 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylometry Analysis of Multi-authored Documents for Authorship and Author Style Change Detection
Jan 12, 2024



In recent years, the increasing use of Artificial Intelligence based text generation tools has posed new challenges in document provenance, authentication, and authorship detection. However, advancements in stylometry have provided opportunities for automatic authorship and author change detection in multi-authored documents using style analysis techniques. Style analysis can serve as a primary step toward document provenance and authentication through authorship detection. This paper investigates three key tasks of style analysis: (i) classification of single and multi-authored documents, (ii) single change detection, which involves identifying the point where the author switches, and (iii) multiple author-switching detection in multi-authored documents. We formulate all three tasks as classification problems and propose a merit-based fusion framework that integrates several state-of-the-art natural language processing (NLP) algorithms and weight optimization techniques. We also explore the potential of special characters, which are typically removed during pre-processing in NLP applications, on the performance of the proposed methods for these tasks by conducting extensive experiments on both cleaned and raw datasets. Experimental results demonstrate significant improvements over existing solutions for all three tasks on a benchmark dataset.
Sentiment Analysis of Users' Reviews on COVID-19 Contact Tracing Apps with a Benchmark Dataset
Mar 01, 2021
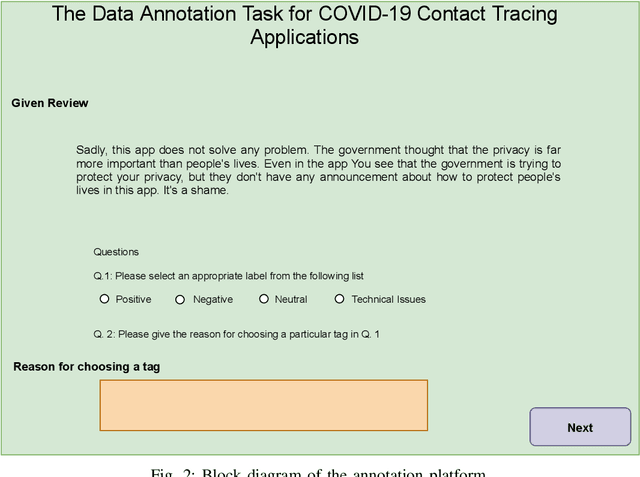
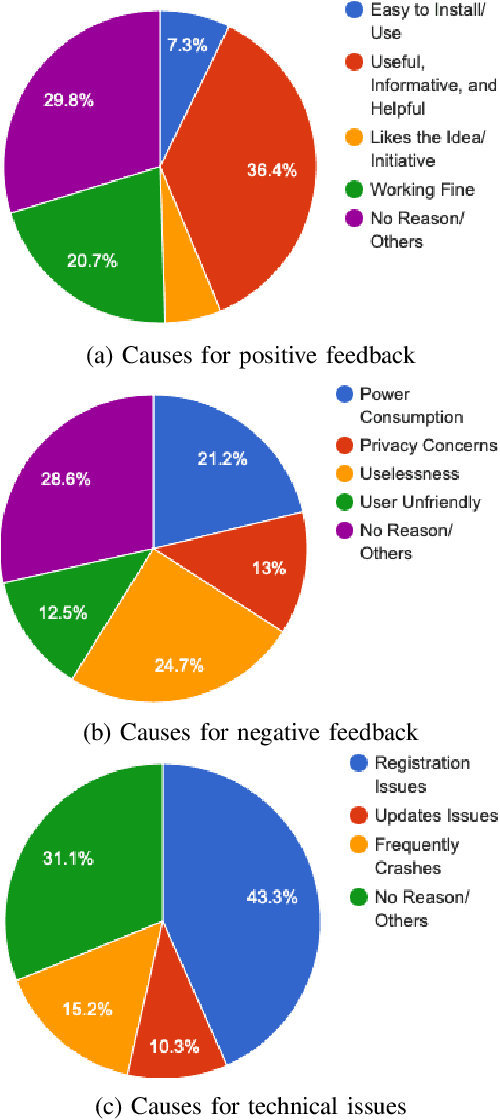
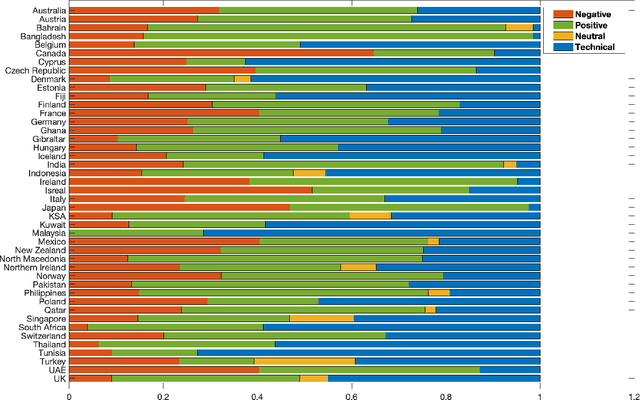
