 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP Techniques for Water Quality Analysis in Social Media Content
Paper and Code
Nov 30, 2021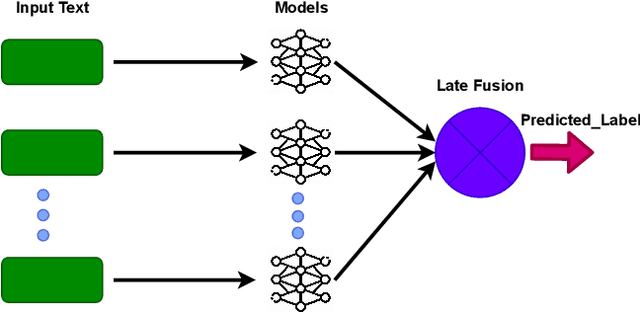
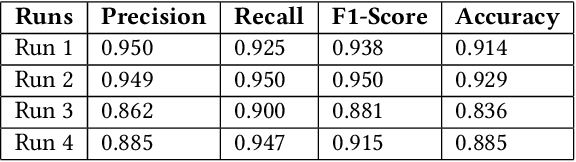
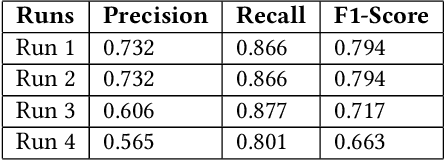
This paper presents our contributions to the MediaEval 2021 task namely "WaterMM: Water Quality in Social Multimedia". The task aims at analyzing social media posts relevant to water quality with particular focus on the aspects like watercolor, smell, taste, and related illnesses. To this aim, a multimodal dataset containing both textual and visual information along with meta-data is provided. Considering the quality and quantity of available content, we mainly focus on textual information by employing three different models individually and jointly in a late-fusion manner. These models include (i) Bidirectional Encoder Representations from Transformers (BERT), (ii) Robustly Optimized BERT Pre-training Approach (XLM-RoBERTa), and a (iii) custom Long short-term memory (LSTM) model obtaining an overall F1-score of 0.794, 0.717, 0.663 on the official test set, respectively. In the fusion scheme, all the models are treated equally and no significant improvement is observed in the performance over the best performing individual model.