 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Media Informatics for Sustainable Cities and Societies: An Overview of the Applications, associated Challenges, and Potential Solutions
Dec 03, 2024In the modern world, our cities and societies face several technological and societal challenges, such as rapid urbanization, global warming & climate change, the digital divide, and social inequalities, increasing the need for more sustainable cities and societies. Addressing these challenges requires a multifaceted approach involving all the stakeholders, sustainable planning, efficient resource management, innovative solutions, and modern technologies. Like other modern technologies, social media informatics also plays its part in developing more sustainable and resilient cities and societies. Despite its limitations, social media informatics has proven very effective in various sustainable cities and society applications. In this paper, we review and analyze the role of social media informatics in sustainable cities and society by providing a detailed overview of its applications, associated challenges, and potential solutions. This work is expected to provide a baseline for future research in the domain.
PSYDIAL: Personality-based Synthetic Dialogue Generation using Large Language Models
Apr 01, 2024We present a novel end-to-end personality-based synthetic dialogue data generation pipeline, specifically designed to elicit responses from large language models via prompting. We design the prompts to generate more human-like dialogues considering real-world scenarios when users engage with chatbots. We introduce PSYDIAL, the first Korean dialogue dataset focused on personality-based dialogues, curated using our proposed pipeline. Notably, we focus on the Extraversion dimension of the Big Five personality model in our research. Experimental results indicate that while pre-trained models and those fine-tuned with a chit-chat dataset struggle to generate responses reflecting personality, models trained with PSYDIAL show significant improvements. The versatility of our pipeline extends beyond dialogue tasks, offering potential for other non-dialogue related applications. This research opens doors for more nuanced, personality-driven conversational AI in Korean and potentially other languages. Our code is publicly available at https://github.com/jiSilverH/psydial.
Why Is It Hate Speech? Masked Rationale Prediction for Explainable Hate Speech Detection
Nov 01, 2022



In a hate speech detection model, we should consider two critical aspects in addition to detection performance-bias and explainability. Hate speech cannot be identified based solely on the presence of specific words: the model should be able to reason like humans and be explainable. To improve the performance concerning the two aspects, we propose Masked Rationale Prediction (MRP) as an intermediate task. MRP is a task to predict the masked human rationales-snippets of a sentence that are grounds for human judgment-by referring to surrounding tokens combined with their unmasked rationales. As the model learns its reasoning ability based on rationales by MRP, it performs hate speech detection robustly in terms of bias and explainability. The proposed method generally achieves state-of-the-art performance in various metrics, demonstrating its effectiveness for hate speech detection.
What is Wrong with One-Class Anomaly Detection?
Apr 20, 2021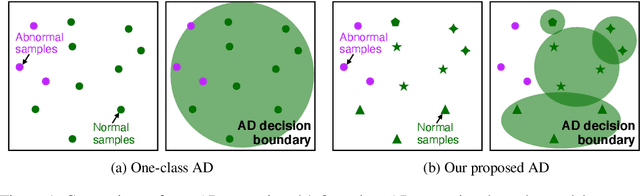
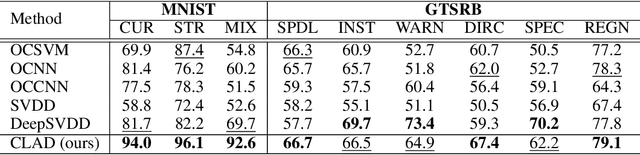
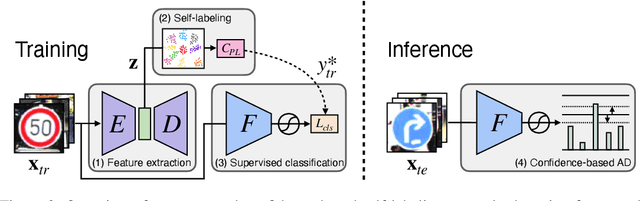
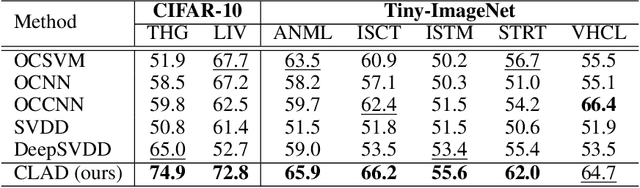
From a safety perspective, a machine learning method embedded in real-world applications is required to distinguish irregular situations. For this reason, there has been a growing interest in the anomaly detection (AD) task. Since we cannot observe abnormal samples for most of the cases, recent AD methods attempt to formulate it as a task of classifying whether the sample is normal or not. However, they potentially fail when the given normal samples are inherited from diverse semantic labels. To tackle this problem, we introduce a latent class-condition-based AD scenario. In addition, we propose a confidence-based self-labeling AD framework tailored to our proposed scenario. Since our method leverages the hidden class information, it successfully avoids generating the undesirable loose decision region that one-class methods suffer. Our proposed framework outperforms the recent one-class AD methods in the latent multi-class scenarios.