Contact tracing has been globally adopted in the fight to control the infection rate of COVID-19. Thanks to digital technologies, such as smartphones and wearable devices, contacts of COVID-19 patients can be easily traced and informed about their potential exposure to the virus. To this aim, several interesting mobile applications have been developed. However, there are ever-growing concerns over the working mechanism and performance of these applications. The literature already provides some interesting exploratory studies on the community's response to the applications by analyzing information from different sources, such as news and users' reviews of the applications. However, to the best of our knowledge, there is no existing solution that automatically analyzes users' reviews and extracts the evoked sentiments. In this work, we propose a pipeline starting from manual annotation via a crowd-sourcing study and concluding on the development and training of AI models for automatic sentiment analysis of users' reviews. In total, we employ eight different methods achieving up to an average F1-Scores 94.8% indicating the feasibility of automatic sentiment analysis of users' reviews on the COVID-19 contact tracing applications. We also highlight the key advantages, drawbacks, and users' concerns over the applications. Moreover, we also collect and annotate a large-scale dataset composed of 34,534 reviews manually annotated from the contract tracing applications of 46 distinct countries. The presented analysis and the dataset are expected to provide a baseline/benchmark for future research in the domain.
Optimal trees selection for classification via out-of-bag assessment and sub-bagging
Dec 30, 2020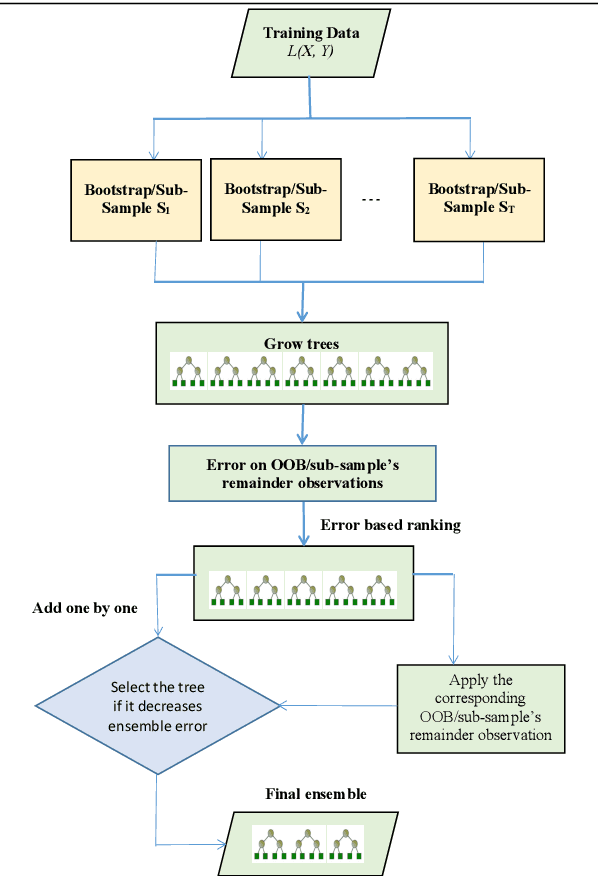
