 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCWD30: A Comprehensive and Holistic Dataset for Crop Weed Recognition in Precision Agriculture
May 17, 2023
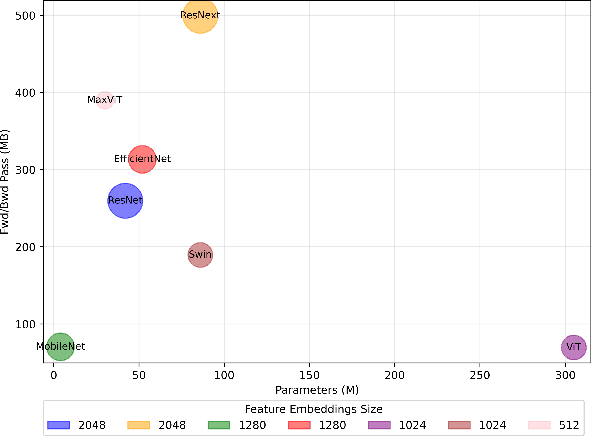
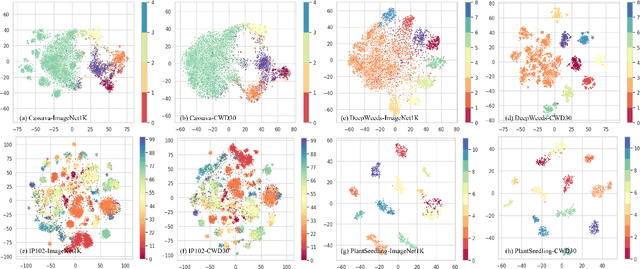

The growing demand for precision agriculture necessitates efficient and accurate crop-weed recognition and classification systems. Current datasets often lack the sample size, diversity, and hierarchical structure needed to develop robust deep learning models for discriminating crops and weeds in agricultural fields. Moreover, the similar external structure and phenomics of crops and weeds complicate recognition tasks. To address these issues, we present the CWD30 dataset, a large-scale, diverse, holistic, and hierarchical dataset tailored for crop-weed recognition tasks in precision agriculture. CWD30 comprises over 219,770 high-resolution images of 20 weed species and 10 crop species, encompassing various growth stages, multiple viewing angles, and environmental conditions. The images were collected from diverse agricultural fields across different geographic locations and seasons, ensuring a representative dataset. The dataset's hierarchical taxonomy enables fine-grained classification and facilitates the development of more accurate, robust, and generalizable deep learning models. We conduct extensive baseline experiments to validate the efficacy of the CWD30 dataset. Our experiments reveal that the dataset poses significant challenges due to intra-class variations, inter-class similarities, and data imbalance. Additionally, we demonstrate that minor training modifications like using CWD30 pretrained backbones can significantly enhance model performance and reduce convergence time, saving training resources on several downstream tasks. These challenges provide valuable insights and opportunities for future research in crop-weed recognition. We believe that the CWD30 dataset will serve as a benchmark for evaluating crop-weed recognition algorithms, promoting advancements in precision agriculture, and fostering collaboration among researchers in the field.
A Late Fusion Framework with Multiple Optimization Methods for Media Interestingness
Jul 11, 2022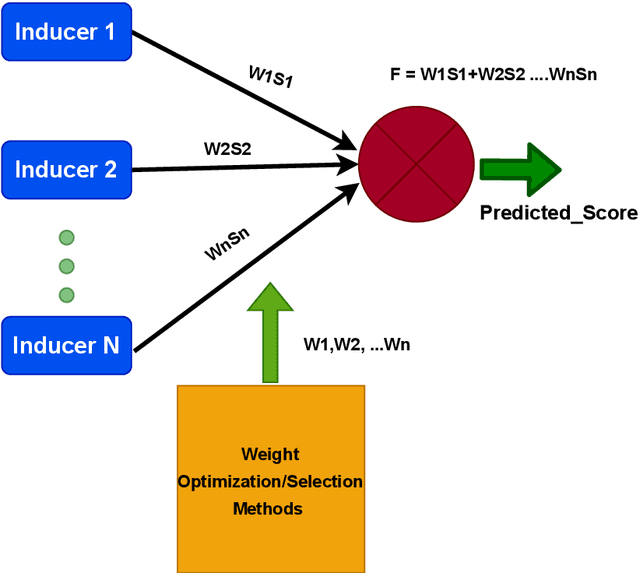
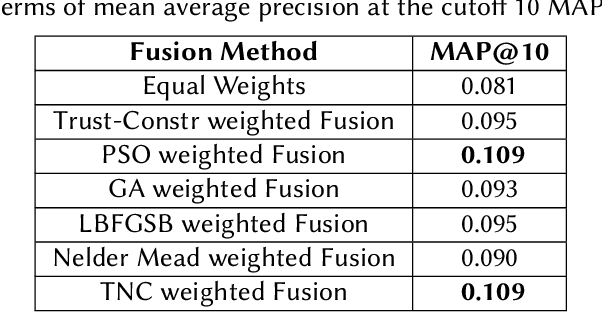
The recent advancement in Multimedia Analytical, Computer Vision (CV), and Artificial Intelligence (AI) algorithms resulted in several interesting tools allowing an automatic analysis and retrieval of multimedia content of users' interests. However, retrieving the content of interest generally involves analysis and extraction of semantic features, such as emotions and interestingness-level. The extraction of such meaningful information is a complex task and generally, the performance of individual algorithms is very low. One way to enhance the performance