 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuardEval: A Multi-Perspective Benchmark for Evaluating Safety, Fairness, and Robustness in LLM Moderators
Dec 22, 2025As large language models (LLMs) become deeply embedded in daily life, the urgent need for safer moderation systems, distinguishing between naive from harmful requests while upholding appropriate censorship boundaries, has never been greater. While existing LLMs can detect harmful or unsafe content, they often struggle with nuanced cases such as implicit offensiveness, subtle gender and racial biases, and jailbreak prompts, due to the subjective and context-dependent nature of these issues. Furthermore, their heavy reliance on training data can reinforce societal biases, resulting in inconsistent and ethically problematic outputs. To address these challenges, we introduce GuardEval, a unified multi-perspective benchmark dataset designed for both training and evaluation, containing 106 fine-grained categories spanning human emotions, offensive and hateful language, gender and racial bias, and broader safety concerns. We also present GemmaGuard (GGuard), a QLoRA fine-tuned version of Gemma3-12B trained on GuardEval, to assess content moderation with fine-grained labels. Our evaluation shows that GGuard achieves a macro F1 score of 0.832, substantially outperforming leading moderation models, including OpenAI Moderator (0.64) and Llama Guard (0.61). We show that multi-perspective, human-centered safety benchmarks are critical for reducing biased and inconsistent moderation decisions. GuardEval and GGuard together demonstrate that diverse, representative data materially improve safety, fairness, and robustness on complex, borderline cases.
Adversarial Machine Learning for Social Good: Reframing the Adversary as an Ally
Oct 05, 2023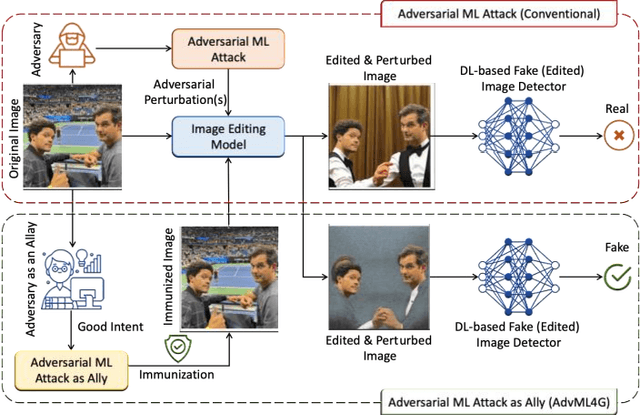
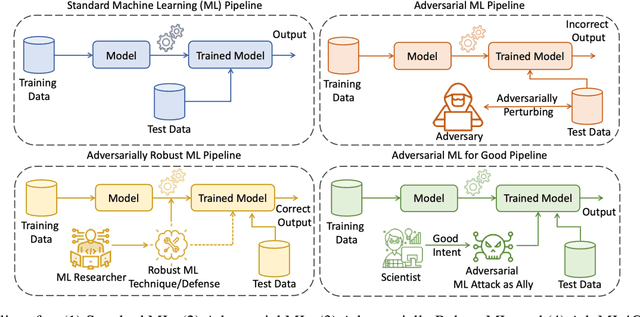
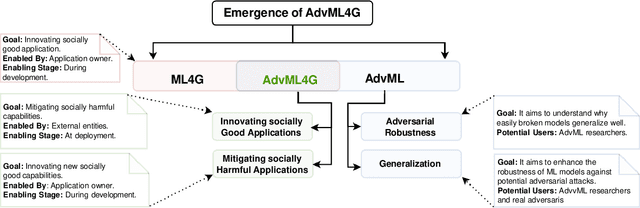
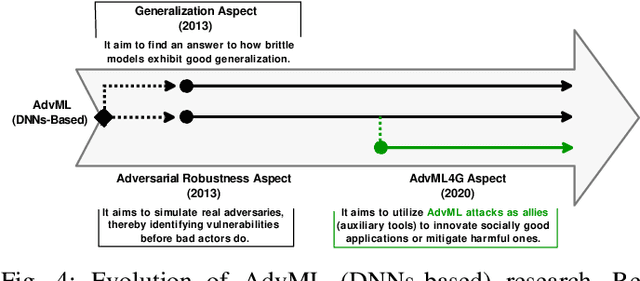
Deep Neural Networks (DNNs) have been the driving force behind many of the recent advances in machine learning. However, research has shown that DNNs are vulnerable to adversarial examples -- input samples that have been perturbed to force DNN-based models to make errors. As a result, Adversarial Machine Learning (AdvML) has gained a lot of attention, and researchers have investigated these vulnerabilities in various settings and modalities. In addition, DNNs have also been found to incorporate embedded bias and often produce unexplainable predictions, which can result in anti-social AI applications. The emergence of new AI technologies that leverage Large Language Models (LLMs), such as ChatGPT and GPT-4, increases the risk of producing anti-social applications at scale. AdvML for Social Good (AdvML4G) is an emerging field that repurposes the AdvML bug to invent pro-social applications. Regulators, practitioners, and researchers should collaborate to encourage the development of pro-social applications and hinder the development of anti-social ones. In this work, we provide the first comprehensive review of the emerging field of AdvML4G. This paper encompasses a taxonomy that highlights the emergence of AdvML4G, a discussion of the differences and similarities between AdvML4G and AdvML, a taxonomy covering social good-related concepts and aspects, an exploration of the motivations behind the emergence of AdvML4G at the intersection of ML4G and AdvML, and an extensive summary of the works that utilize AdvML4G as an auxiliary tool for innovating pro-social applications. Finally, we elaborate upon various challenges and open research issues that require significant attention from the research community.