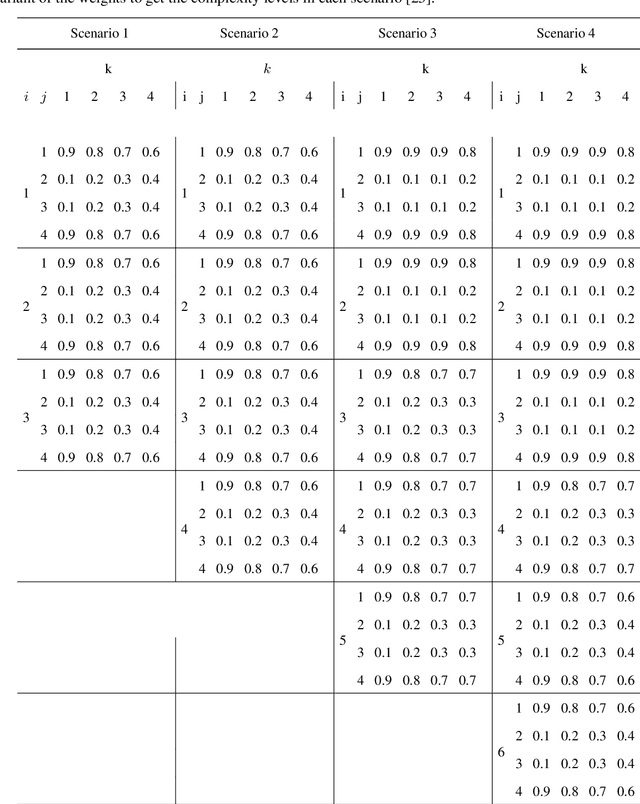
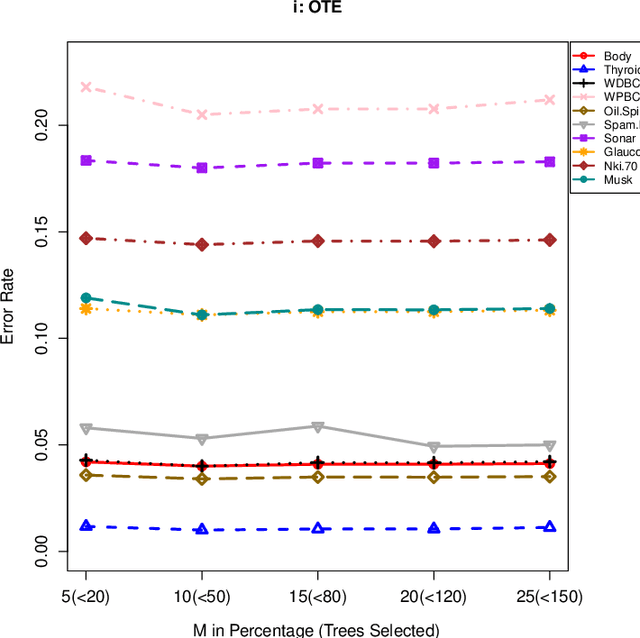
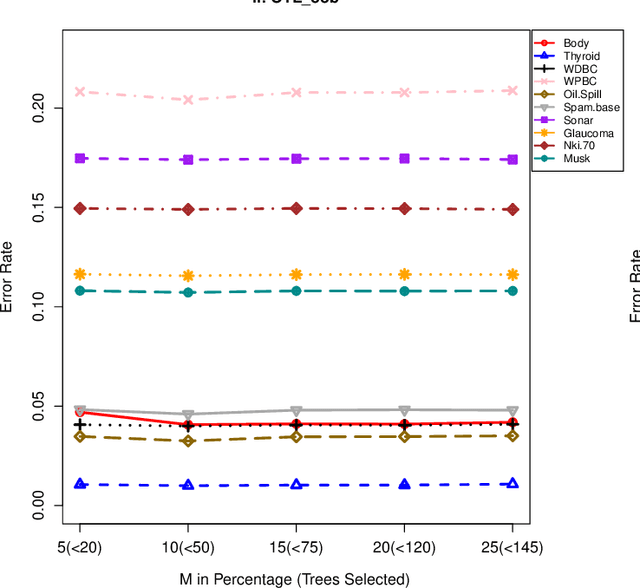
The effect of training data size on machine learning methods has been well investigated over the past two decades. The predictive performance of tree based machine learning methods, in general, improves with a decreasing rate as the size of training data increases. We investigate this in optimal trees ensemble (OTE) where the method fails to learn from some of the training observations due to internal validation. Modified tree selection methods are thus proposed for OTE to cater for the loss of training observations in internal validation. In the first method, corresponding out-of-bag (OOB) observations are used in both individual and collective performance assessment for each tree. Trees are ranked based on their individual performance on the OOB observations. A certain number of top ranked trees is selected and starting from the most accurate tree, subsequent trees are added one by one and their impact is recorded by using the OOB observations left out from the bootstrap sample taken for the tree being added. A tree is selected if it improves predictive accuracy of the ensemble. In the second approach, trees are grown on random subsets, taken without replacement-known as sub-bagging, of the training data instead of bootstrap samples (taken with replacement). The remaining observations from each sample are used in both individual and collective assessments for each corresponding tree similar to the first method. Analysis on 21 benchmark datasets and simulations studies show improved performance of the modified methods in comparison to OTE and other state-of-the-art methods.
