 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of False-Reading Attacks in the AMI Net-Metering System
Dec 02, 2020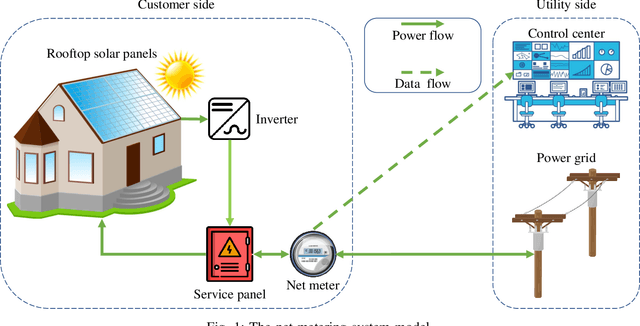
In smart grid, malicious customers may compromise their smart meters (SMs) to report false readings to achieve financial gains illegally. Reporting false readings not only causes hefty financial losses to the utility but may also degrade the grid performance because the reported readings are used for energy management. This paper is the first work that investigates this problem in the net-metering system, in which one SM is used to report the difference between the power consumed and the power generated. First, we prepare a benign dataset for the net-metering system by processing a real power consumption and generation dataset. Then, we propose a new set of attacks tailored for the net-metering system to create malicious dataset. After that, we analyze the data and we found time correlations between the net meter readings and correlations between the readings and relevant data obtained from trustworthy sources such as the solar irradiance and temperature. Based on the data analysis, we propose a general multi-data-source deep hybrid learning-based detector to identify the false-reading attacks. Our detector is trained on net meter readings of all customers besides data from the trustworthy sources to enhance the detector performance by learning the correlations between them. The rationale here is that although an attacker can report false readings, he cannot manipulate the solar irradiance and temperature values because they are beyond his control. Extensive experiments have been conducted, and the results indicate that our detector can identify the false-reading attacks with high detection rate and low false alarm.
Applying Machine Learning Techniques for Caching in Edge Networks: A Comprehensive Survey
Jun 21, 2020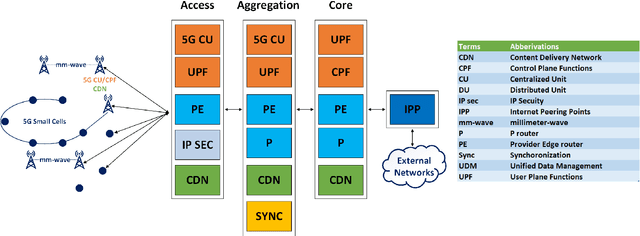
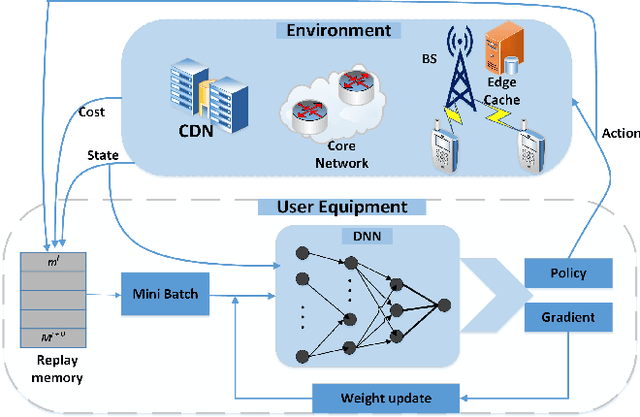
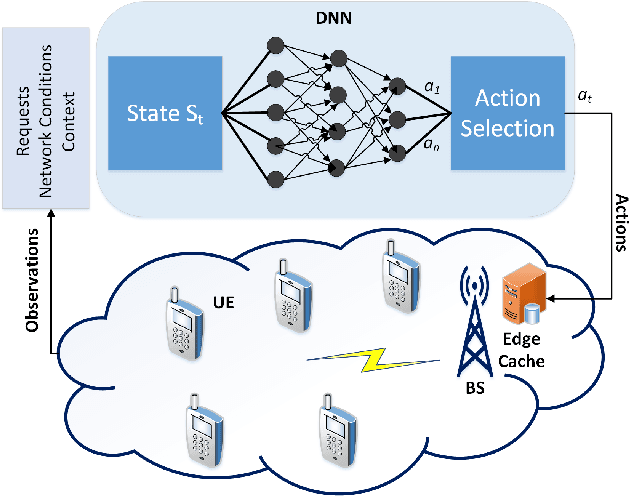
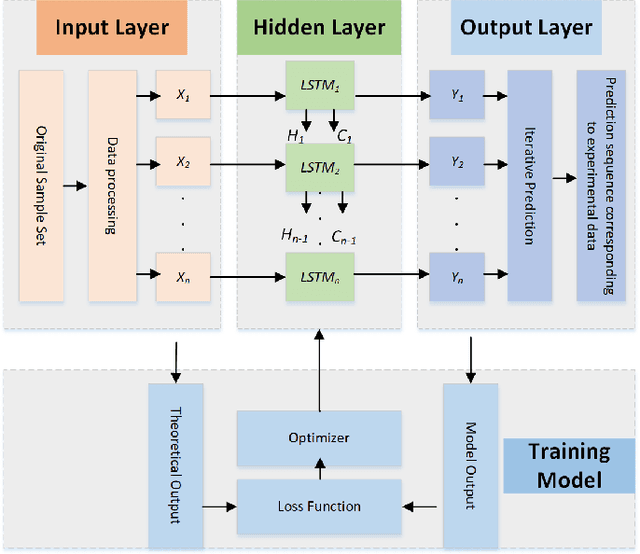
Edge networks provide access to a group of proximate users who may have similar content interests. Caching popular content at the edge networks leads to lower latencies while reducing the load on backhaul and core networks with the emergence of high-speed 5G networks. User mobility, preferences, and content popularity are the dominant dynamic features of the edge networks. Temporal and social features of content, such as the number of views and likes are applied to estimate the popularity of content from a global perspective. However, such estimates may not be mapped to an edge network with particular social and geographic characteristics. In edge networks, machine learning techniques can be applied to predict content popularity based on user preferences, user mobility based on user location history, cluster users based on similar content interests, and optimize cache placement strategies provided a set of constraints and predictions about the state of the network. These applications of machine learning can help identify relevant content for an edge network to lower latencies and increase cache hits. This article surveys the application of machine learning techniques for caching content in edge networks. We survey recent state-of-the-art literature and formulate a comprehensive taxonomy based on (a) machine learning technique, (b) caching strategy, and edge network. We further survey supporting concepts for optimal edge caching decisions that require the application of machine learning. These supporting concepts are social-awareness, popularity prediction, and community detection in edge networks. A comparative analysis of the state-of-the-art literature is presented with respect to the parameters identified in the taxonomy. Moreover, we debate research challenges and future directions for optimal caching decisions and the application of machine learning towards caching in edge networks.