 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Accurate Memorable Conversation Model using DPO based on sLLM
Jul 09, 2024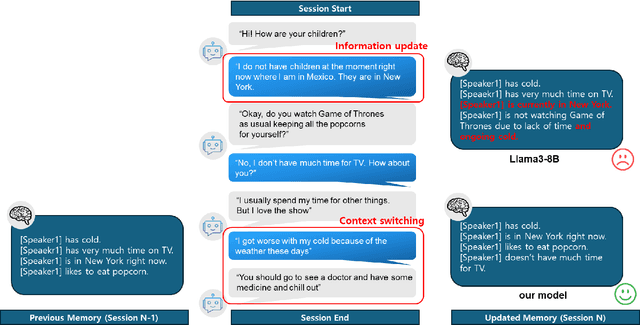

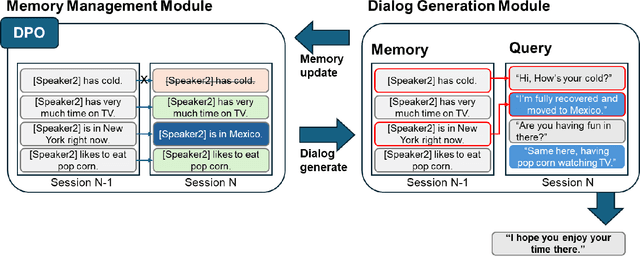
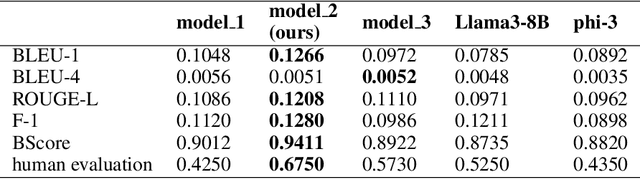
In multi-session dialog system, it is essential to continuously update the memory as the session progresses. Simply accumulating memory can make it difficult to focus on the content of the conversation for inference due to the limited input sentence size. Therefore, efficient and accurate conversation model that is capable of managing memory to reflect the conversation history continuously is necessary. This paper presents a conversation model that efficiently manages memory as sessions progress and incorporates this into the model to reflect the conversation history accurately with 3 methodologies: SFT, DPO and DPO with SFT model. Our model using DPO algorithm shows an improvement about 0.0591 of BERTScore in memory accuracy, and the rate of responses reflecting the memory increased as well. Also, response generation performance enhanced about 4.292 in fluency, 3.935 in coherence, and 2.896 in consistency. This paper describes a training method that yields better performance than models with more than twice the parameter size, even when the model size is smaller. Thus, our model demonstrates efficiency not only in terms of accuracy but also in resource utilization.
Enhancing Psychotherapy Counseling: A Data Augmentation Pipeline Leveraging Large Language Models for Counseling Conversations
Jun 13, 2024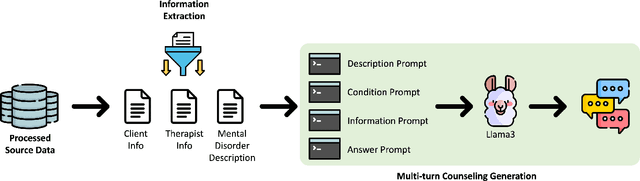



We introduce a pipeline that leverages Large Language Models (LLMs) to transform single-turn psychotherapy counseling sessions into multi-turn interactions. While AI-supported online counseling services for individuals with mental disorders exist, they are often constrained by the limited availability of multi-turn training datasets and frequently fail to fully utilize therapists' expertise. Our proposed pipeline effectively addresses these limitations. The pipeline comprises two main steps: 1) Information Extraction and 2) Multi-turn Counseling Generation. Each step is meticulously designed to extract and generate comprehensive multi-turn counseling conversations from the available datasets. Experimental results from both zero-shot and few-shot generation scenarios demonstrate that our approach significantly enhances the ability of LLMs to produce higher quality multi-turn dialogues in the context of mental health counseling. Our pipeline and dataset are publicly available https://github.com/jwkim-chat/A-Data-Augmentation-Pipeline-Leveraging-Large-Language-Models-for-Counseling-Conversations.
PSYDIAL: Personality-based Synthetic Dialogue Generation using Large Language Models
Apr 01, 2024We present a novel end-to-end personality-based synthetic dialogue data generation pipeline, specifically designed to elicit responses from large language models via prompting. We design the prompts to generate more human-like dialogues considering real-world scenarios when users engage with chatbots. We introduce PSYDIAL, the first Korean dialogue dataset focused on personality-based dialogues, curated using our proposed pipeline. Notably, we focus on the Extraversion dimension of the Big Five personality model in our research. Experimental results indicate that while pre-trained models and those fine-tuned with a chit-chat dataset struggle to generate responses reflecting personality, models trained with PSYDIAL show significant improvements. The versatility of our pipeline extends beyond dialogue tasks, offering potential for other non-dialogue related applications. This research opens doors for more nuanced, personality-driven conversational AI in Korean and potentially other languages. Our code is publicly available at https://github.com/jiSilverH/psydial.