Restoring Spatially-Heterogeneous Distortions using Mixture of Experts Network
Sep 30, 2020
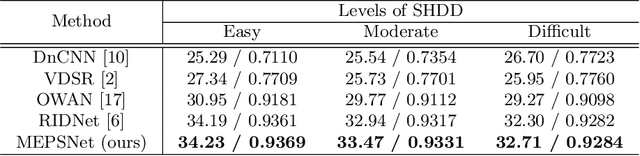
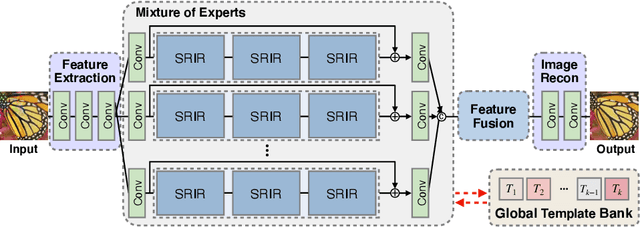

In recent years, deep learning-based methods have been successfully applied to the image distortion restoration tasks. However, scenarios that assume a single distortion only may not be suitable for many real-world applications. To deal with such cases, some studies have proposed sequentially combined distortions datasets. Viewing in a different point of combining, we introduce a spatially-heterogeneous distortion dataset in which multiple corruptions are applied to the different locations of each image. In addition, we also propose a mixture of experts network to effectively restore a multi-distortion image. Motivated by the multi-task learning, we design our network to have multiple paths that learn both common and distortion-specific representations. Our model is effective for restoring real-world distortions and we experimentally verify that our method outperforms other models designed to manage both single distortion and multiple distortions.
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
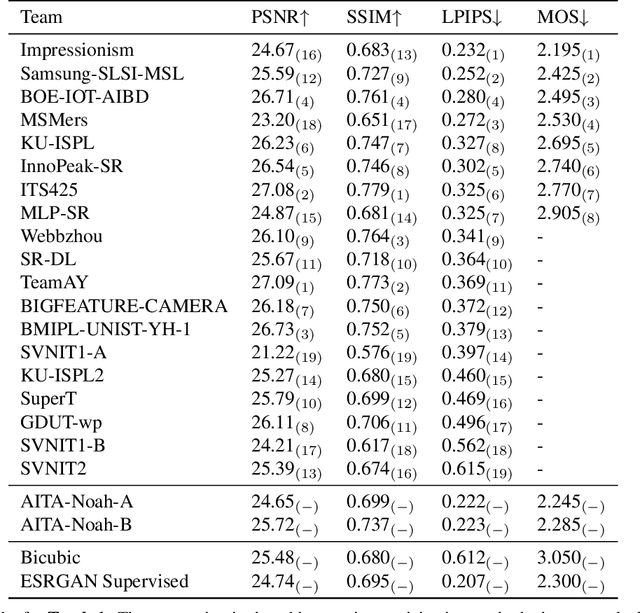
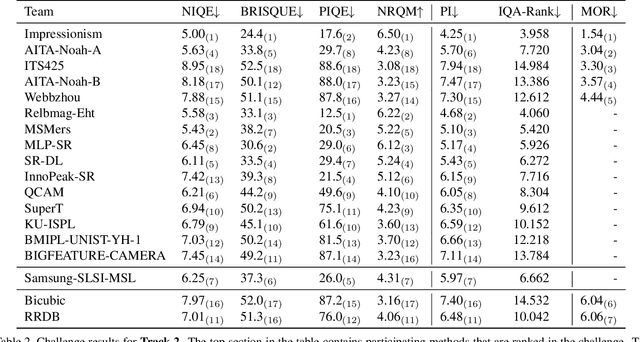

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
Rethinking Data Augmentation for Image Super-resolution: A Comprehensive Analysis and a New Strategy
