 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Media Informatics for Sustainable Cities and Societies: An Overview of the Applications, associated Challenges, and Potential Solutions
Dec 03, 2024In the modern world, our cities and societies face several technological and societal challenges, such as rapid urbanization, global warming & climate change, the digital divide, and social inequalities, increasing the need for more sustainable cities and societies. Addressing these challenges requires a multifaceted approach involving all the stakeholders, sustainable planning, efficient resource management, innovative solutions, and modern technologies. Like other modern technologies, social media informatics also plays its part in developing more sustainable and resilient cities and societies. Despite its limitations, social media informatics has proven very effective in various sustainable cities and society applications. In this paper, we review and analyze the role of social media informatics in sustainable cities and society by providing a detailed overview of its applications, associated challenges, and potential solutions. This work is expected to provide a baseline for future research in the domain.
Document Provenance and Authentication through Authorship Classification
Mar 02, 2023



Style analysis, which is relatively a less explored topic, enables several interesting applications. For instance, it allows authors to adjust their writing style to produce a more coherent document in collaboration. Similarly, style analysis can also be used for document provenance and authentication as a primary step. In this paper, we propose an ensemble-based text-processing framework for the classification of single and multi-authored documents, which is one of the key tasks in style analysis. The proposed framework incorporates several state-of-the-art text classification algorithms including classical Machine Learning (ML) algorithms, transformers, and deep learning algorithms both individually and in merit-based late fusion. For the merit-based late fusion, we employed several weight optimization and selection methods to assign merit-based weights to the individual text classification algorithms. We also analyze the impact of the characters on the task that are usually excluded in NLP applications during pre-processing by conducting experiments on both clean and un-clean data. The proposed framework is evaluated on a large-scale benchmark dataset, significantly improving performance over the existing solutions.
* 7 pages; 3 tables; 1 figure
Floods Relevancy and Identification of Location from Twitter Posts using NLP Techniques
Jan 01, 2023

This paper presents our solutions for the MediaEval 2022 task on DisasterMM. The task is composed of two subtasks, namely (i) Relevance Classification of Twitter Posts (RCTP), and (ii) Location Extraction from Twitter Texts (LETT). The RCTP subtask aims at differentiating flood-related and non-relevant social posts while LETT is a Named Entity Recognition (NER) task and aims at the extraction of location information from the text. For RCTP, we proposed four different solutions based on BERT, RoBERTa, Distil BERT, and ALBERT obtaining an F1-score of 0.7934, 0.7970, 0.7613, and 0.7924, respectively. For LETT, we used three models namely BERT, RoBERTa, and Distil BERTA obtaining an F1-score of 0.6256, 0.6744, and 0.6723, respectively.
An Explainable Regression Framework for Predicting Remaining Useful Life of Machines
Apr 30, 2022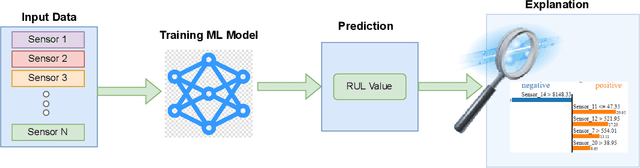
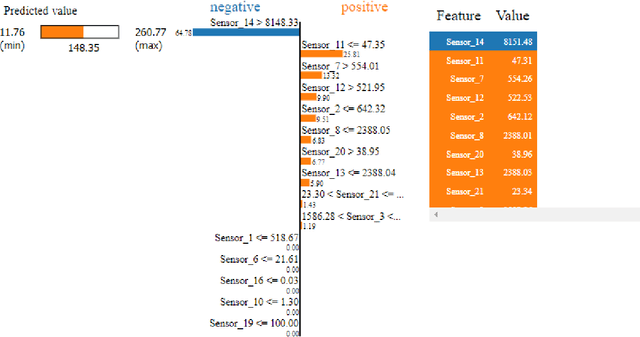

