones and wearable devices, contacts of COVID-19 patients can be easily traced and informed about their potential exposure to the virus. To this aim, several interesting mobile applications have been developed. However, there are ever-growing concerns over the working mechanism and performance of these applications. The literature already provides some interesting exploratory studies on the community's response to the applications by analyzing information from different sources, such as news and users' reviews of the applications. However, to the best of our knowledge, there is no existing solution that automatically analyzes users' reviews and extracts the evoked sentiments. In this work, we propose a pipeline starting from manual annotation via a crowd-sourcing study and concluding on the development and training of AI models for automatic sentiment analysis of users' reviews. In total, we employ eight different methods achieving up to an average F1-Scores 94.8% indicating the feasibility of automatic sentiment analysis of users' reviews on the COVID-19 contact tracing applications. We also highlight the key advantages, drawbacks, and users' concerns over the applications. Moreover, we also collect and annotate a large-scale dataset composed of 34,534 reviews manually annotated from the contract tracing applications of 46 distinct countries. The presented analysis and the dataset are expected to provide a baseline/benchmark for future research in the domain.