 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Periodicity-based Parallel Time Series Prediction Algorithm in Cloud Computing Environments
Oct 17, 2018



In the era of big data, practical applications in various domains continually generate large-scale time-series data. Among them, some data show significant or potential periodicity characteristics, such as meteorological and financial data. It is critical to efficiently identify the potential periodic patterns from massive time-series data and provide accurate predictions. In this paper, a Periodicity-based Parallel Time Series Prediction (PPTSP) algorithm for large-scale time-series data is proposed and implemented in the Apache Spark cloud computing environment. To effectively handle the massive historical datasets, a Time Series Data Compression and Abstraction (TSDCA) algorithm is presented, which can reduce the data scale as well as accurately extracting the characteristics. Based on this, we propose a Multi-layer Time Series Periodic Pattern Recognition (MTSPPR) algorithm using the Fourier Spectrum Analysis (FSA) method. In addition, a Periodicity-based Time Series Prediction (PTSP) algorithm is proposed. Data in the subsequent period are predicted based on all previous period models, in which a time attenuation factor is introduced to control the impact of different periods on the prediction results. Moreover, to improve the performance of the proposed algorithms, we propose a parallel solution on the Apache Spark platform, using the Streaming real-time computing module. To efficiently process the large-scale time-series datasets in distributed computing environments, Distributed Streams (DStreams) and Resilient Distributed Datasets (RDDs) are used to store and calculate these datasets. Extensive experimental results show that our PPTSP algorithm has significant advantages compared with other algorithms in terms of prediction accuracy and performance.
A Disease Diagnosis and Treatment Recommendation System Based on Big Data Mining and Cloud Computing
Oct 17, 2018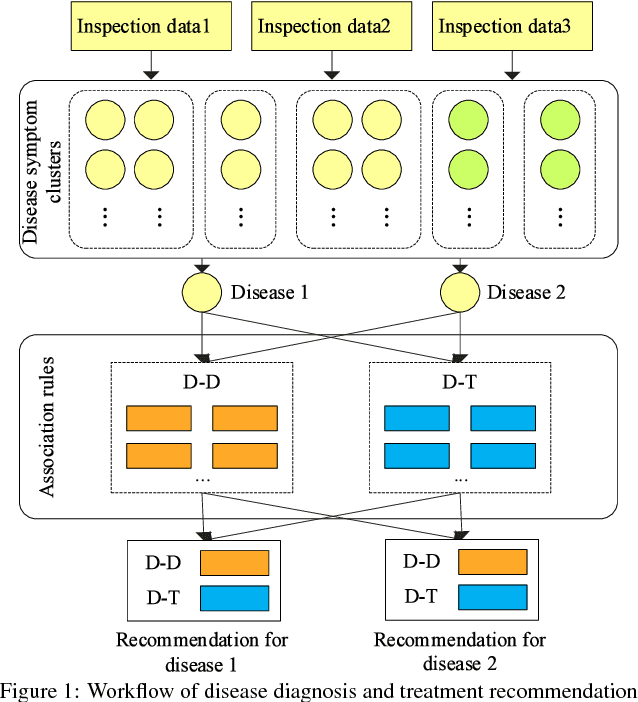
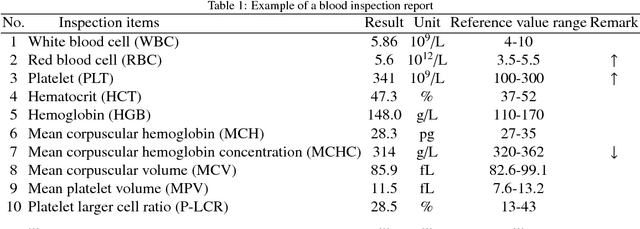

It is crucial to provide compatible treatment schemes for a disease according to various symptoms at different stages. However, most classification methods might be ineffective in accurately classifying a disease that holds the characteristics of multiple treatment stages, various symptoms, and multi-pathogenesis. Moreover, there are limited exchanges and cooperative actions in disease diagnoses and treatments between different departments and hospitals. Thus, when new diseases occur with atypical symptoms, inexperienced doctors might have difficulty in identifying them promptly and accurately. Therefore, to maximize the utilization of the advanced medical technology of developed hospitals and the rich medical knowledge of experienced doctors, a Disease Diagnosis and Treatment Recommendation System (DDTRS) is proposed in this paper. First, to effectively identify disease symptoms more accurately, a Density-Peaked Clustering Analysis (DPCA) algorithm is introduced for disease-symptom clustering. In addition, association analyses on Disease-Diagnosis (D-D) rules and Disease-Treatment (D-T) rules are conducted by the Apriori algorithm separately. The appropriate diagnosis and treatment schemes are recommended for patients and inexperienced doctors, even if they are in a limited therapeutic environment. Moreover, to reach the goals of high performance and low latency response, we implement a parallel solution for DDTRS using the Apache Spark cloud platform. Extensive experimental results demonstrate that the proposed DDTRS realizes disease-symptom clustering effectively and derives disease treatment recommendations intelligently and accurately.