 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-BRIGHT: A Multi-Task Multimodal Benchmark for Reasoning-Intensive Retrieval
Jan 15, 2026Existing retrieval benchmarks primarily consist of text-based queries where keyword or semantic matching is usually sufficient. Many real-world queries contain multimodal elements, particularly, images such as diagrams, charts, and screenshots that require intensive reasoning to identify relevant documents. To address this gap, we introduce MM-BRIGHT, the first multimodal benchmark for reasoning-intensive retrieval. Our dataset consists of 2,803 real-world queries spanning 29 diverse technical domains, with four tasks of increasing complexity: text-to-text, multimodal-to-text, multimodal-to-image, and multimodal-to-multimodal retrieval. Extensive evaluation reveals that state-of-the-art models struggle across all tasks: BM25 achieves only 8.5 nDCG@10 on text-only retrieval, while the best multimodal model Nomic-Vision reaches just 27.6 nDCG@10 on multimodal-to-text retrieval actually underperforming the best text-only model (DiVeR: 32.2). These results highlight substantial headroom and position MM-BRIGHT as a testbed for next-generation retrieval models that better integrate visual reasoning. Our code and data are available at https://github.com/mm-bright/MM-BRIGHT. See also our official website: https://mm-bright.github.io/.
CORU: Comprehensive Post-OCR Parsing and Receipt Understanding Dataset
Jun 06, 2024



In the fields of Optical Character Recognition (OCR) and Natural Language Processing (NLP), integrating multilingual capabilities remains a critical challenge, especially when considering languages with complex scripts such as Arabic. This paper introduces the Comprehensive Post-OCR Parsing and Receipt Understanding Dataset (CORU), a novel dataset specifically designed to enhance OCR and information extraction from receipts in multilingual contexts involving Arabic and English. CORU consists of over 20,000 annotated receipts from diverse retail settings, including supermarkets and clothing stores, alongside 30,000 annotated images for OCR that were utilized to recognize each detected line, and 10,000 items annotated for detailed information extraction. These annotations capture essential details such as merchant names, item descriptions, total prices, receipt numbers, and dates. They are structured to support three primary computational tasks: object detection, OCR, and information extraction. We establish the baseline performance for a range of models on CORU to evaluate the effectiveness of traditional methods, like Tesseract OCR, and more advanced neural network-based approaches. These baselines are crucial for processing the complex and noisy document layouts typical of real-world receipts and for advancing the state of automated multilingual document processing. Our datasets are publicly accessible (https://github.com/Update-For-Integrated-Business-AI/CORU).
A Comprehensive Survey of Masked Faces: Recognition, Detection, and Unmasking
May 09, 2024



Masked face recognition (MFR) has emerged as a critical domain in biometric identification, especially by the global COVID-19 pandemic, which introduced widespread face masks. This survey paper presents a comprehensive analysis of the challenges and advancements in recognising and detecting individuals with masked faces, which has seen innovative shifts due to the necessity of adapting to new societal norms. Advanced through deep learning techniques, MFR, along with Face Mask Recognition (FMR) and Face Unmasking (FU), represent significant areas of focus. These methods address unique challenges posed by obscured facial features, from fully to partially covered faces. Our comprehensive review delves into the various deep learning-based methodologies developed for MFR, FMR, and FU, highlighting their distinctive challenges and the solutions proposed to overcome them. Additionally, we explore benchmark datasets and evaluation metrics specifically tailored for assessing performance in MFR research. The survey also discusses the substantial obstacles still facing researchers in this field and proposes future directions for the ongoing development of more robust and effective masked face recognition systems. This paper serves as an invaluable resource for researchers and practitioners, offering insights into the evolving landscape of face recognition technologies in the face of global health crises and beyond.