Apr 23, 2020
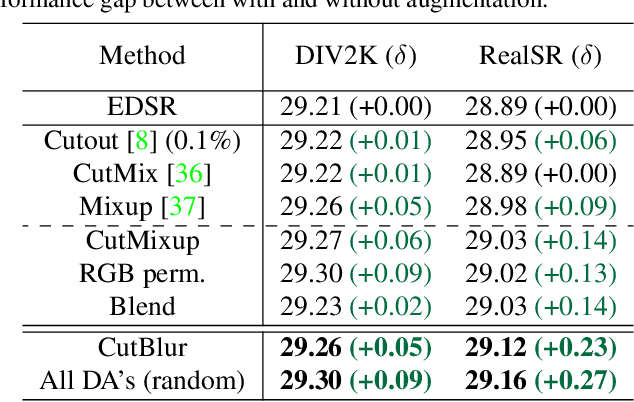

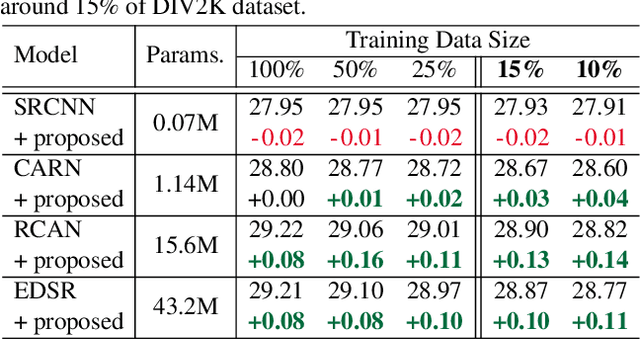
Data augmentation is an effective way to improve the performance of deep networks. Unfortunately, current methods are mostly developed for high-level vision tasks (e.g., classification) and few are studied for low-level vision tasks (e.g., image restoration). In this paper, we provide a comprehensive analysis of the existing augmentation methods applied to the super-resolution task. We find that the methods discarding or manipulating the pixels or features too much hamper the image restoration, where the spatial relationship is very important. Based on our analyses, we propose CutBlur that cuts a low-resolution patch and pastes it to the corresponding high-resolution image region and vice versa. The key intuition of CutBlur is to enable a model to learn not only "how" but also "where" to super-resolve an image. By doing so, the model can understand "how much", instead of blindly learning to apply super-resolution to every given pixel. Our method consistently and significantly improves the performance across various scenarios, especially when the model size is big and the data is collected under real-world environments. We also show that our method improves other low-level vision tasks, such as denoising and compression artifact removal.
