 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-BRIGHT: A Multi-Task Multimodal Benchmark for Reasoning-Intensive Retrieval
Jan 15, 2026Existing retrieval benchmarks primarily consist of text-based queries where keyword or semantic matching is usually sufficient. Many real-world queries contain multimodal elements, particularly, images such as diagrams, charts, and screenshots that require intensive reasoning to identify relevant documents. To address this gap, we introduce MM-BRIGHT, the first multimodal benchmark for reasoning-intensive retrieval. Our dataset consists of 2,803 real-world queries spanning 29 diverse technical domains, with four tasks of increasing complexity: text-to-text, multimodal-to-text, multimodal-to-image, and multimodal-to-multimodal retrieval. Extensive evaluation reveals that state-of-the-art models struggle across all tasks: BM25 achieves only 8.5 nDCG@10 on text-only retrieval, while the best multimodal model Nomic-Vision reaches just 27.6 nDCG@10 on multimodal-to-text retrieval actually underperforming the best text-only model (DiVeR: 32.2). These results highlight substantial headroom and position MM-BRIGHT as a testbed for next-generation retrieval models that better integrate visual reasoning. Our code and data are available at https://github.com/mm-bright/MM-BRIGHT. See also our official website: https://mm-bright.github.io/.
RankArena: A Unified Platform for Evaluating Retrieval, Reranking and RAG with Human and LLM Feedback
Aug 07, 2025Evaluating the quality of retrieval-augmented generation (RAG) and document reranking systems remains challenging due to the lack of scalable, user-centric, and multi-perspective evaluation tools. We introduce RankArena, a unified platform for comparing and analysing the performance of retrieval pipelines, rerankers, and RAG systems using structured human and LLM-based feedback as well as for collecting such feedback. RankArena supports multiple evaluation modes: direct reranking visualisation, blind pairwise comparisons with human or LLM voting, supervised manual document annotation, and end-to-end RAG answer quality assessment. It captures fine-grained relevance feedback through both pairwise preferences and full-list annotations, along with auxiliary metadata such as movement metrics, annotation time, and quality ratings. The platform also integrates LLM-as-a-judge evaluation, enabling comparison between model-generated rankings and human ground truth annotations. All interactions are stored as structured evaluation datasets that can be used to train rerankers, reward models, judgment agents, or retrieval strategy selectors. Our platform is publicly available at https://rankarena.ngrok.io/, and the Demo video is provided https://youtu.be/jIYAP4PaSSI.
CORU: Comprehensive Post-OCR Parsing and Receipt Understanding Dataset
Jun 06, 2024



In the fields of Optical Character Recognition (OCR) and Natural Language Processing (NLP), integrating multilingual capabilities remains a critical challenge, especially when considering languages with complex scripts such as Arabic. This paper introduces the Comprehensive Post-OCR Parsing and Receipt Understanding Dataset (CORU), a novel dataset specifically designed to enhance OCR and information extraction from receipts in multilingual contexts involving Arabic and English. CORU consists of over 20,000 annotated receipts from diverse retail settings, including supermarkets and clothing stores, alongside 30,000 annotated images for OCR that were utilized to recognize each detected line, and 10,000 items annotated for detailed information extraction. These annotations capture essential details such as merchant names, item descriptions, total prices, receipt numbers, and dates. They are structured to support three primary computational tasks: object detection, OCR, and information extraction. We establish the baseline performance for a range of models on CORU to evaluate the effectiveness of traditional methods, like Tesseract OCR, and more advanced neural network-based approaches. These baselines are crucial for processing the complex and noisy document layouts typical of real-world receipts and for advancing the state of automated multilingual document processing. Our datasets are publicly accessible (https://github.com/Update-For-Integrated-Business-AI/CORU).
ArabicaQA: A Comprehensive Dataset for Arabic Question Answering
Mar 26, 2024
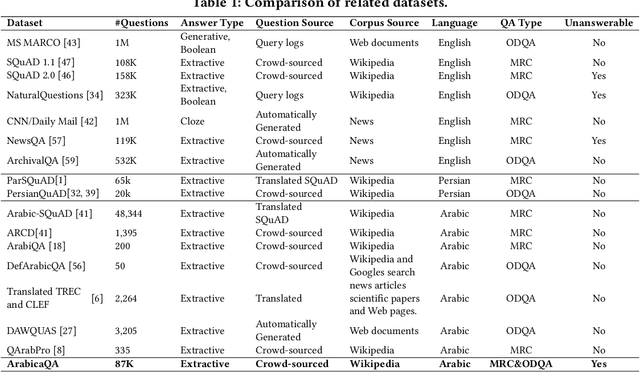

