 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of machine learning methods to detect and classify Core images using GAN and texture recognition
Apr 21, 2022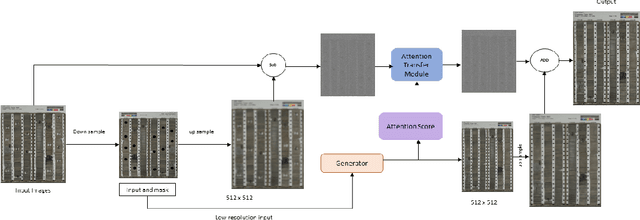

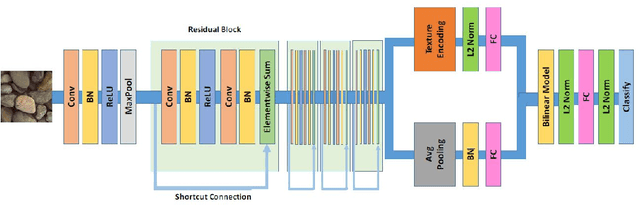
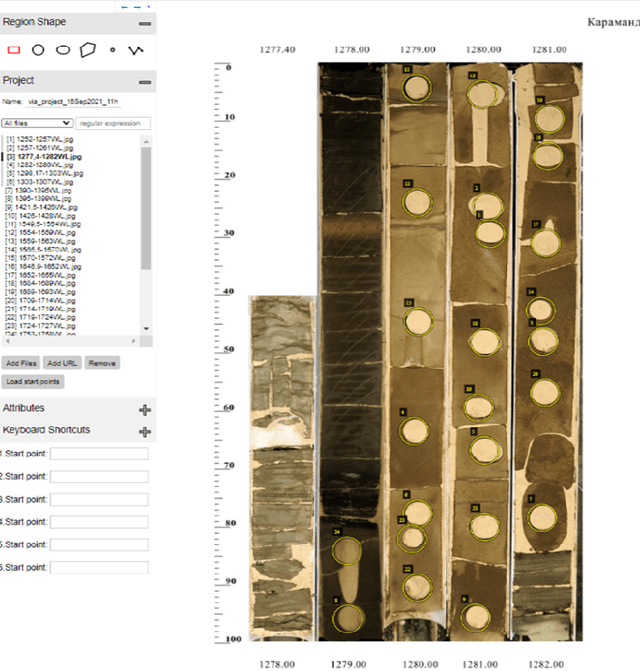
During exploration campaigns, oil companies rely heavily on drill core samples as they provide valuable geological information that helps them find important oil deposits. Traditional core logging techniques are laborious and subjective. Core imaging, a new technique in the oil industry, is used to supplement analysis by rapidly characterising large quantities of drill cores in a nondestructive and noninvasive manner. In this paper, we will present the problem of core detection and classification. The first problem is detecting the cores and segmenting the holes in images by using Faster RCNN and Mask RCNN models respectively. The second problem is filling the hole in the core image by applying the Generative adversarial network(GAN) technique and using Contextual Residual Aggregation(CRA) which creates high frequency residual for missing contents in images. And finally applying Texture recognition models for the classification of core images.
KOHTD: Kazakh Offline Handwritten Text Dataset
Sep 22, 2021


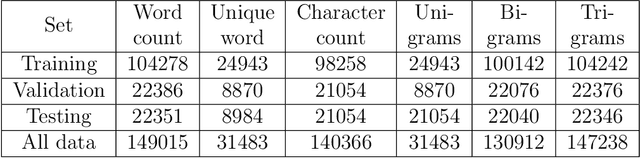
Despite the transition to digital information exchange, many documents, such as invoices, taxes, memos and questionnaires, historical data, and answers to exam questions, still require handwritten inputs. In this regard, there is a need to implement Handwritten Text Recognition (HTR) which is an automatic way to decrypt records using a computer. Handwriting recognition is challenging because of the virtually infinite number of ways a person can write the same message. For this proposal we introduce Kazakh handwritten text recognition research, a comprehensive dataset of Kazakh handwritten texts is necessary. This is particularly true given the lack of a dataset for handwritten Kazakh text. In this paper, we proposed our extensive Kazakh offline Handwritten Text dataset (KOHTD), which has 3000 handwritten exam papers and more than 140335 segmented images and there are approximately 922010 symbols. It can serve researchers in the field of handwriting recognition tasks by using deep and machine learning. We used a variety of popular text recognition methods for word and line recognition in our studies, including CTC-based and attention-based methods. The findings demonstrate KOHTD's diversity. Also, we proposed a Genetic Algorithm (GA) for line and word segmentation based on random enumeration of a parameter. The dataset and GA code are available at https://github.com/abdoelsayed2016/KOHTD.
Classification of Handwritten Names of Cities and Handwritten Text Recognition using Various Deep Learning Models
Feb 09, 2021
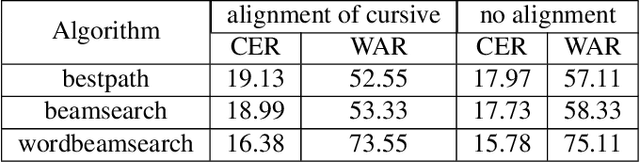


This article discusses the problem of handwriting recognition in Kazakh and Russian languages. This area is poorly studied since in the literature there are almost no works in this direction. We have tried to describe various approaches and achievements of recent years in the development of handwritten recognition models in relation to Cyrillic graphics. The first model uses deep convolutional neural networks (CNNs) for feature extraction and a fully connected multilayer perceptron neural network (MLP) for word classification. The second model, called SimpleHTR, uses CNN and recurrent neural network (RNN) layers to extract information from images. We also proposed the Bluechet and Puchserver models to compare the results. Due to the lack of available open datasets in Russian and Kazakh languages, we carried out work to collect data that included handwritten names of countries and cities from 42 different Cyrillic words, written more than 500 times in different handwriting. We also used a handwritten database of Kazakh and Russian languages (HKR). This is a new database of Cyrillic words (not only countries and cities) for the Russian and Kazakh languages, created by the authors of this work.
HKR For Handwritten Kazakh & Russian Database
Jul 08, 2020


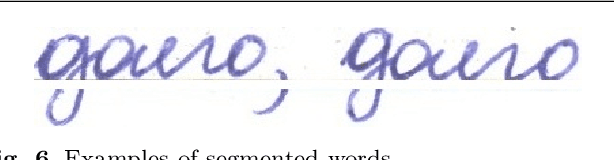
In this paper, we present a new Russian and Kazakh database (with about 95% of Russian and 5% of Kazakh words/sentences respectively) for offline handwriting recognition. A few pre-processing and segmentation procedures have been developed together with the database. The database is written in Cyrillic and shares the same 33 characters. Besides these characters, the Kazakh alphabet also contains 9 additional specific characters. This dataset is a collection of forms. The sources of all the forms in the datasets were generated by \LaTeX which subsequently was filled out by persons with their handwriting. The database consists of more than 1400 filled forms. There are approximately 63000 sentences, more than 715699 symbols produced by approximately 200 different writers. It can serve researchers in the field of handwriting recognition tasks by using deep and machine learning.