of the individual algorithms is to combine the predictive capabilities of multiple algorithms using fusion schemes. This allows the individual algorithms to complement each other, leading to improved performance. This paper proposes several fusion methods for the media interestingness score prediction task introduced in CLEF Fusion 2022. The proposed methods include both a naive fusion scheme, where all the inducers are treated equally and a merit-based fusion scheme where multiple weight optimization methods are employed to assign weights to the individual inducers. In total, we used six optimization methods including a Particle Swarm Optimization (PSO), a Genetic Algorithm (GA), Nelder Mead, Trust Region Constrained (TRC), and Limited-memory Broyden Fletcher Goldfarb Shanno Algorithm (LBFGSA), and Truncated Newton Algorithm (TNA). Overall better results are obtained with PSO and TNA achieving 0.109 mean average precision at 10. The task is complex and generally, scores are low. We believe the presented analysis will provide a baseline for future research in the domain.
Merit-based Fusion of NLP Techniques for Instant Feedback on Water Quality from Twitter Text
Feb 09, 2022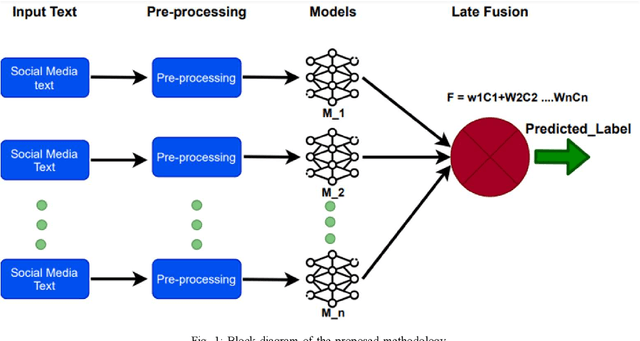

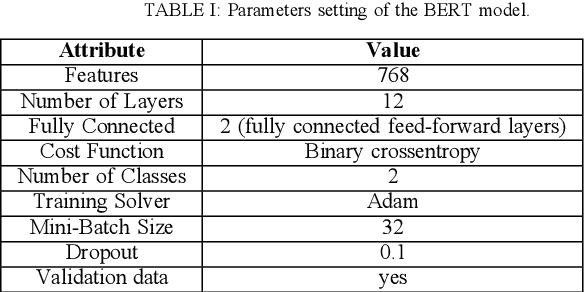
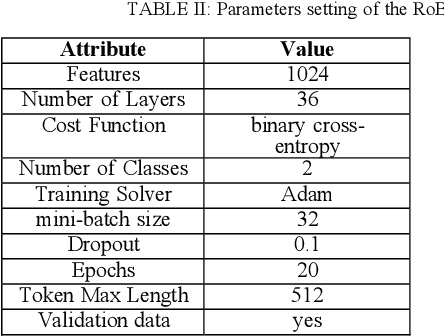
This paper focuses on an important environmental challenge; namely, water quality by analyzing the potential of social media as an immediate source of feedback. The main goal of the work is to automatically analyze and retrieve social media posts relevant to water quality with particular attention to posts describing different aspects of water quality, such as watercolor, smell, taste, and related illnesses. To this aim, we propose a novel framework incorporating different preprocessing, data augmentation, and classification techniques. In total, three different Neural Networks (NNs) architectures, namely (i) Bidirectional Encoder Representations from Transformers (BERT), (ii) Robustly Optimized BERT Pre-training Approach (XLM-RoBERTa), and (iii) custom Long short-term memory (LSTM) model, are employed in a merit-based fusion scheme. For merit-based weight assignment to the models, several optimization and search techniques are compared including a Particle Swarm Optimization (PSO), a Genetic Algorithm (GA), Brute Force (BF), Nelder-Mead, and Powell's optimization methods. We also provide an evaluation of the individual models where the highest F1-score of 0.81 is obtained with the BERT model. In merit-based fusion, overall better results are obtained with BF achieving an F1-score score of 0.852. We also provide comparison against existing methods, where a significant improvement for our proposed solutions is obtained. We believe such rigorous analysis of this relatively new topic will provide a baseline for future research.