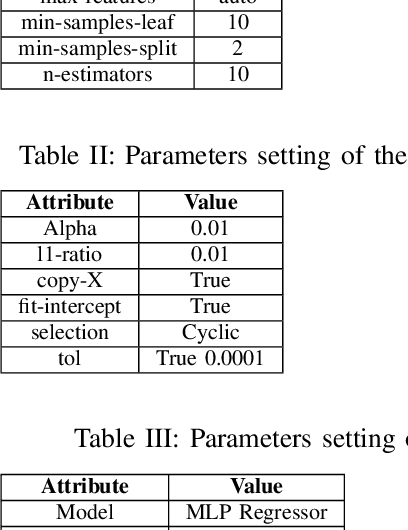
Prediction of a machine's Remaining Useful Life (RUL) is one of the key tasks in predictive maintenance. The task is treated as a regression problem where Machine Learning (ML) algorithms are used to predict the RUL of machine components. These ML algorithms are generally used as a black box with a total focus on the performance without identifying the potential causes behind the algorithms' decisions and their working mechanism. We believe, the performance (in terms of Mean Squared Error (MSE), etc.,) alone is not enough to build the trust of the stakeholders in ML prediction rather more insights on the causes behind the predictions are needed. To this aim, in this paper, we explore the potential of Explainable AI (XAI) techniques by proposing an explainable regression framework for the prediction of machines' RUL. We also evaluate several ML algorithms including classical and Neural Networks (NNs) based solutions for the task. For the explanations, we rely on two model agnostic XAI methods namely Local Interpretable Model-Agnostic Explanations (LIME) and Shapley Additive Explanations (SHAP). We believe, this work will provide a baseline for future research in the domain.
Merit-based Fusion of NLP Techniques for Instant Feedback on Water Quality from Twitter Text
Feb 09, 2022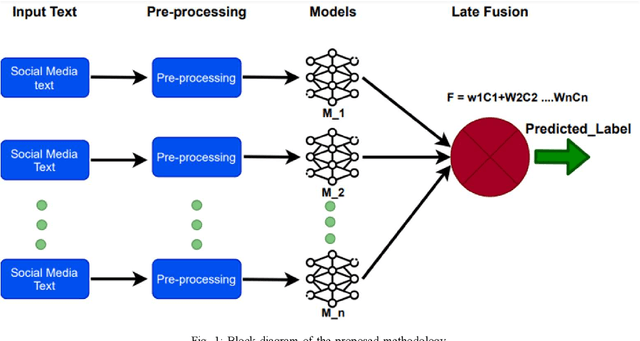

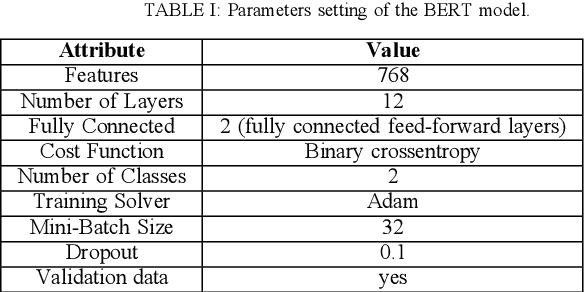
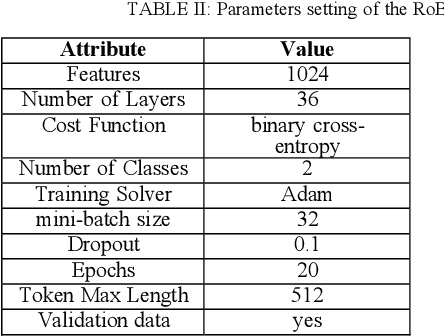
This paper focuses on an important environmental challenge; namely, water quality by analyzing the potential of social media as an immediate source of feedback. The main goal of the work is to automatically analyze and retrieve social media posts relevant to water quality with particular attention to posts describing different aspects of water quality, such as watercolor, smell, taste, and related illnesses. To this aim, we propose a novel framework incorporating different preprocessing, data augmentation, and classification techniques. In total, three different Neural Networks (NNs) architectures, namely (i) Bidirectional Encoder Representations from Transformers (BERT), (ii) Robustly Optimized BERT Pre-training Approach (XLM-RoBERTa), and (iii) custom Long short-term memory (LSTM) model, are employed in a merit-based fusion scheme. For merit-based weight assignment to the models, several optimization and search techniques are compared including a Particle Swarm Optimization (PSO), a Genetic Algorithm (GA), Brute Force (BF), Nelder-Mead, and Powell's optimization methods. We also provide an evaluation of the individual models where the highest F1-score of 0.81 is obtained with the BERT model. In merit-based fusion, overall better results are obtained with BF achieving an F1-score score of 0.852. We also provide comparison against existing methods, where a significant improvement for our proposed solutions is obtained. We believe such rigorous analysis of this relatively new topic will provide a baseline for future research.