 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal trees selection for classification via out-of-bag assessment and sub-bagging
Paper and Code
Dec 30, 2020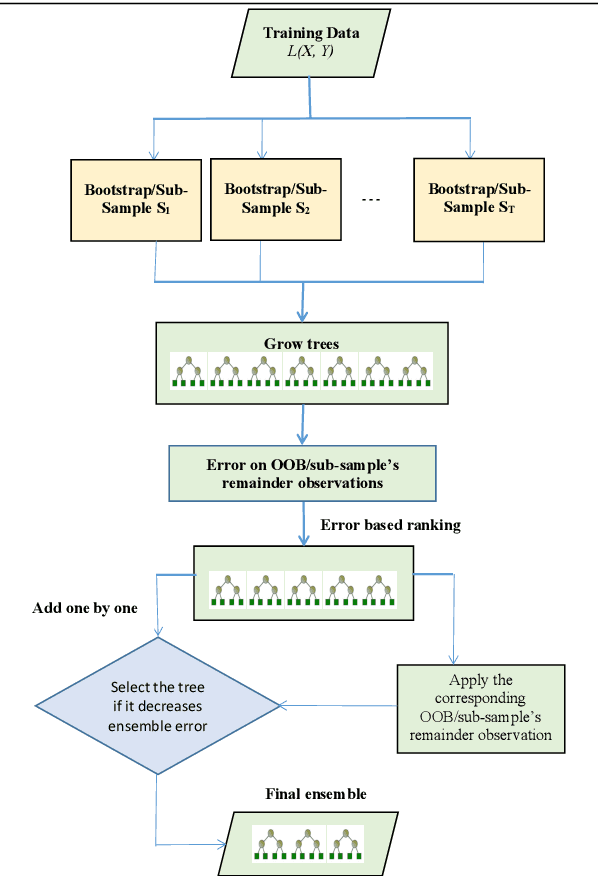
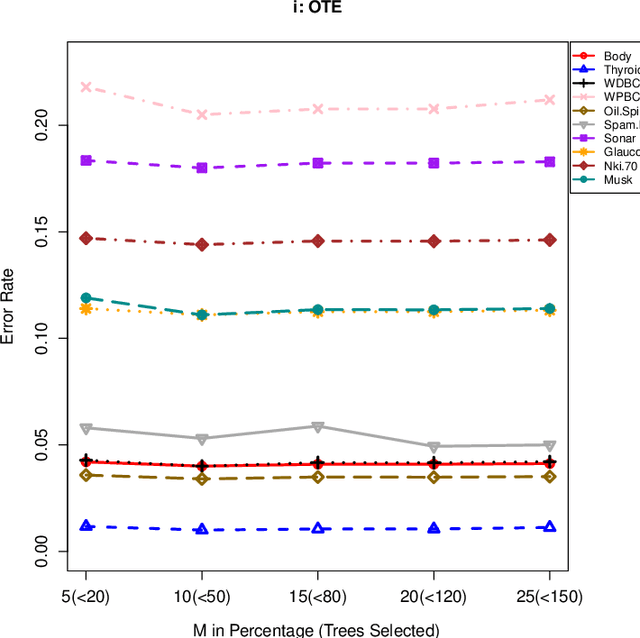
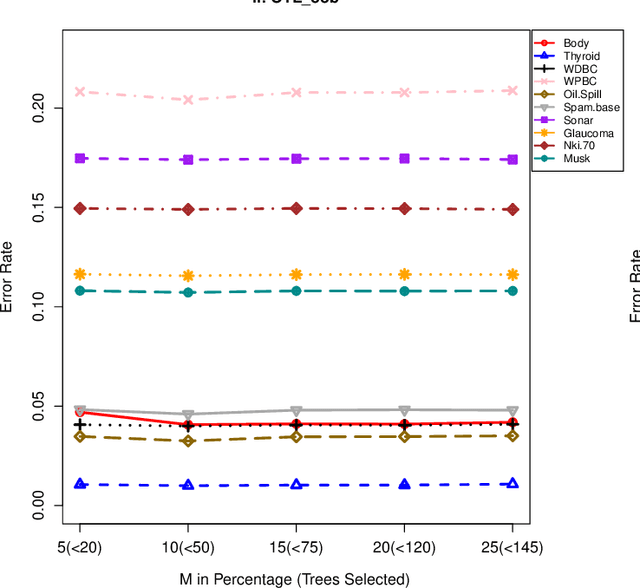
The effect of training data size on machine learning methods has been well investigated over the past two decades. The predictive performance of tree based machine learning methods, in general, improves with a decreasing rate as the size of training data increases. We investigate this in optimal trees ensemble (OTE) where the method fails to learn from some of the training observations due to internal validation. Modified tree selection methods are thus proposed for OTE to cater for the loss of training observations in internal validation. In the first method, corresponding out-of-bag (OOB) observations are used in both individual and collective performance assessment for each tree. Trees are ranked based on their individual performance on the OOB observations. A certain number of top ranked trees is selected and starting from the most accurate tree, subsequent trees are added one by one and their impact is recorded by using the OOB observations left out from the bootstrap sample taken for the tree being added. A tree is selected if it improves predictive accuracy of the ensemble. In the second approach, trees are grown on random subsets, taken without replacement-known as sub-bagging, of the training data instead of bootstrap samples (taken with replacement). The remaining observations from each sample are used in both individual and collective assessments for each corresponding tree similar to the first method. Analysis on 21 benchmark datasets and simulations studies show improved performance of the modified methods in comparison to OTE and other state-of-the-art methods.