Continual Conscious Active Fine-Tuning to Robustify Online Machine Learning Models Against Data Distribution Shifts
Nov 02, 2022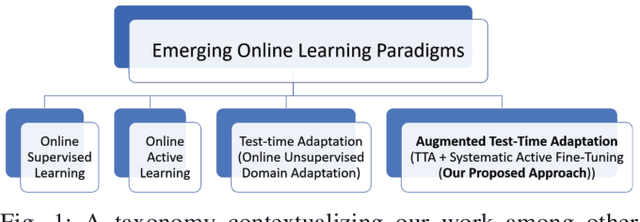
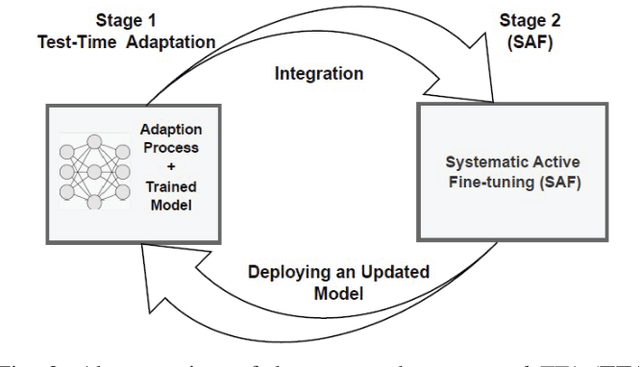
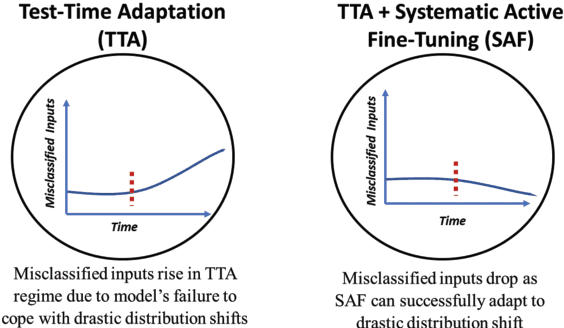
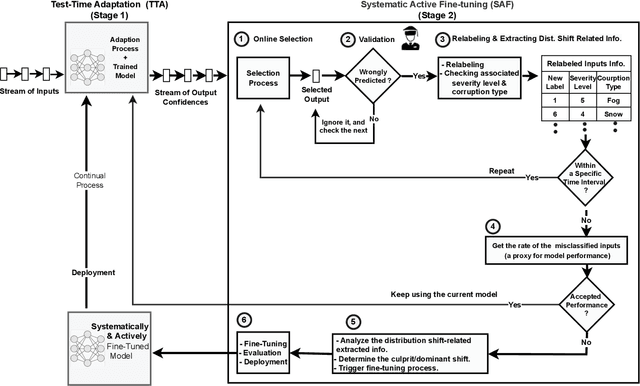
Unlike their offline traditional counterpart, online machine learning models are capable of handling data distribution shifts while serving at the test time. However, they have limitations in addressing this phenomenon. They are either expensive or unreliable. We propose augmenting an online learning approach called test-time adaptation with a continual conscious active fine-tuning layer to develop an enhanced variation that can handle drastic data distribution shifts reliably and cost-effectively. The proposed augmentation incorporates the following aspects: a continual aspect to confront the ever-ending data distribution shifts, a conscious aspect to imply that fine-tuning is a distribution-shift-aware process that occurs at the appropriate time to address the recently detected data distribution shifts, and an active aspect to indicate employing human-machine collaboration for the relabeling to be cost-effective and practical for diverse applications. Our empirical results show that the enhanced test-time adaptation variation outperforms the traditional variation by a factor of two.