 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-aware item recommendations for multiply repeated user-item interactions
Apr 02, 2023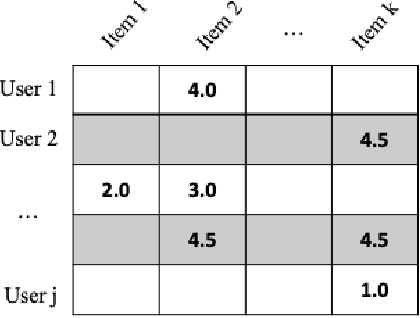



Recommender systems are one of the most successful applications of machine learning and data science. They are successful in a wide variety of application domains, including e-commerce, media streaming content, email marketing, and virtually every industry where personalisation facilitates better user experience or boosts sales and customer engagement. The main goal of these systems is to analyse past user behaviour to predict which items are of most interest to users. They are typically built with the use of matrix-completion techniques such as collaborative filtering or matrix factorisation. However, although these approaches have achieved tremendous success in numerous real-world applications, their effectiveness is still limited when users might interact multiple times with the same items, or when user preferences change over time. We were inspired by the approach that Natural Language Processing techniques take to compress, process, and analyse sequences of text. We designed a recommender system that induces the temporal dimension in the task of item recommendation and considers sequences of item interactions for each user in order to make recommendations. This method is empirically shown to give highly accurate predictions of user-items interactions for all users in a retail environment, without explicit feedback, besides increasing total sales by 5% and individual customer expenditure by over 50% in an A/B live test.
Modelling customer churn for the retail industry in a deep learning based sequential framework
Apr 02, 2023As retailers around the world increase efforts in developing targeted marketing campaigns for different audiences, predicting accurately which customers are most likely to churn ahead of time is crucial for marketing teams in order to increase business profits. This work presents a deep survival framework to predict which customers are at risk of stopping to purchase with retail companies in non-contractual settings. By leveraging the survival model parameters to be learnt by recurrent neural networks, we are able to obtain individual level survival models for purchasing behaviour based only on individual customer behaviour and avoid time-consuming feature engineering processes usually done when training machine learning models.
Automatic Detection of Industry Sectors in Legal Articles Using Machine Learning Approaches
Mar 08, 2023



The ability to automatically identify industry sector coverage in articles on legal developments, or any kind of news articles for that matter, can bring plentiful of benefits both to the readers and the content creators themselves. By having articles tagged based on industry coverage, readers from all around the world would be able to get to legal news that are specific to their region and professional industry. Simultaneously, writers would benefit from understanding which industries potentially lack coverage or which industries readers are currently mostly interested in and thus, they would focus their writing efforts towards more inclusive and relevant legal news coverage. In this paper, a Machine Learning-powered industry analysis approach which combined Natural Language Processing (NLP) with Statistical and Machine Learning (ML) techniques was investigated. A dataset consisting of over 1,700 annotated legal articles was created for the identification of six industry sectors. Text and legal based features were extracted from the text. Both traditional ML methods (e.g. gradient boosting machine algorithms, and decision-tree based algorithms) and deep neural network (e.g. transformer models) were applied for performance comparison of predictive models. The system achieved promising results with area under the receiver operating characteristic curve scores above 0.90 and F-scores above 0.81 with respect to the six industry sectors. The experimental results show that the suggested automated industry analysis which employs ML techniques allows the processing of large collections of text data in an easy, efficient, and scalable way. Traditional ML methods perform better than deep neural networks when only a small and domain-specific training data is available for the study.