ArabicaQA: A Comprehensive Dataset for Arabic Question Answering
Mar 26, 2024
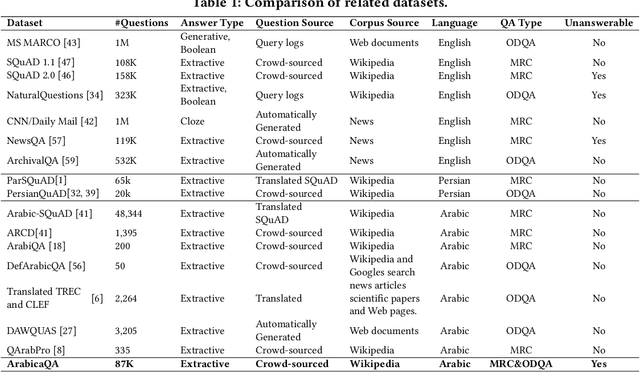

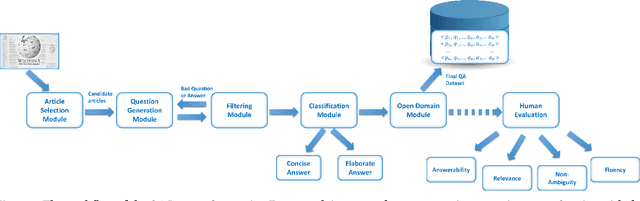
In this paper, we address the significant gap in Arabic natural language processing (NLP) resources by introducing ArabicaQA, the first large-scale dataset for machine reading comprehension and open-domain question answering in Arabic. This comprehensive dataset, consisting of 89,095 answerable and 3,701 unanswerable questions created by crowdworkers to look similar to answerable ones, along with additional labels of open-domain questions marks a crucial advancement in Arabic NLP resources. We also present AraDPR, the first dense passage retrieval model trained on the Arabic Wikipedia corpus, specifically designed to tackle the unique challenges of Arabic text retrieval. Furthermore, our study includes extensive benchmarking of large language models (LLMs) for Arabic question answering, critically evaluating their performance in the Arabic language context. In conclusion, ArabicaQA, AraDPR, and the benchmarking of LLMs in Arabic question answering offer significant advancements in the field of Arabic NLP. The dataset and code are publicly accessible for further research https://github.com/DataScienceUIBK/ArabicaQA.
Advancements and Challenges in Arabic Optical Character Recognition: A Comprehensive Survey
Dec 19, 2023Optical character recognition (OCR) is a vital process that involves the extraction of handwritten or printed text from scanned or printed images, converting it into a format that can be understood and processed by machines. This enables further data processing activities such as searching and editing. The automatic extraction of text through OCR plays a crucial role in digitizing documents, enhancing productivity, improving accessibility, and preserving historical records. This paper seeks to offer an exhaustive review of contemporary applications, methodologies, and challenges associated with Arabic Optical Character Recognition (OCR). A thorough analysis is conducted on prevailing techniques utilized throughout the OCR process, with a dedicated effort to discern the most efficacious approaches that demonstrate enhanced outcomes. To ensure a thorough evaluation, a meticulous keyword-search methodology is adopted, encompassing a comprehensive analysis of articles relevant to Arabic OCR, including both backward and forward citation reviews. In addition to presenting cutting-edge techniques and methods, this paper critically identifies research gaps within the realm of Arabic OCR. By highlighting these gaps, we shed light on potential areas for future exploration and development, thereby guiding researchers toward promising avenues in the field of Arabic OCR. The outcomes of this study provide valuable insights for researchers, practitioners, and stakeholders involved in Arabic OCR, ultimately fostering advancements in the field and facilitating the creation of more accurate and efficient OCR systems for the Arabic language.
Deep learning for table detection and structure recognition: A survey
Nov 15, 2022
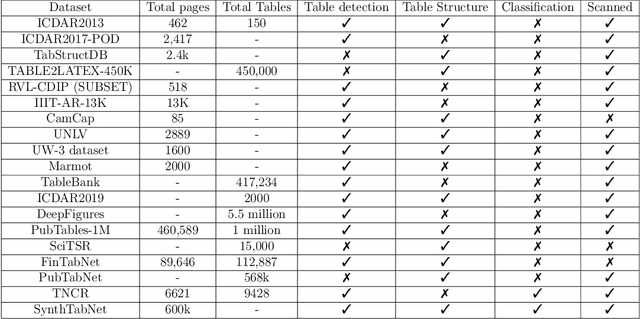
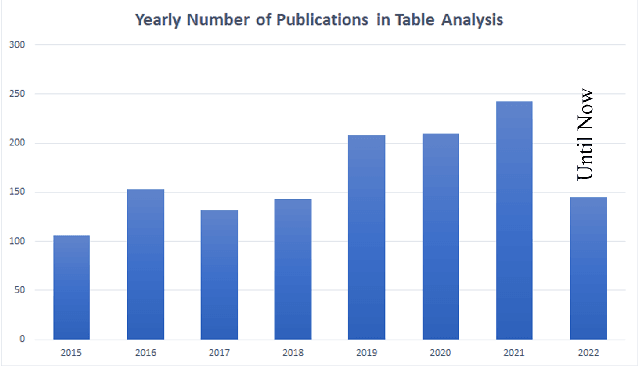

Tables are everywhere, from scientific journals, papers, websites, and newspapers all the way to items we buy at the supermarket. Detecting them is thus of utmost importance to automatically understanding the content of a document. The performance of table detection has substantially increased thanks to the rapid development of deep learning networks. The goals of this survey are to provide a profound comprehension of the major developments in the field of Table Detection, offer insight into the different methodologies, and provide a systematic taxonomy of the different approaches. Furthermore, we provide an analysis of both classic and new applications in the field. Lastly, the datasets and source code of the existing models are organized to provide the reader with a compass on this vast literature. Finally, we go over the architecture of utilizing various object detection and table structure recognition methods to create an effective and efficient system, as well as a set of development trends to keep up with state-of-the-art algorithms and future research. We have also set up a public GitHub repository where we will be updating the most recent publications, open data, and source code. The GitHub repository is available at https://github.com/abdoelsayed2016/table-detection-structure-recognition.