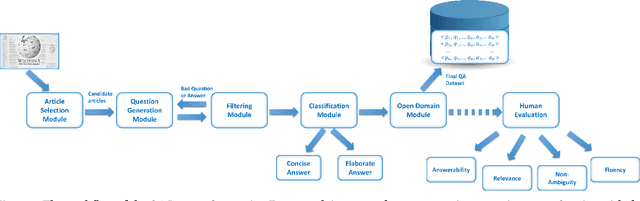
In this paper, we address the significant gap in Arabic natural language processing (NLP) resources by introducing ArabicaQA, the first large-scale dataset for machine reading comprehension and open-domain question answering in Arabic. This comprehensive dataset, consisting of 89,095 answerable and 3,701 unanswerable questions created by crowdworkers to look similar to answerable ones, along with additional labels of open-domain questions marks a crucial advancement in Arabic NLP resources. We also present AraDPR, the first dense passage retrieval model trained on the Arabic Wikipedia corpus, specifically designed to tackle the unique challenges of Arabic text retrieval. Furthermore, our study includes extensive benchmarking of large language models (LLMs) for Arabic question answering, critically evaluating their performance in the Arabic language context. In conclusion, ArabicaQA, AraDPR, and the benchmarking of LLMs in Arabic question answering offer significant advancements in the field of Arabic NLP. The dataset and code are publicly accessible for further research https://github.com/DataScienceUIBK/ArabicaQA.
AMuRD: Annotated Multilingual Receipts Dataset for Cross-lingual Key Information Extraction and Classification
Sep 18, 2023Key information extraction involves recognizing and extracting text from scanned receipts, enabling retrieval of essential content, and organizing it into structured documents. This paper presents a novel multilingual dataset for receipt extraction, addressing key challenges in information extraction and item classification. The dataset comprises $47,720$ samples, including annotations for item names, attributes like (price, brand, etc.), and classification into $44$ product categories. We introduce the InstructLLaMA approach, achieving an F1 score of $0.76$ and an accuracy of $0.68$ for key information extraction and item classification. We provide code, datasets, and checkpoints.\footnote{\url{https://github.com/Update-For-Integrated-Business-AI/AMuRD}}.
Deep learning for table detection and structure recognition: A survey
Nov 15, 2022
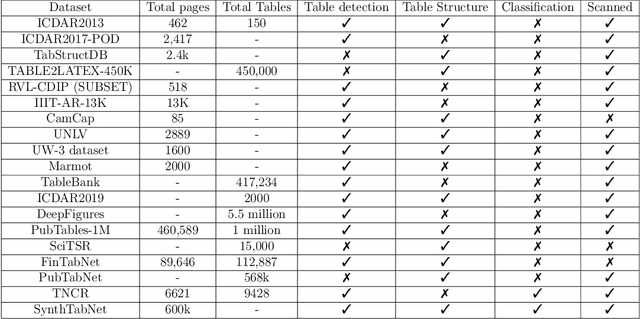
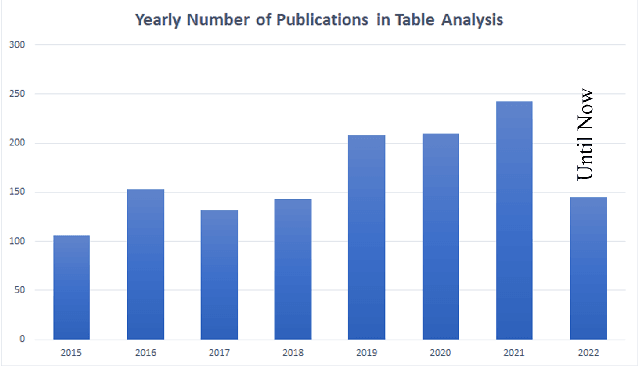

Tables are everywhere, from scientific journals, papers, websites, and newspapers all the way to items we buy at the supermarket. Detecting them is thus of utmost importance to automatically understanding the content of a document. The performance of table detection has substantially increased thanks to the rapid development of deep learning networks. The goals of this survey are to provide a profound comprehension of the major developments in the field of Table Detection, offer insight into the different methodologies, and provide a systematic taxonomy of the different approaches. Furthermore, we provide an analysis of both classic and new applications in the field. Lastly, the datasets and source code of the existing models are organized to provide the reader with a compass on this vast literature. Finally, we go over the architecture of utilizing various object detection and table structure recognition methods to create an effective and efficient system, as well as a set of development trends to keep up with state-of-the-art algorithms and future research. We have also set up a public GitHub repository where we will be updating the most recent publications, open data, and source code. The GitHub repository is available at https://github.com/abdoelsayed2016/table-detection-structure-recognition.