 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabicaQA: A Comprehensive Dataset for Arabic Question Answering
Mar 26, 2024
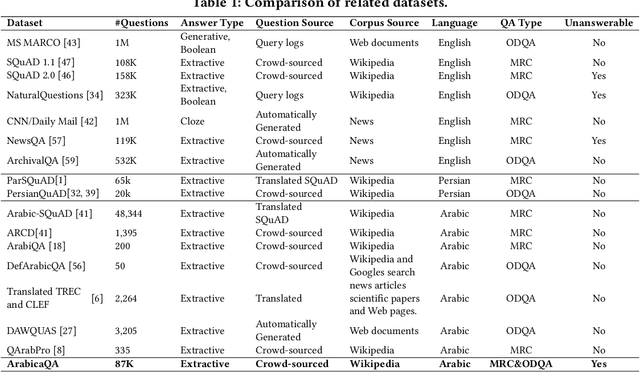

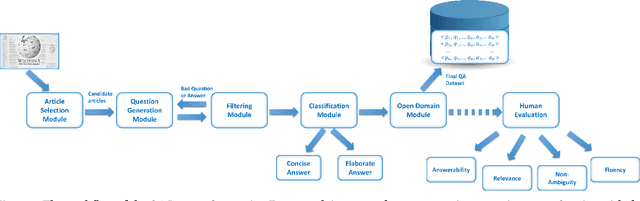
In this paper, we address the significant gap in Arabic natural language processing (NLP) resources by introducing ArabicaQA, the first large-scale dataset for machine reading comprehension and open-domain question answering in Arabic. This comprehensive dataset, consisting of 89,095 answerable and 3,701 unanswerable questions created by crowdworkers to look similar to answerable ones, along with additional labels of open-domain questions marks a crucial advancement in Arabic NLP resources. We also present AraDPR, the first dense passage retrieval model trained on the Arabic Wikipedia corpus, specifically designed to tackle the unique challenges of Arabic text retrieval. Furthermore, our study includes extensive benchmarking of large language models (LLMs) for Arabic question answering, critically evaluating their performance in the Arabic language context. In conclusion, ArabicaQA, AraDPR, and the benchmarking of LLMs in Arabic question answering offer significant advancements in the field of Arabic NLP. The dataset and code are publicly accessible for further research https://github.com/DataScienceUIBK/ArabicaQA.
Deep learning for table detection and structure recognition: A survey
Nov 15, 2022
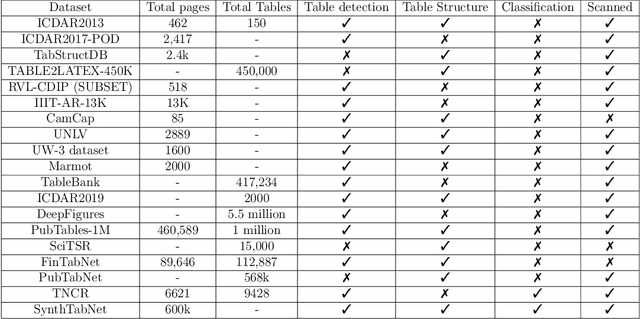
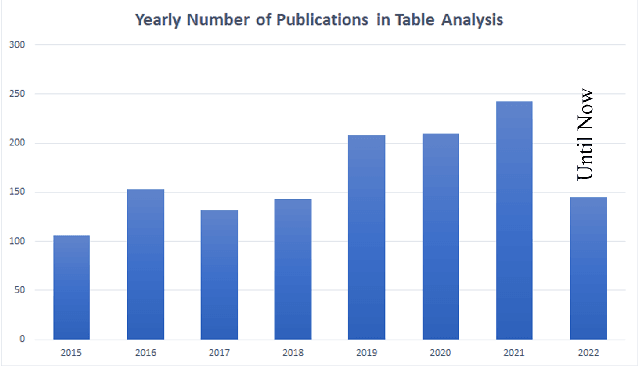

Tables are everywhere, from scientific journals, papers, websites, and newspapers all the way to items we buy at the supermarket. Detecting them is thus of utmost importance to automatically understanding the content of a document. The performance of table detection has substantially increased thanks to the rapid development of deep learning networks. The goals of this survey are to provide a profound comprehension of the major developments in the field of Table Detection, offer insight into the different methodologies, and provide a systematic taxonomy of the different approaches. Furthermore, we provide an analysis of both classic and new applications in the field. Lastly, the datasets and source code of the existing models are organized to provide the reader with a compass on this vast literature. Finally, we go over the architecture of utilizing various object detection and table structure recognition methods to create an effective and efficient system, as well as a set of development trends to keep up with state-of-the-art algorithms and future research. We have also set up a public GitHub repository where we will be updating the most recent publications, open data, and source code. The GitHub repository is available at https://github.com/abdoelsayed2016/table-detection-structure-recognition.
KOHTD: Kazakh Offline Handwritten Text Dataset
Sep 22, 2021


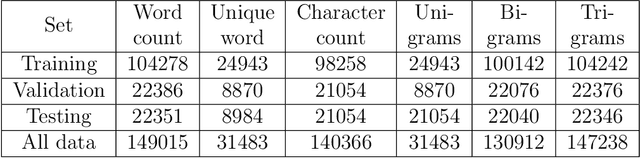
Despite the transition to digital information exchange, many documents, such as invoices, taxes, memos and questionnaires, historical data, and answers to exam questions, still require handwritten inputs. In this regard, there is a need to implement Handwritten Text Recognition (HTR) which is an automatic way to decrypt records using a computer. Handwriting recognition is challenging because of the virtually infinite number of ways a person can write the same message. For this proposal we introduce Kazakh handwritten text recognition research, a comprehensive dataset of Kazakh handwritten texts is necessary. This is particularly true given the lack of a dataset for handwritten Kazakh text. In this paper, we proposed our extensive Kazakh offline Handwritten Text dataset (KOHTD), which has 3000 handwritten exam papers and more than 140335 segmented images and there are approximately 922010 symbols. It can serve researchers in the field of handwriting recognition tasks by using deep and machine learning. We used a variety of popular text recognition methods for word and line recognition in our studies, including CTC-based and attention-based methods. The findings demonstrate KOHTD's diversity. Also, we proposed a Genetic Algorithm (GA) for line and word segmentation based on random enumeration of a parameter. The dataset and GA code are available at https://github.com/abdoelsayed2016/KOHTD.
Automated Question Answer medical model based on Deep Learning Technology
May 21, 2020


Artificial intelligence can now provide more solutions for different problems, especially in the medical field. One of those problems the lack of answers to any given medical/health-related question. The Internet is full of forums that allow people to ask some specific questions and get great answers for them. Nevertheless, browsing these questions in order to locate one similar to your own, also finding a satisfactory answer is a difficult and time-consuming task. This research will introduce a solution to this problem by automating the process of generating qualified answers to these questions and creating a kind of digital doctor. Furthermore, this research will train an end-to-end model using the framework of RNN and the encoder-decoder to generate sensible and useful answers to a small set of medical/health issues. The proposed model was trained and evaluated using data from various online services, such as WebMD, HealthTap, eHealthForums, and iCliniq.