Detection of False-Reading Attacks in the AMI Net-Metering System
Dec 02, 2020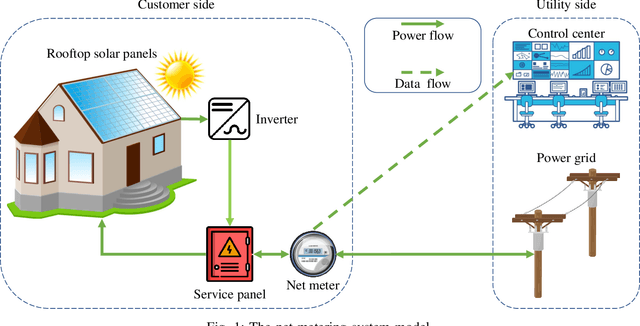
In smart grid, malicious customers may compromise their smart meters (SMs) to report false readings to achieve financial gains illegally. Reporting false readings not only causes hefty financial losses to the utility but may also degrade the grid performance because the reported readings are used for energy management. This paper is the first work that investigates this problem in the net-metering system, in which one SM is used to report the difference between the power consumed and the power generated. First, we prepare a benign dataset for the net-metering system by processing a real power consumption and generation dataset. Then, we propose a new set of attacks tailored for the net-metering system to create malicious dataset. After that, we analyze the data and we found time correlations between the net meter readings and correlations between the readings and relevant data obtained from trustworthy sources such as the solar irradiance and temperature. Based on the data analysis, we propose a general multi-data-source deep hybrid learning-based detector to identify the false-reading attacks. Our detector is trained on net meter readings of all customers besides data from the trustworthy sources to enhance the detector performance by learning the correlations between them. The rationale here is that although an attacker can report false readings, he cannot manipulate the solar irradiance and temperature values because they are beyond his control. Extensive experiments have been conducted, and the results indicate that our detector can identify the false-reading attacks with high detection rate and low false alarm.
On Sharing Models Instead of Data using Mimic learning for Smart Health Applications
Dec 24, 2019

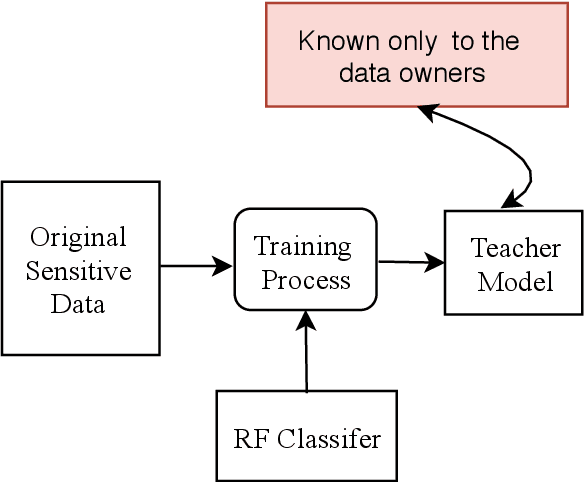
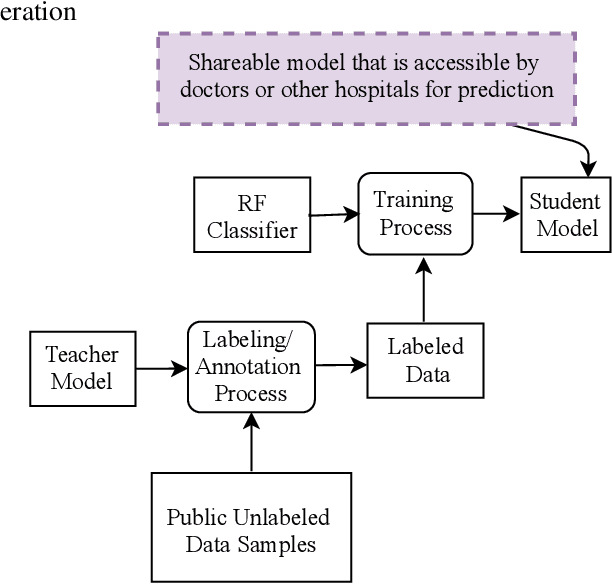
Electronic health records (EHR) systems contain vast amounts of medical information about patients. These data can be used to train machine learning models that can predict health status, as well as to help prevent future diseases or disabilities. However, getting patients' medical data to obtain well-trained machine learning models is a challenging task. This is because sharing the patients' medical records is prohibited by law in most countries due to patients privacy concerns. In this paper, we tackle this problem by sharing the models instead of the original sensitive data by using the mimic learning approach. The idea is first to train a model on the original sensitive data, called the teacher model. Then, using this model, we can transfer its knowledge to another model, called the student model, without the need to learn the original data used in training the teacher model. The student model is then shared to the public and can be used to make accurate predictions. To assess the mimic learning approach, we have evaluated our scheme using different medical datasets. The results indicate that the student model mimics the teacher model performance in terms of prediction accuracy without the need to access to the patients' original data records.