Optimal trees selection for classification via out-of-bag assessment and sub-bagging
Dec 30, 2020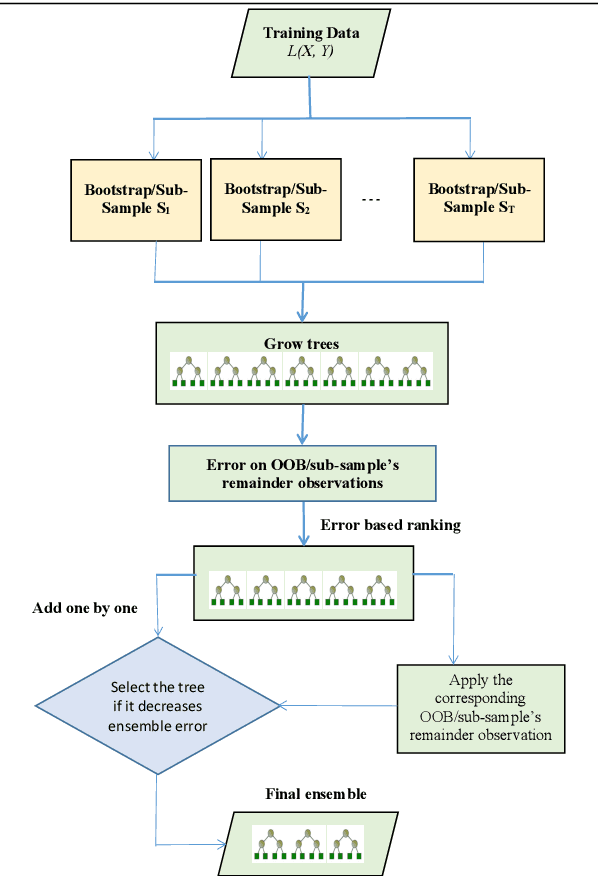
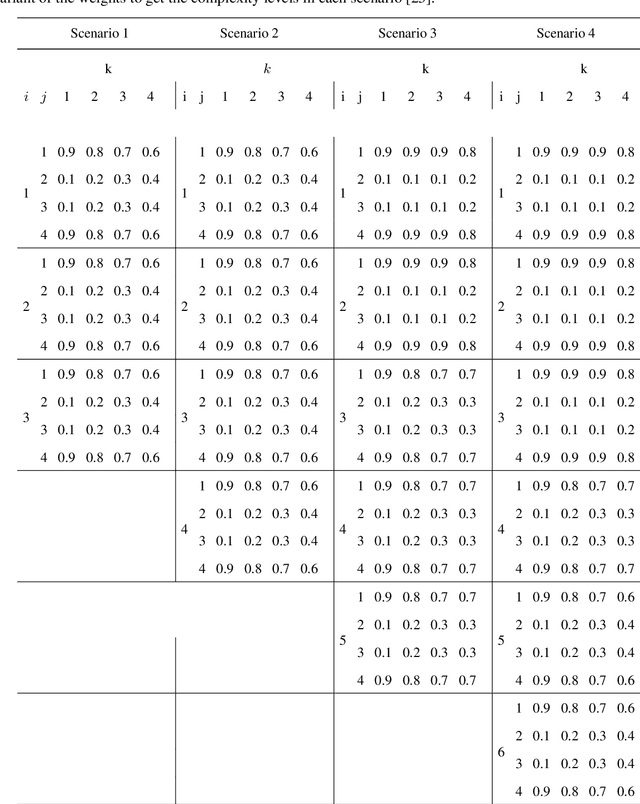
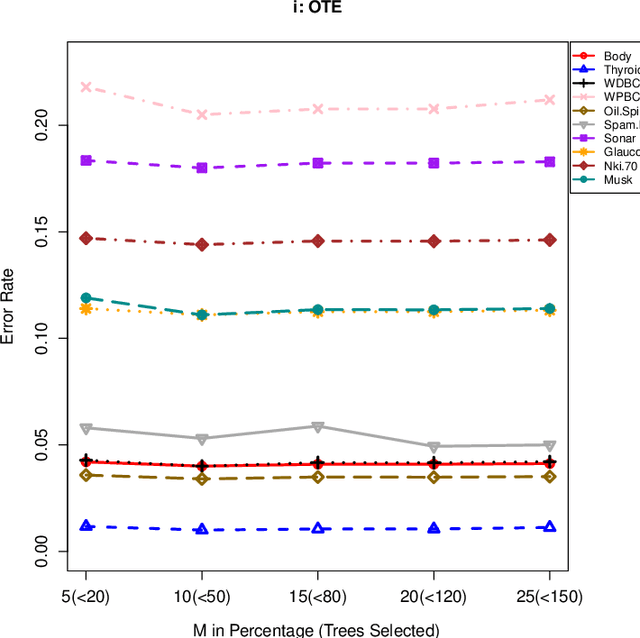
The effect of training data size on machine learning methods has been well investigated over the past two decades. The predictive performance of tree based machine learning methods, in general, improves with a decreasing rate as the size of training data increases. We investigate this in optimal trees ensemble (OTE) where the method fails to learn from some of the training observations due to internal validation. Modified tree selection methods are thus proposed for OTE to cater for the loss of training observations in internal validation. In the first method, corresponding out-of-bag (OOB) observations are used in both individual and collective performance assessment for each tree. Trees are ranked based on their individual performance on the OOB observations. A certain number of top ranked trees is selected and starting from the most accurate tree, subsequent trees are added one by one and their impact is recorded by using the OOB observations left