SimUSR: A Simple but Strong Baseline for Unsupervised Image Super-resolution
Apr 23, 2020
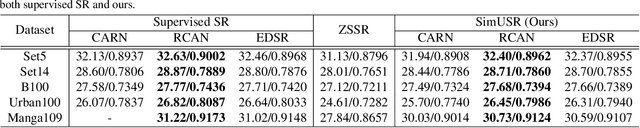
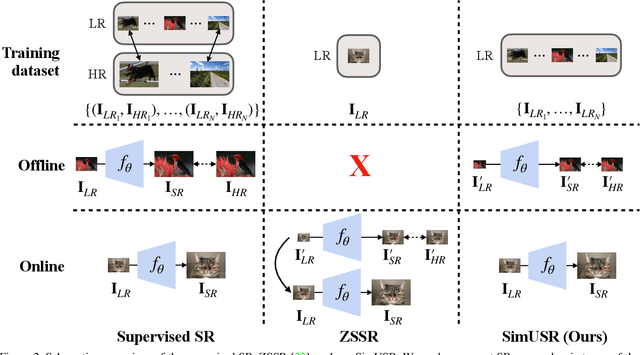
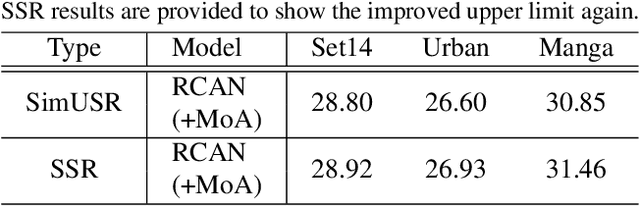
In this paper, we tackle a fully unsupervised super-resolution problem, i.e., neither paired images nor ground truth HR images. We assume that low resolution (LR) images are relatively easy to collect compared to high resolution (HR) images. By allowing multiple LR images, we build a set of pseudo pairs by denoising and downsampling LR images and cast the original unsupervised problem into a supervised learning problem but in one level lower. Though this line of study is easy to think of and thus should have been investigated prior to any complicated unsupervised methods, surprisingly, there are currently none. Even more, we show that this simple method outperforms the state-of-the-art unsupervised method with a dramatically shorter latency at runtime, and significantly reduces the gap to the HR supervised models. We submitted our method in NTIRE 2020 super-resolution challenge and won 1st in PSNR, 2nd in SSIM, and 13th in LPIPS. This simple method should be used as the baseline to beat in the future, especially when multiple LR images are allowed during the training phase. However, even in the zero-shot condition, we argue that this method can serve as a useful baseline to see the gap between supervised and unsupervised frameworks.
Photo-realistic Image Super-resolution with Fast and Lightweight Cascading Residual Network
Mar 06, 2019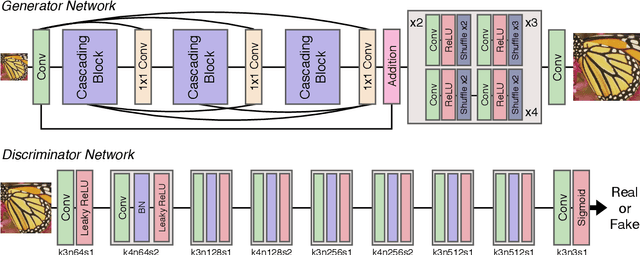
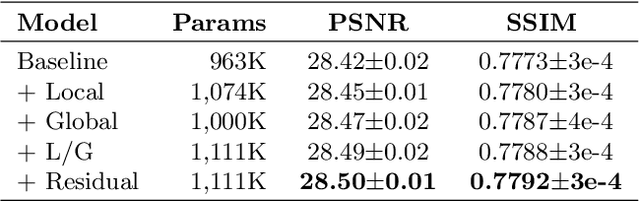
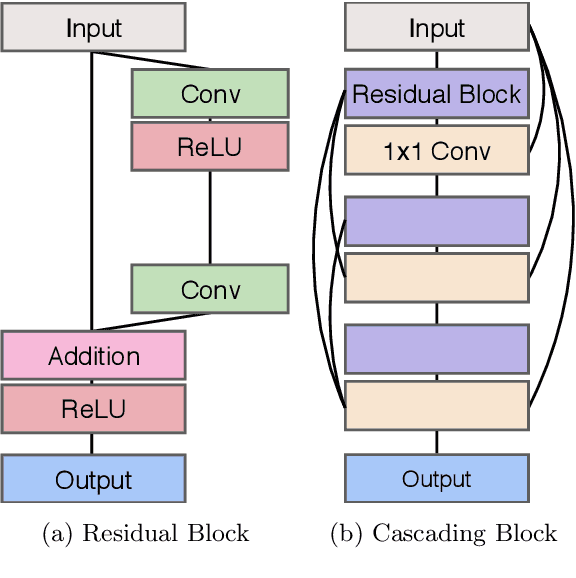