NLP Techniques for Water Quality Analysis in Social Media Content
Nov 30, 2021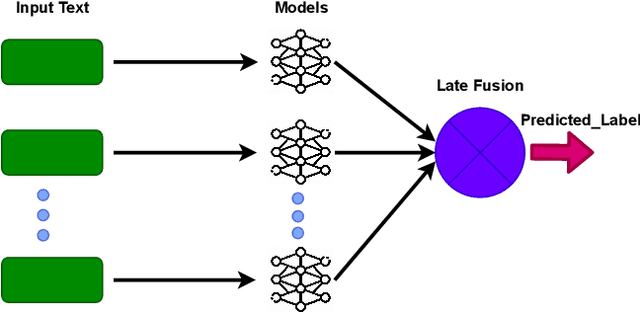
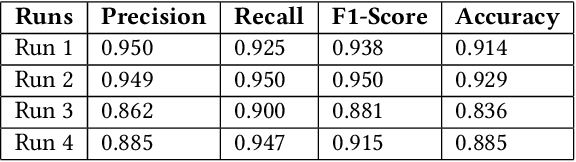
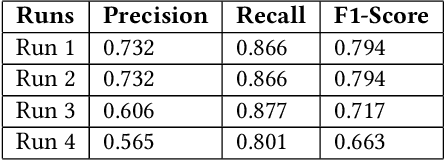
This paper presents our contributions to the MediaEval 2021 task namely "WaterMM: Water Quality in Social Multimedia". The task aims at analyzing social media posts relevant to water quality with particular focus on the aspects like watercolor, smell, taste, and related illnesses. To this aim, a multimodal dataset containing both textual and visual information along with meta-data is provided. Considering the quality and quantity of available content, we mainly focus on textual information by employing three different models individually and jointly in a late-fusion manner. These models include (i) Bidirectional Encoder Representations from Transformers (BERT), (ii) Robustly Optimized BERT Pre-training Approach (XLM-RoBERTa), and a (iii) custom Long short-term memory (LSTM) model obtaining an overall F1-score of 0.794, 0.717, 0.663 on the official test set, respectively. In the fusion scheme, all the models are treated equally and no significant improvement is observed in the performance over the best performing individual model.
Deep Models for Visual Sentiment Analysis of Disaster-related Multimedia Content
Nov 30, 2021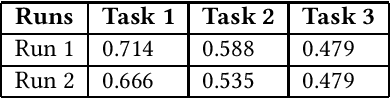
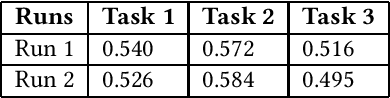
This paper presents a solutions for the MediaEval 2021 task namely "Visual Sentiment Analysis: A Natural Disaster Use-case". The task aims to extract and classify sentiments perceived by viewers and the emotional message conveyed by natural disaster-related images shared on social media. The task is composed of three sub-tasks including, one single label multi-class image classification task, and, two multi-label multi-class image classification tasks, with different sets of labels. In our proposed solutions, we rely mainly on two different state-of-the-art models namely, Inception-v3 and VggNet-19, pre-trained on ImageNet, which are fine-tuned for each of the three task using different strategies. Overall encouraging results are obtained on all the three tasks. On the single-label classification task (i.e. Task 1), we obtained the weighted average F1-scores of 0.540 and 0.526 for the Inception-v3 and VggNet-19 based solutions, respectively. On the multi-label classification i.e., Task 2 and Task 3, the weighted F1-score of our Inception-v3 based solutions was 0.572 and 0.516, respectively. Similarly, the weighted F1-score of our VggNet-19 based solution on Task 2 and Task 3 was 0.584 and 0.495, respectively.