Fake News Detection in Social Media using Graph Neural Networks and NLP Techniques: A COVID-19 Use-case
Nov 30, 2020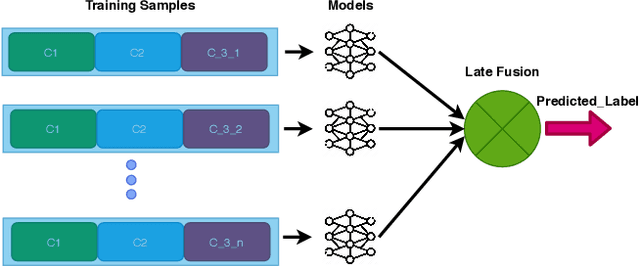
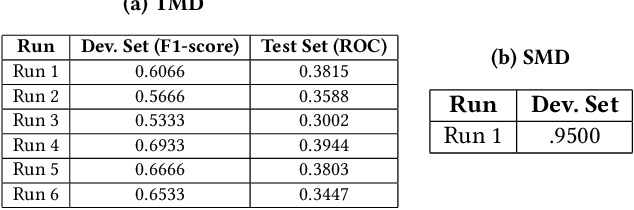
The paper presents our solutions for the MediaEval 2020 task namely FakeNews: Corona Virus and 5G Conspiracy Multimedia Twitter-Data-Based Analysis. The task aims to analyze tweets related to COVID-19 and 5G conspiracy theories to detect misinformation spreaders. The task is composed of two sub-tasks namely (i) text-based, and (ii) structure-based fake news detection. For the first task, we propose six different solutions relying on Bag of Words (BoW) and BERT embedding. Three of the methods aim at binary classification task by differentiating in 5G conspiracy and the rest of the COVID-19 related tweets while the rest of them treat the task as ternary classification problem. In the ternary classification task, our BoW and BERT based methods obtained an F1-score of .606% and .566% on the development set, respectively. On the binary classification, the BoW and BERT based solutions obtained an average F1-score of .666% and .693%, respectively. On the other hand, for structure-based fake news detection, we rely on Graph Neural Networks (GNNs) achieving an average ROC of .95% on the development set.
Flood Detection via Twitter Streams using Textual and Visual Features
Nov 30, 2020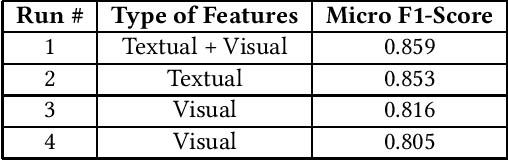
The paper presents our proposed solutions for the MediaEval 2020 Flood-Related Multimedia Task, which aims to analyze and detect flooding events in multimedia content shared over Twitter. In total, we proposed four different solutions including a multi-modal solution combining textual and visual information for the mandatory run, and three single modal image and text-based solutions as optional runs. In the multimodal method, we rely on a supervised multimodal bitransformer model that combines textual and visual features in an early fusion, achieving a micro F1-score of .859 on the development data set. For the text-based flood events detection, we use a transformer network (i.e., pretrained Italian BERT model) achieving an F1-score of .853. For image-based solutions, we employed multiple deep models, pre-trained on both, the ImageNet and places data sets, individually and combined in an early fusion achieving F1-scores of .816 and .805 on the development set, respectively.
Floods Detection in Twitter Text and Images
Nov 30, 2020
In this paper, we present our methods for the MediaEval 2020 Flood Related Multimedia task, which aims to analyze and combine textual and visual content from social media for the detection of real-world flooding events. The task mainly focuses on identifying floods related tweets relevant to a specific area. We propose several schemes to address the challenge. For text-based flood events detection, we use three different methods, relying on Bog of Words (BOW) and an Italian Version of Bert individually and in combination, achieving an F1-score of 0.77%, 0.68%, and 0.70% on the development set, respectively. For the visual analysis, we rely on features extracted via multiple state-of-the-art deep models pre-trained on ImageNet. The extracted features are then used to train multiple individual classifiers whose scores are then combined in a late fusion manner achieving an F1-score of 0.75%. For our mandatory multi-modal run, we combine the classification scores obtained with the best textual and visual schemes in a late fusion manner. Overall, better results are obtained with the multimodal scheme achieving an F1-score of 0.80% on the development set.