Recent progress in the deep learning-based models has improved single-image super-resolution significantly. However, despite their powerful performance, many models are difficult to apply to the real-world applications because of the heavy computational requirements. To facilitate the use of a deep learning model in such demands, we focus on keeping the model fast and lightweight while maintaining its accuracy. In detail, we design an architecture that implements a cascading mechanism on a residual network to boost the performance with limited resources via multi-level feature fusion. Moreover, we adopt group convolution and weight-tying for our proposed model in order to achieve extreme efficiency. In addition to the traditional super-resolution task, we apply our methods to the photo-realistic super-resolution field using the adversarial learning paradigm and a multi-scale discriminator approach. By doing so, we show that the performances of the proposed models surpass those of the recent methods, which have a complexity similar to ours, for both traditional pixel-based and perception-based tasks.
Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network
Oct 04, 2018
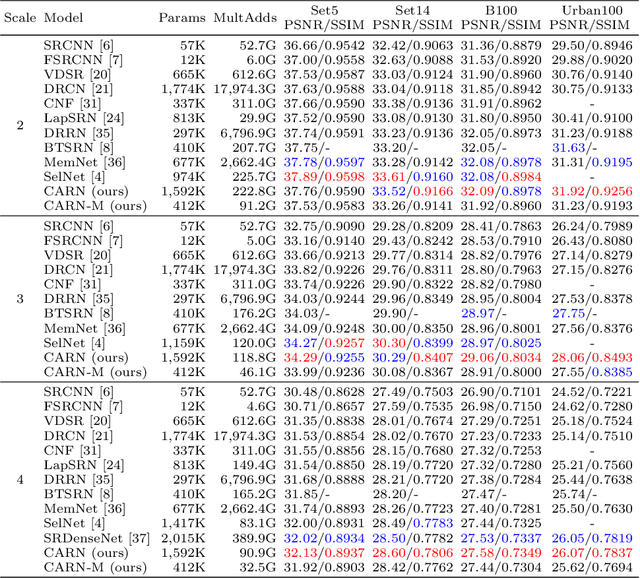
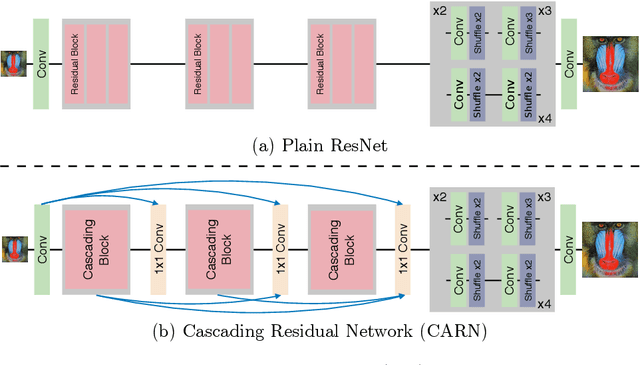

In recent years, deep learning methods have been successfully applied to single-image super-resolution tasks. Despite their great performances, deep learning methods cannot be easily applied to real-world applications due to the requirement of heavy computation. In this paper, we address this issue by proposing an accurate and lightweight deep network for image super-resolution. In detail, we design an architecture that implements a cascading mechanism upon a residual network. We also present variant models of the proposed cascading residual network to further improve efficiency. Our extensive experiments show that even with much fewer parameters and operations, our models achieve performance comparable to that of state-of-the-art methods.