out from the bootstrap sample taken for the tree being added. A tree is selected if it improves predictive accuracy of the ensemble. In the second approach, trees are grown on random subsets, taken without replacement-known as sub-bagging, of the training data instead of bootstrap samples (taken with replacement). The remaining observations from each sample are used in both individual and collective assessments for each corresponding tree similar to the first method. Analysis on 21 benchmark datasets and simulations studies show improved performance of the modified methods in comparison to OTE and other state-of-the-art methods.
Optimal survival trees ensemble
May 18, 2020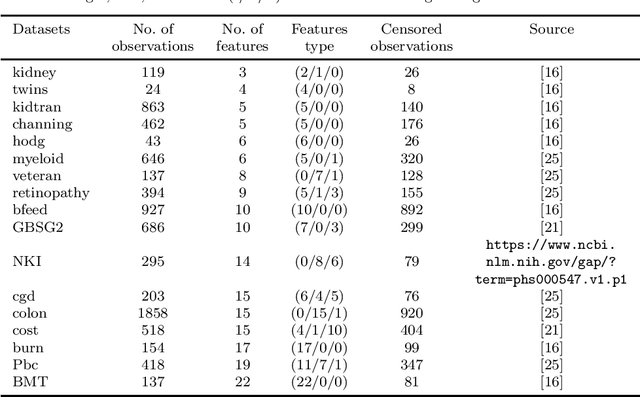
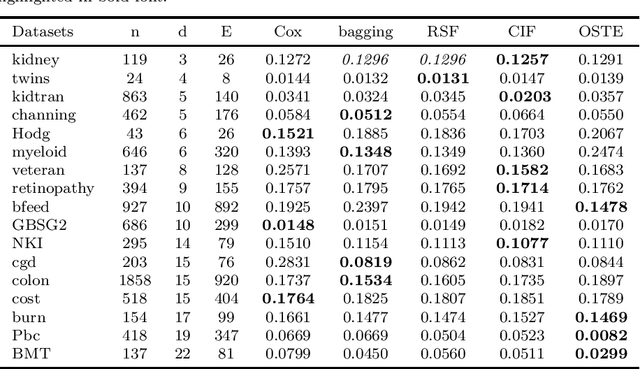
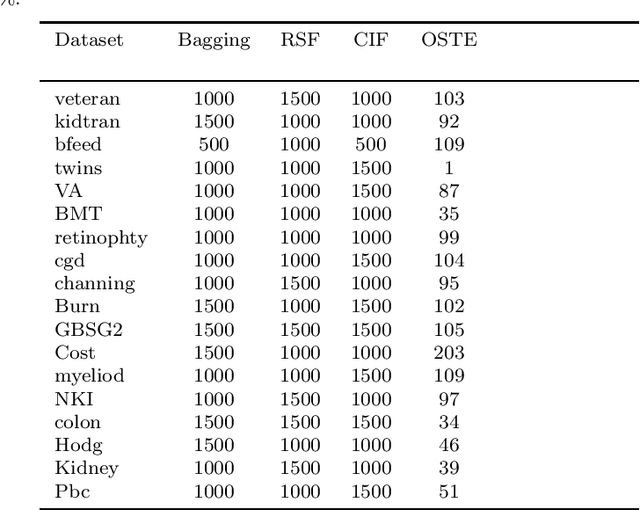
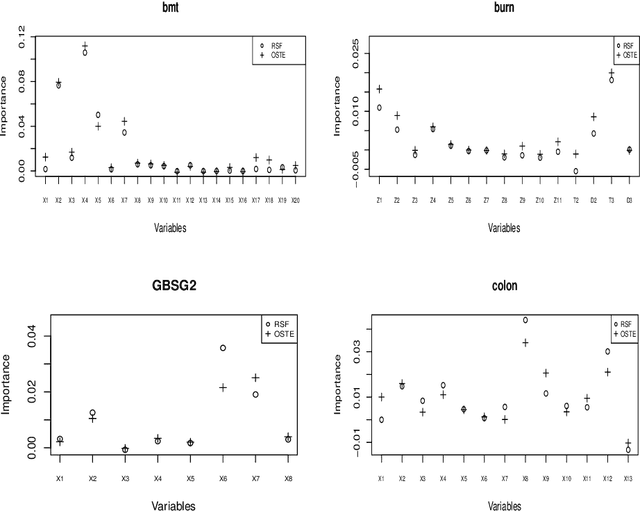
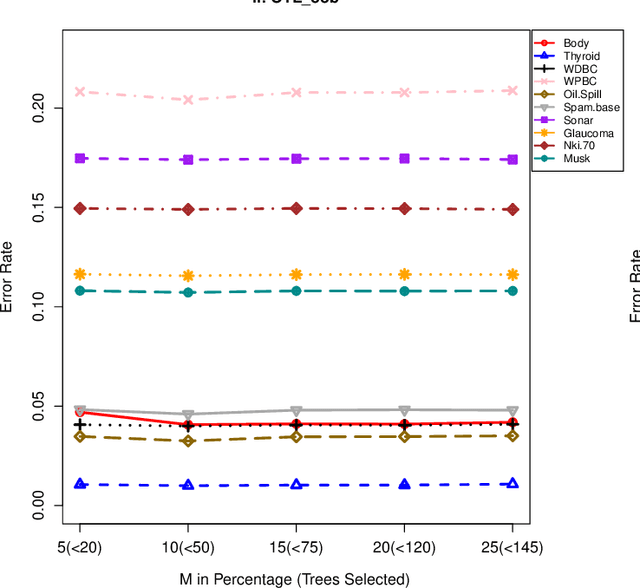
Recent studies have adopted an approach of selecting accurate and diverse trees based on individual or collective performance within an ensemble for classification and regression problems. This work follows in the wake of these investigations and considers the possibility of growing a forest of optimal survival trees. Initially, a large set of survival trees are grown using the method of random survival forest. The grown trees are then ranked from smallest to highest value of their prediction error using out-of-bag observations for each respective survival tree. The top ranked survival trees are then assessed for their collective performance as an ensemble. This ensemble is initiated with the survival tree which stands first in rank, then further trees are tested one by one by adding them to the ensemble in order of rank. A survival tree is selected for the resultant ensemble if the performance improves after an assessment using independent training data. This ensemble is called an optimal trees ensemble (OSTE). The proposed method is assessed using 17 benchmark datasets and the results are compared with those of random survival forest, conditional inference forest, bagging and a non tree based method, the Cox proportional hazard model. In addition to improve predictive performance, the proposed method reduces the number of survival trees in the ensemble as compared to the other tree based methods. The method is implemented in an R package called "OSTE".