Mimic Learning to Generate a Shareable Network Intrusion Detection Model
May 02, 2019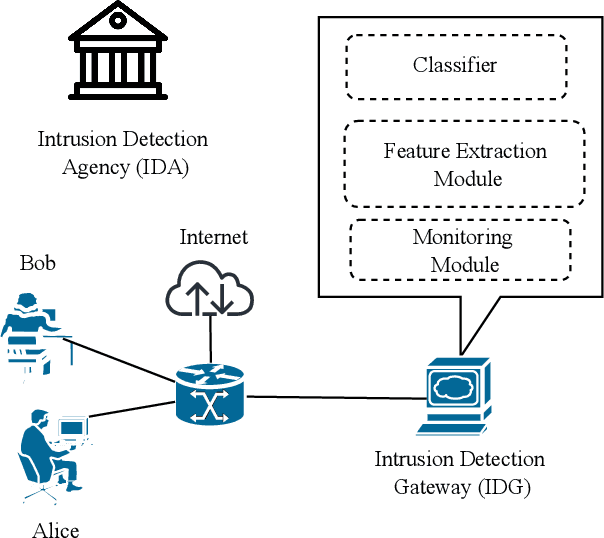
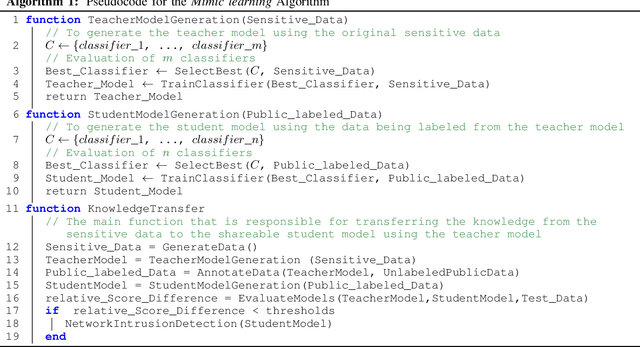
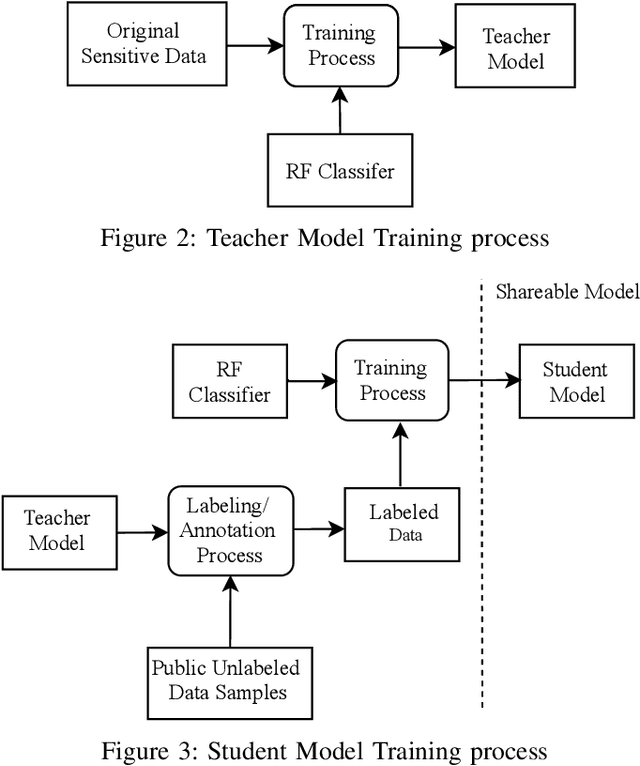
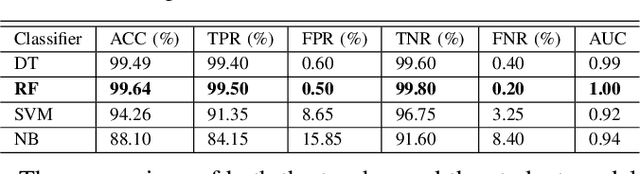
Purveyors of malicious network attacks continue to increase the complexity and the sophistication of their techniques, and their ability to evade detection continues to improve as well. Hence, intrusion detection systems must also evolve to meet these increasingly challenging threats. Machine learning is often used to support this needed improvement. However, training a good prediction model can require a large set of labelled training data. Such datasets are difficult to obtain because privacy concerns prevent the majority of intrusion detection agencies from sharing their sensitive data. In this paper, we propose the use of mimic learning to enable the transfer of intrusion detection knowledge through a teacher model trained on private data to a student model. This student model provides a mean of publicly sharing knowledge extracted from private data without sharing the data itself. Our results confirm that the proposed scheme can produce a student intrusion detection model that mimics the teacher model without requiring access to the original dataset.
