 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Handwritten Names of Cities and Handwritten Text Recognition using Various Deep Learning Models
Feb 09, 2021
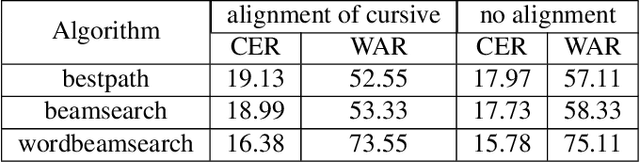


This article discusses the problem of handwriting recognition in Kazakh and Russian languages. This area is poorly studied since in the literature there are almost no works in this direction. We have tried to describe various approaches and achievements of recent years in the development of handwritten recognition models in relation to Cyrillic graphics. The first model uses deep convolutional neural networks (CNNs) for feature extraction and a fully connected multilayer perceptron neural network (MLP) for word classification. The second model, called SimpleHTR, uses CNN and recurrent neural network (RNN) layers to extract information from images. We also proposed the Bluechet and Puchserver models to compare the results. Due to the lack of available open datasets in Russian and Kazakh languages, we carried out work to collect data that included handwritten names of countries and cities from 42 different Cyrillic words, written more than 500 times in different handwriting. We also used a handwritten database of Kazakh and Russian languages (HKR). This is a new database of Cyrillic words (not only countries and cities) for the Russian and Kazakh languages, created by the authors of this work.