 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKOHTD: Kazakh Offline Handwritten Text Dataset
Sep 22, 2021


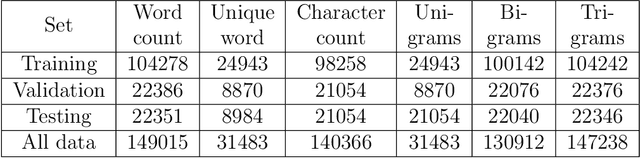
Despite the transition to digital information exchange, many documents, such as invoices, taxes, memos and questionnaires, historical data, and answers to exam questions, still require handwritten inputs. In this regard, there is a need to implement Handwritten Text Recognition (HTR) which is an automatic way to decrypt records using a computer. Handwriting recognition is challenging because of the virtually infinite number of ways a person can write the same message. For this proposal we introduce Kazakh handwritten text recognition research, a comprehensive dataset of Kazakh handwritten texts is necessary. This is particularly true given the lack of a dataset for handwritten Kazakh text. In this paper, we proposed our extensive Kazakh offline Handwritten Text dataset (KOHTD), which has 3000 handwritten exam papers and more than 140335 segmented images and there are approximately 922010 symbols. It can serve researchers in the field of handwriting recognition tasks by using deep and machine learning. We used a variety of popular text recognition methods for word and line recognition in our studies, including CTC-based and attention-based methods. The findings demonstrate KOHTD's diversity. Also, we proposed a Genetic Algorithm (GA) for line and word segmentation based on random enumeration of a parameter. The dataset and GA code are available at https://github.com/abdoelsayed2016/KOHTD.