Deep Recurrent Electricity Theft Detection in AMI Networks with Random Tuning of Hyper-parameters
Sep 06, 2018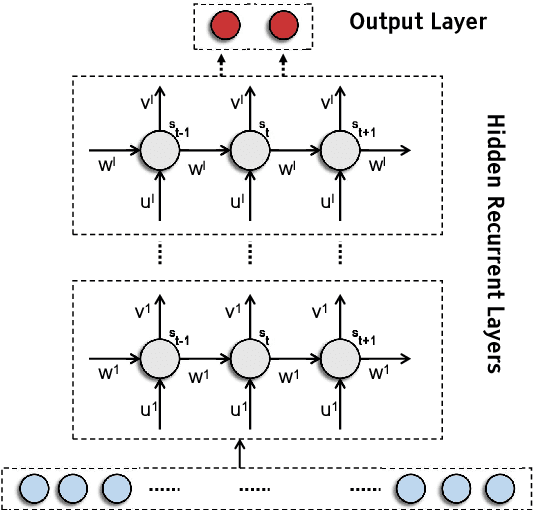

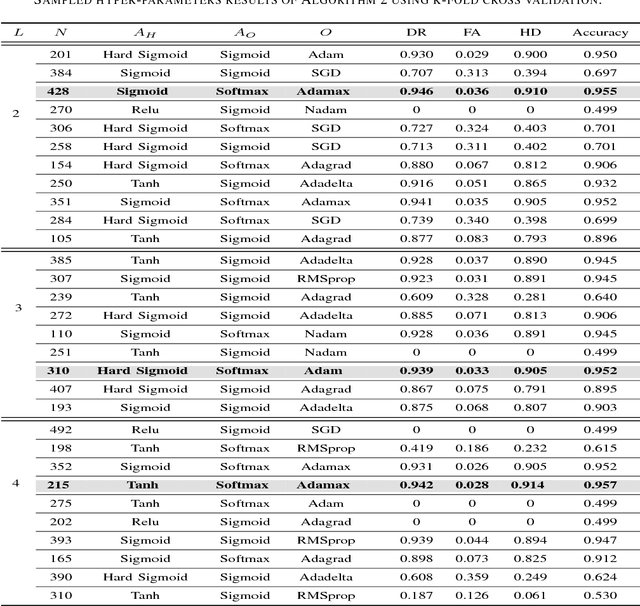
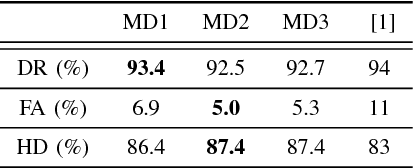
Modern smart grids rely on advanced metering infrastructure (AMI) networks for monitoring and billing purposes. However, such an approach suffers from electricity theft cyberattacks. Different from the existing research that utilizes shallow, static, and customer-specific-based electricity theft detectors, this paper proposes a generalized deep recurrent neural network (RNN)-based electricity theft detector that can effectively thwart these cyberattacks. The proposed model exploits the time series nature of the customers' electricity consumption to implement a gated recurrent unit (GRU)-RNN, hence, improving the detection performance. In addition, the proposed RNN-based detector adopts a random search analysis in its learning stage to appropriately fine-tune its hyper-parameters. Extensive test studies are carried out to investigate the detector's performance using publicly available real data of 107,200 energy consumption days from 200 customers. Simulation results demonstrate the superior performance of the proposed detector compared with state-of-the-art electricity theft detectors.