 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabicaQA: A Comprehensive Dataset for Arabic Question Answering
Mar 26, 2024
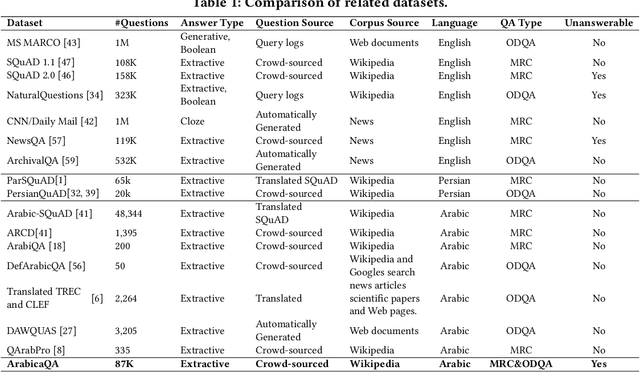

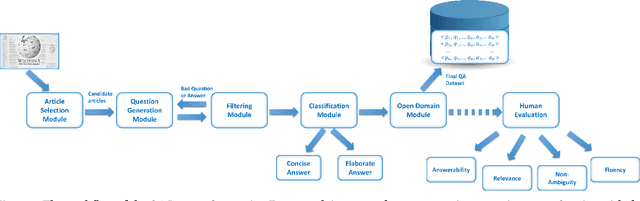
In this paper, we address the significant gap in Arabic natural language processing (NLP) resources by introducing ArabicaQA, the first large-scale dataset for machine reading comprehension and open-domain question answering in Arabic. This comprehensive dataset, consisting of 89,095 answerable and 3,701 unanswerable questions created by crowdworkers to look similar to answerable ones, along with additional labels of open-domain questions marks a crucial advancement in Arabic NLP resources. We also present AraDPR, the first dense passage retrieval model trained on the Arabic Wikipedia corpus, specifically designed to tackle the unique challenges of Arabic text retrieval. Furthermore, our study includes extensive benchmarking of large language models (LLMs) for Arabic question answering, critically evaluating their performance in the Arabic language context. In conclusion, ArabicaQA, AraDPR, and the benchmarking of LLMs in Arabic question answering offer significant advancements in the field of Arabic NLP. The dataset and code are publicly accessible for further research https://github.com/DataScienceUIBK/ArabicaQA.
AMuRD: Annotated Multilingual Receipts Dataset for Cross-lingual Key Information Extraction and Classification
Sep 18, 2023Key information extraction involves recognizing and extracting text from scanned receipts, enabling retrieval of essential content, and organizing it into structured documents. This paper presents a novel multilingual dataset for receipt extraction, addressing key challenges in information extraction and item classification. The dataset comprises $47,720$ samples, including annotations for item names, attributes like (price, brand, etc.), and classification into $44$ product categories. We introduce the InstructLLaMA approach, achieving an F1 score of $0.76$ and an accuracy of $0.68$ for key information extraction and item classification. We provide code, datasets, and checkpoints.\footnote{\url{https://github.com/Update-For-Integrated-Business-AI/AMuRD}}.